2202年了,AI还是不如猫,图灵奖得主Yann LeCun:3大挑战依然无解
2018年,Yann LeCun:人工智能缺乏对世界的基本认识,甚至还不如家猫认知水平。
2022年,Yann LeCun:人工智能依然没有达到猫的水平。

最近,LeCun在Lex Fridman的采访中表示,尽管只有8亿个神经元,但猫的大脑远远领先于任何大型人工神经网络。
猫和人类的共同基础是对世界高度发达的理解,基于对环境的抽象表征,形成模型,例如,预测行为和后果。
对于人工智能来说,学习这种环境模型的能力就非常关键了。
此前,LeCun也曾表示过,「在我职业生涯结束前,如果AI能够达到狗或者牛一样的智商,那我已经十分欣慰了」。
人工智能研究的三大挑战
人工智能必须学会世界的表征
人工智能必须学会以与基于梯度的学习兼容的方式进行思考和规划
人工智能必须学习行动规划的分层表征
LeCun认为第一个挑战的解决方案是自监督学习。
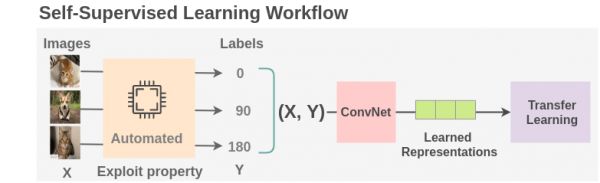
语言模型或图像分析系统的成功表明,人工智能有能力创建复杂的世界模型。
就比如Meta AI在前段时间推出的第一个适用于多种模态的高性能自监督算法——data2vec。
它可分别应用于语音、图像和文本,它的性能超过了以前最好的计算机视觉和语音的单一用途算法,而且在NLP任务上也具有竞争力。
data2vec的提出代表了一种新的整体自监督学习范式,不仅改进了模型在多种模态下的表现,同时也不依赖于对比性学习或重建输入实例。
为此,LeCun也发文表示祝贺:「data2vec在ImageNet(视觉)、LibriSpeech(语音识别)和GLU(NLP)上的结果均优于现有SOTA。」

然而,下一代人工智能将不再使用语言或图像,而是直接从视频中学习。
想象一下,你的增强现实设备准确地显示了如何在鼓课上握住木棒,指导你完成一个食谱,帮助你找到丢失的钥匙,或者像全息图一样浮现出你的记忆。
为了实现这些新技术,人工智能需要像我们一样,从第一人称的角度理解世界并与它互动,这在研究界,通常被称为以第一人称为中心的视觉感知。

然而,今天的计算机视觉(CV)系统从数以百万计的照片和视频中学习,尽管发展飞速,有了喜人的研究进展,可这些照片和视频都是以第三人称视角拍摄的,相机的视角只是一个行动的旁观者视角。
2021年,Meta AI宣布的「Ego4D」(Egocentric 4D Perception)计划, 这个雄心勃勃的长期项目为的就是解决以第一人称视觉为中心的感知领域的研究挑战。
目前,已经收集了来自全球9个不同国家74个地点的855名独特参与者提供的3025小时视频。

就拿过山车来说吧,你在上面体验着肾上腺素飙升的快感。而下面的人则是看得一脸懵比。
人工智能,就更懵了……如果把CV系统绑在过山车上,它估计完全不知道自己该看些什么。即便在地面上从旁观者的角度看了几十万张过山车的图片或视频,也是如此。
LeCun认为,人工智能系统可以从这些视频中了解我们世界的物理基础。AI的理解将反过来成为众多能力的基础,如抓取物体或驾驶汽车。

那么,当解决了第一个挑战之后,第二个挑战的解决也就有了相应基础。
与人工智能研究之初不同的是,思维系统不应该再由根据逻辑规则运行符号系统组成,毕竟这些对世界的认知是靠人工进行编程的。
不过,对于第三个挑战,LeCun表示还没有很好的解决方案。
一个要在现实世界中行动的人工智能系统,无论是作为机器人还是自动驾驶汽车,都必须能够预测其行动的后果,并在每种情况下选择最佳行动。
目前来说,在例如控制机器人的手臂这种简单的情况下,已经可以实现了。但在未来,系统也需要能够处理所有其他的情景。
「这不仅仅是关于火箭的轨迹或机械臂的运动,这些都可以通过精细的数学建模来实现,」LeCun表示,「模型涉及到我们在世界上观察到的一切:人类的行为,涉及水或树枝等现象的物理系统等等。而对于这些复杂的事物,人类是可以很容易地开发出抽象的表征和模型。」
识别并不是理解
就以图像识别来说,虽然Meta的data2vec取得了相当SOTA的成绩,但监督学习仍然是最流行的方法。
也就是说,AI在工作之前需要「吃掉」大量的图像和相关的标注。其中,每个标注都与非常多的图像相关联,而这些图像则代表了物体在不同角度和光线下的状态等。
例如,为了让人工智能程序能够识别猫,就必须投入多达一百万张的照片,才能让AI建立起一个物体的内部视觉表征。但这种表征最终只是一种简单的描述,并没有立足于任何现实。
人类可以从呼噜声、毛发贴在腿上的感觉、猫砂盆的微妙气味等几百种方法认出一只「猫」,但这些对人工智能来说却毫无意义。
于是这里就有了一个关于AI的「天问」。
如果它从不口渴,它能理解什么是饮料吗?如果它从来没有被烧过,它能理解火吗?如果它从未打过寒颤,它能理解寒冷吗?
当一个算法「识别」一个物体时,它根本不了解该物体的性质。它只是与之前的例子进行交叉检验而已。
人工智能先驱Yann LeCun
Yann LeCun,计算机科学家,为卷积神经网络和图像识别领域作出了重要贡献,被誉为「卷积神经网络之父」。
Yann LeCun主要研究领域为机器学习、计算机视觉、移动机器人和计算神经科学等领域,他与Geoffrey Hinton、Yoshua Bengio并称为机器学习的「三巨头」。
他们3人共同获得2018年图灵奖,这被公认为计算机领域的最高荣誉。

从左至右分别为:Yann LeCun、Geoffrey Hinton、Yoshua Bengio
从欧洲到美洲,接续研究生涯
Yann LeCun于1960年出生于法国巴黎,并一直在巴黎学习,他于1983年获得巴黎高等电工和电子工程学院(ESIEE)的电气工程学士学位,1987年获得巴黎皮埃尔和玛丽居里大学(Pierre and Marie Curie)的计算机科学博士学位。
Yann LeCun的博士后研究转去了加拿大,师从多伦多大学著名的Geoffrey Hinton教授。尽管,博士后生涯十分短暂,但,正是在这里开启了师徒二人的合作研究,奠定了他们往后在机器学习领域的合作关系与重要成就。
此后,Yann LeCun紧跟Geoffrey Hinton教授的步伐,成了机器学习领域的重要人物!
研究手写数字分类,提出卷积神经网络
1988年,Yann LeCun加入AT&T(美国电话电报公司)贝尔实验室,此后,他还担任了图像处理研究部主任。
正是在AT&T,他的研究取得了重大突破。Yann LeCun提出了一种新的方法,即卷积、池化和全连接层次结构,研究手写数字分类,提出了卷积神经网络,即LeNet。
美国邮政服务等机构很快采用了类似的网络,以自动完成繁琐的分类工作,这个网络在识别邮政编码数字方面做得很好。
后来,卷积神经网络成了当前的深度神经网络的重要基石。
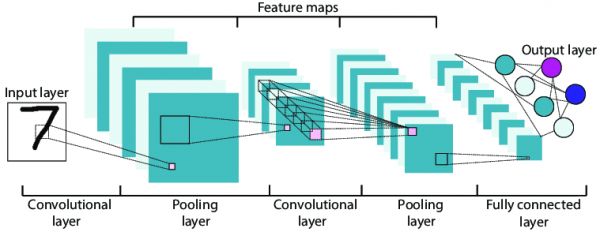
第五代LeNet DCNN(深度卷积神经网络)
2003年,Yann LeCun去了纽约大学担任教职,他指导纽约大学的数据科学倡议,并成为纽约大学数据科学中心的创始主任。

2013年底,他被任命为Facebook人工智能研究总监,后来,担任Meta公司的副总裁兼首席人工智能科学家。
2014年,Yann LeCun被IEEE(美国电气与电子工程师协会)授予「神经网络先锋奖」。
「我一直都觉得『学习』是智慧中的重要部分」
一直以来,Yann LeCun都对「学习」这个问题很感兴趣,这也直接决定了他日后的研究领域——「机器学习」。
Yann LeCun认为,「学习是智慧中的重要部分」。
那么,当前的机器学习发展到了什么程度呢?Yann LeCun在最近的访谈中,借用形象的比喻认为,「AI依然没有达到猫的水平」。
正是因为如此,AI以及AI研究人员依然有很多事要做。Yann LeCun自认为,「我不是一个好的理论科学家,我做的还行的是实现,让东西跑起来」。
对于他的成绩,Yann LeCun非常谦虚,他说:「我只是钻到一群比我聪明的人里面去」。
让Yann LeCun比较得意的一件事是,他一直在机器学习不断往下挖,去发现问题背后真正的问题。
「把问题简化,再简化,直到达到真正的核心问题。」Yann LeCun说,「要问最基本的问题,摒弃一切表面上的东西,直到得到一个简单得不可思议的问题。」
AI 的未来就在自监督学习里。
参考资料:
https://mixed-news.com/en/metas-ai-chief-three-major-challenges-of-artificial-intelligence/
http://yann.lecun.com/ex/bio.html
https://thenextweb.com/news/why-your-cat-is-lousy-at-chess-yet-way-smarter-than-even-the-most-advanced-ai?utm_campaign=profeed&utm_medium=feed&utm_source=social
本文来自微信公众号“新智元”(ID:AI_era),作者:新智元,36氪经授权发布。
相关推荐
2202年了,AI还是不如猫,图灵奖得主Yann LeCun:3大挑战依然无解
图灵奖得主LeCun及7位华人博士当选美国科学院2021院士
机器学习圣杯:图灵奖得主Bengio和LeCun称自监督学习可使AI达到人类智力水平
专访图灵奖得主Yoshua Bengio:AI能否有“意”为之?
对话图灵奖得主、CNN之父Yann LeCun:我在中国看到了AI研究热潮
36氪领读 | 图灵奖得主杨立昆人工智能十问:AI会统治人类吗?
神仙打架激辩深度学习:LeCun出大招,马库斯放狠话,机器学习先驱隔空“互怼”
图灵奖颁给深度学习三巨头,他们曾是一小撮顽固的“蠢货”
LSTM之父,被图灵奖遗忘的大神
图灵奖得主Bengio:深度学习不会被取代,我想让AI会推理、计划和想象
网址: 2202年了,AI还是不如猫,图灵奖得主Yann LeCun:3大挑战依然无解 http://m.xishuta.com/newsview58527.html
