Netflix是如何做决策的?(三):误报与统计显著性
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:决策是行动的指南。不管是个人还是企业,每天都要面临着无数的决策。决策的好坏会对结果产生巨大影响,如何做好决策是每个人都要上的一门必修课。在Netflix这里,他们采用了一种以实验为导向的决策流程,先小范围地对不同方案进行测试,根据对比效果调整,从而摸索出普遍适用的决策。他们为此还在官方技术博客推出了关于Netflix如何用A/N测试做出决策的系列文章。本文来自编译,是系列文章的第三篇。后续文章还将介绍实验在 Netflix 中的作用、Netflix对基础设施的投资是如何为实验提供支撑和扩展的,以及 Netflix内部实验文化的重要性。

划重点:
任何决策方法都不能完全消除不确定性以及犯错误的可能性
在对测试结果采取行动时,可能会犯两种类型的错误:误报与漏报
误报率跟观察到的实验组与对照组之间的度量值差异的“统计显著性”密切相关
A/B 测试里面还有两个概念跟 p 值密切相关:测试的否定域以及观测的置信区间
Netflix 是如何做决策的?(一):介绍
Netflix是如何做决策的?(二):什么是 A/B 测试?
在《Netflix是如何做决策的?(二):什么是 A/B 测试?》中,我们讨论了在 Netflix 上面测试 Top 10,以及如何利用这项测试的主要决策指标衡量会员对 Netflix 的满意度的。如果像这样的测试显示出主要的决策指标在统计上有显著改善的话,就说明这项功能非常适合面向所有会员推出。但是,得到测试的结果之后,我们如何才能知道自己做出的决定是否正确呢?重要的是要承认一点,任何决策方法都不能完全消除不确定性以及犯错误的可能性。利用基于假设生成、A/B 测试以及统计分析的框架,我们可以对不确定性进行细致的量化,并了解犯不同类型错误的概率。
在对测试结果采取行动时,我们可能会犯两种类型的错误。当来自测试的数据表明控制组和实验组体验之间存在表明差别,但实际上没有差别时,就会出现假阳性(也称为 I 型错误)。这种情况就好比健康人的体检结果呈阳性。在对测试做决定时可能还会犯另一个错误,那就是假阴性(也称为 II 型错误),当数据没有表明实验和控制之间存在表面差异,但实际存在差异时,就会发生这种情况。这种情况就像你有病,但相关的医学检测结果呈阴性。
作为建立直觉的另一种办法,不妨思考一下这个互联网和机器学习之所以存在的真正原因(编者注:一个玩笑):标记图像里面有没有猫。对于特定图像来说,决策有两种可能(贴上 “有猫”或“没猫”的标签),同样地事实也有两种(图像要么有猫,要么没有)。这导致总共有四种可能的结果,如图 1 所示。 A/B 测试也是如此:我们根据数据做出两个决策之一(“有足够的证据得出十大排名会影响会员的满意度这个结论”)或“证据不足”),而事实也会有两种可能,但我们永远没法完全确定(“十大排名确实影响到会员的满意度”或“没影响”)。

图 1:把图像标记为图中有没有猫时的四种可能结果。
关于误报和漏报,一个令人不安的事实是,我们没法排除掉。事实上,这两者是此消彼长的关系。对实验进行设计好让误报率很小必然会增加漏报率,反之亦然。在实践上,我们的目标是对这两种错误来源做好量化、理解和控制。
在本文的其余部分里,我们会利用简单的示例来建立起对误报和相关统计概念的直觉;在本系列的下一篇文章里,我们再谈谈漏报及相关统计概念。
误报与统计显著性
有了一个很好的假设,并且对主要决策指标有了清晰理解之后,是时候转到设计 A/B 测试的统计方面了。这个过程一般从确定可接受的误报率开始。按照惯例,这个误报率通常设定为 5%:对于实验组与对照组之间其实没有实质差异的测试,我们有5%的几率会错误地得出存在 “统计上显著”差异的结论。误报率为5%的测试就是显著性水平为 5%的测试。
约定显著性水平为5%可能会让人感到不舒服。遵循这一惯例,意味着我们接受这样的事实,即对于会员来说实验组和控制组体验没有明显不同的情况下,我们犯错的几率是5%。我们会把 5% 没有猫的照片标记成有猫。
误报率跟观察到的实验组与对照组之间的度量值差异的“统计显著性”密切相关,我们就用 p 值来测量吧。p 值是观测到至少与A/B测试实际观测样本相同极端的样本的概率,前提是实验组跟对照组的体验确实没有差异。理解统计显著性跟 p 值(这玩意儿已经让学统计学的困惑了一个多世纪)有一个直观的办法,那就是玩简单的机会游戏,去计算所有的相关概率并进行可视化。

图 2:不妨考虑玩一个简单的机会游戏,比方说像这样的抛硬币游戏,这是建立起统计直觉的好方法。
假设我们想知道一枚硬币是不是不均匀,也就是抛到正面的概率不是 0.5(或 50%)。这个情况看起来似乎很简单,但其实跟很多企业直接相关,其目标是要了解新产品体验会不会导致某些二元性的用户活动(单击某项UI 功能,再续租Netflix 服务一个月)出现的比率不同。所以任何我们可以通过简单的抛硬币游戏建立的直觉都可以直接映射到对A/B测试做出的解释。
为了确定硬币是不是不均匀,我们不妨做个实验:抛 100 次硬币并计算正面朝上的比例。由于存在随机性或“噪音”,就算硬币是完全均匀的,我们也不指望正好会有 50 次正面朝下, 50次反面朝上——但跟50 这个数偏差多少才算 “太多”呢?什么时候才有足够的证据来拒绝硬币其实是均匀的这个基线判定?如果抛 100 次有 60 次是正面的话,你是不是愿意得出硬币不均匀的结论?70呢?我们需要有一种方法来调整决策框架并了解相关的误报率。
为了建立直觉,不妨来一次思考练习。首先,我们假设硬币是均匀的——这就是我们的“零假设”。零假设始终是对现状或均等的陈述。然后,我们从数据里面寻找反对这个零假设的那些令人信服的证据。为了决定令人信服的证据应该由什么构成,在假设原假设为真的情况下,我们要计算每个可能结果的概率。对于抛硬币这个例子而言,就是抛100 次硬币抛出 0 个正面、1个正面、2个正面,以此类推直至 100 个正面的概率——前提假设是硬币是均匀的。具体数学我们就略过了,只需要留意所有这些可能的结果及其相关概率都用图 3 里面的黑条和蓝条显示(现在先忽略颜色)。
然后,我们可以将在硬币均匀的假设下计算得出的结果概率分布跟我们收集到的数据进行比较。假设我们观察到抛100 次里面其中的55% 得到的是正面(图 3 中的红色实线)。为了对这个观察是否硬币不均匀的有力证据进行量化,我们把每一个可能性低于观察的每一个结果的相关概率进行合计。此处,由于我们没有对更有可能出现正面或反面做出任何假设,所以我们把出现正面概率达到或超过55%的累加起来(红色实线右侧的条),把出现反面概率达到或超过55%的也累加到一起(红色虚线左侧的条)。
神秘的 p 值就出现了:在零假设为真的情况下,观测到至少与实际观测样本相同极端的样本的概率。在我们的例子中,零假设是硬币是均匀的,观测到的结果是抛100 次硬币当中有 55% 是正面,而 p 值大概是 0.32。解释如下:抛硬币 100 次并计算正面朝上占比的实验,用均匀的硬币(零假设为真)来抛,如果我们重复多次的话,在这些实验当中,其中有32% 的结果将至少有 55% 是正面朝上或至少 55% 是反面朝上(结果至少跟我们的实际观测结果一样不可能)。
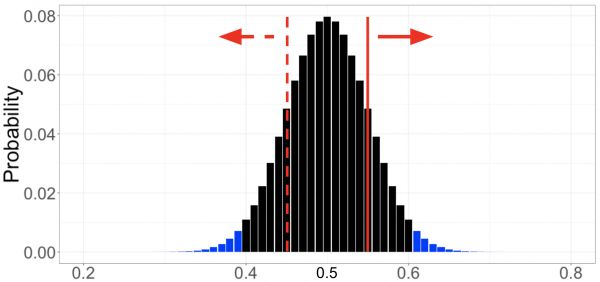
图 3:将一枚均匀的硬币抛 100 次,每一个结果的概率表示为正面朝上的占比。
那我们怎么用 p 值来确定是否存在统计上显著的证据表明硬币是不均匀的——或者表明我们的新产品体验对现状有改进呢?回到我们在开始时同意接受的 5% 的误报率:我们得出结论,如果 p 值小于 0.05,则存在统计上的显著影响。这形成了这样一种直觉,也就是如果我们的结果在硬币是均匀的假设下不太可能发生的话,我们应该拒绝硬币是均匀的零假设。在抛 100 次硬币观测到有 55 次正面朝上的例子里,我们计算出的 p 值为 0.32。由于 p 值大于 0.05 显著性水平,因此我们得出结论,没有统计上显著的证据表明硬币不均匀。
我们可以从实验或 A/B 测试中得出两个结论:要么得出有影响的结论(“硬币不均匀”、“十大排名功能提高了会员的满意度”),要么得出证据不足以得出有影响的结论(“不能得出硬币不均匀的结论”,“不能得出十大排名提高了会员满意度的结论”)。这跟陪审团审判很像,陪审团最后只能得出两个可能的结果,要么“有罪”,要么“无罪”(not guilty)——而“无罪”跟“清白”(innocent)是是非常不同的。同样地,这种A/B 测试的(频率主义)方法不允许我们得出没有影响的结论——我们从来都不会得出硬币是均匀的,或者新产品功能对我们的会员没有影响的结论。我们只是得出这样的结论,我们没有收集到足够的证据来驳回不存在差异的零假设。在上面抛硬币的例子里,我们抛了 100 次硬币然后观测到有 55% 是正面朝上,并得出结论,我们没有足够的证据可以将硬币标记为不均匀。至关重要的是,我们也没有得出硬币是均匀的结论——毕竟,如果我们收集到更多的证据,比如将同一枚硬币抛 1000 次的话,我们可能就能找到足够令人信服的证据来驳回硬币是均匀的零假设。
否定域与置信区间
A/B 测试里面还有两个概念跟 p 值密切相关:测试的否定域以及观测的置信区间。我们会在本节介绍这两个概念,还是用上面的抛硬币例子作为基础。
否定域。给测试建立决策规则的另一种方法是根据所谓的“拒绝域”——我们得出结论认为硬币是不均匀的一组值。为了计算拒绝域,我们再次假设原假设为真(硬币是均匀的),然后将拒绝域定义为概率总和不超过 0.05 的最不可能结果的集合。拒绝域由最极端的结果组成,前提是原假设是正确的——是拒绝原假设的证据最强的结果。如果观测值落在拒绝域内,我们就可以得出结论,存在统计上显著的证据表明硬币是不均匀的,并“拒绝”零假设。在那个抛硬币实验的情况下,拒绝域对应于观测到正面朝上的情况少于 40% 或超过 60%(如图 3 的蓝色阴影条所示)。我们称拒绝域的边界,本例情况下为正面朝向占比为 40% 与 60% ,为测试的临界值。
拒绝域与 p 值之间存在等价关系,两者都可得出相同的决定:当且仅当观测值位于拒绝域内时,p 值小于 0.05。
置信区间。到目前为止,我们已经通过首先从零假设开始来设立决策规则。零假设始终都是没有变化或等价的陈述(“硬币是均匀的”或“产品创新对会员满意度没有影响”)。然后,我们在该零假设下定义可能的结果,并将我们的观测结果跟这一分布进行比较。要想理解置信区间,把问题倒过来,去关注观测结果会有所帮助。我们不妨做个思考练习:给定观测结果,假设误报率指定为 5% 的情况,零假设的哪些值会导致得出不拒绝的决定?对于那个的抛硬币的例子,观测结果是在抛100 次硬币当中有 55% 是正面朝上,我们不拒绝硬币为均匀的无效。我们也不会拒绝正面朝上概率为 47.5%、50% 或 60% 的零假设。正面朝上概率从大约 45% 到 65% 的范围内,我们都不会拒绝零假设(图 4)。
这个值范围就是一个置信区间:在给定测试数据的情况下,在零假设下不会导致拒绝的值的范围。因为我们已经用显著性水平为5%的测试划定了区间,所以就设定了 95% 的置信区间。我们的解释是,在重复实验的情况下,置信区间在 95% 的时间内可覆盖真实值(此处为正面朝上的实际概率)。
置信区间与 p 值之间存在等价关系,两者都可得出相同的决定:当且仅当 p 值小于 0.05 时,95% 置信区间未覆盖空值,并且在这两种情况下我们都拒绝无影响的零假设。
图 4:通过映射一组值来建立置信区间,这些值在用来定义零假设时不会导致拒绝给定观测结果。
总结
通过以抛硬币为例的一系列思考练习,我们已经建立起关于误报、统计显著性、 p 值、拒绝域、置信区间以及我们可根据测试数据做出的两个决定的直觉。这些核心概念和直觉可直接映射到比较 A/B 测试的实验与控制体验上面。我们定义了一个二者没有差异的“零假设”:也就是“B”体验没有改变会员满意度。然后我们进行同样的思考实验:假设会员满意度没有差异的话,实验组和对照组之间的指标差异可能有哪些结果,相关概率是多少?然后,就像抛硬币例子一样,我们可以把实验的观测结果跟这个分布进行比较,计算出 p 值并得出测试的结论。就像抛硬币的例子一样,我们可以定义拒绝域并计算出置信区间。
但是误报只是我们在对测试结果采取行动时可能会犯的两个错误当中的一个。在本系列的下一篇文章里,我们还会介绍另一种类型的错误:漏报以及与统计功效密切相关的概念。
译者:boxi。
相关推荐
出海企业如何做战略选择和决策
Netflix进军游戏领域,解药还是毒药?(三)
Netflix知道自己的敌人是谁
揭秘Google、FB、Netflix、亚马逊的通用增长神器
从《三体》到《水浒传》,Netflix探路中国市场从改编IP开始?
Netflix和腾讯都拍《三体》,谁才是真正的降维打击?
硅谷重塑好莱坞,Netflix创始人是如何做到这一切的?
Netflix碰撞《三体》 长达十年的版权纠葛:奇货、利益和提款机
AI 让学术论文更客观:机器人助手查找利益冲突
贝索斯的决策方法论:当决策可逆时,当机立断
网址: Netflix是如何做决策的?(三):误报与统计显著性 http://m.xishuta.com/newsview55500.html