大数据算法:知心朋友还是认知牢笼?
如今,推荐算法在网络生活中的重要作用无需赘言,而自算法时代以来,伦理一直是悬在算法头顶上的达摩克里斯之剑。8月2日,中央宣传部等五部门联合印发了《关于加强新时代文艺评论工作的指导意见》,提出健全完善基于大数据的评价方式,加强网络算法研究和引导,开展网络算法推荐综合治理,不给错误内容提供传播渠道。对推荐算法的规制再次被提上日程。就影视平台而言,推荐算法在一味地迎合用户的口味的过程中,不可避免地造成了趣味圈层化、品味低俗化和选择被动化的弊病。然而不论如何,算法时代已经到来,既然日常生活已然离不开它,如何与算法文化相处是现在所要面临的唯一问题。
在互联网时代,每时每刻都有大量的内容被生产出来,不论是短视频还是传统影视作品,都是人穷尽一生也无法看完的。将内容与其目标受众连接起来,是影视平台的主要任务。除了用户主动的检索行为之外,通过推荐算法所得出的主页展示是另外一条途径。

在众多影视平台之中,Netflix算是影像内容个性化推荐的先行者。它从2006年悬赏百万美元进行推荐算法大赛开始,就一直致力于不断优化面向用户消费需求的影像内容推荐系统。如今,Netflix用户平均每3个小时的视频播放时长中就有2个小时是来自于首页的推荐内容。
Netflix的现行的推荐算法综合考虑到短期热点,用户的兴趣点以及用户的观看场景。除了用于推荐内容本身之外,推荐算法还用于平台选择推荐方式。Netflix针对每一部电影都制作了30-40份海报,每份海报的侧重点不同。由于每一部电影对于不同人的吸引点也各不相同,有的因为类型对胃口,有的因为某位明星加盟,所以Netflix通过将侧重点各异的海报分发到不同的受众群体,以提升播放的转化率。
相较而言,国内的视频平台的推荐算法起步较晚,但是发展迅猛。爱奇艺于2013年推出了业界第一个智能推荐的客户端,仅两年之后,用户浏览的推荐内容就占到了总流量的30%。
优酷的个性化推荐则从2017年下半年开始部分推行,2018年才全面推广。不过凭借阿里的庞大用户数据,优酷在用户肖像上有着天然的优势。2018年优酷认知实验室成立,在视频结构分析和内容智能生成上进行了提升改进。视频的结构分析也就是直接从声画中提取信息,进一步精细化视频元素;而内容智能生成主要应用于海报,以达到前述Netflix推荐方式个性化的效果。
可以说,推荐算法是各大影视平台博弈中的重要战场。
人工智能还是人工智障
说起来,推荐算法自诞生伊始就跟影视有着深厚的渊源。
推荐算法的研究起源于20世纪90年代,由美国明尼苏达大学 GroupLens研究小组最先开始研究,他们想要制作一个名为 Movielens的电影推荐系统,从而实现对用户进行电影的个性化推荐。首先研究小组让用户对自己看过的电影进行评分,然后小组对用户评价的结果进行分析,并预测出用户对并未看过的电影的兴趣度,从而向他们推荐从未看过并可能感兴趣的电影。
也就是说,早在彼时算法的逻辑就已经初具雏形了,互联网时代的到来为算法提供了大量的可供处理的信息,此后,推荐算法才成为视频平台的制胜法宝。
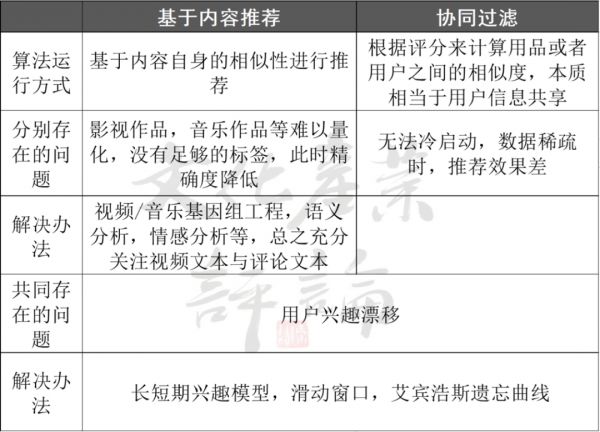
总结起来,现在各影视平台所用的纷繁复杂的推荐算法不外乎两条根本逻辑:一个是协同过滤算法,一个是基于内容的推荐算法。
协同过滤算法(Collaborative Filtering,简称CF),也就是根据所有用户的历史数据,来推测每个用户当下所可能感兴趣的内容。这种方法将用户-内容的评级矩阵作为输入数据,输出的则是用户对每一个尚未接触过的内容的预估兴趣值,并依次将内容排序推荐给用户。
协同过滤算法的优势是不需要关于内容本身的任何参数,也就是说,内容是什么不重要,谁喜欢它才重要。因此,许多平台的相似推荐会采用“喜欢这部电影的人也喜欢”这种表述。同样,当韩国导演洪尚秀的电影《引见》的相似推荐中,同时出现蔡明亮、滨口龙介和赫尔佐格的作品时,我们也就不必惊讶,因为在协同过滤的逻辑下,正是影迷的选择造就了不同时期、不同国别、不同风格的导演之间强有力的连结。
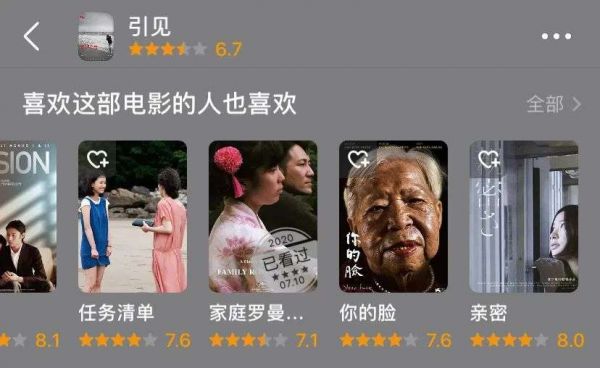
由于不需要关于内容的任何信息,协同过滤算法被广泛应用于电影和音乐这种难以量化的内容的推荐上。它最大的问题就是需要丰富的历史数据和庞大的用户群体,因此难以应用于平台诞生之初。
第二种是基于内容的推荐算法(Content-Based Filtering简称CBF),也就是根据内容的分类信息为用户推荐相似的内容。此时的输入数据是用户的偏好,以及内容的属性,输出的是最符合用户偏好的内容。
不难想象,对于影视而言,基于内容的推荐算法最大的挑战来源于影视内容的难以量化,往往要使用高昂的人工成本。在这方法做到极致的仍是Netflix。
早在2006年,Netflix产品副总裁托德·耶林便带领团队为影视内容贴上“微标签”。这一方法也被其设计者赋予一个极具数理色彩的名称——“Netflix量子理论”。在具体操作中,Netflix雇佣独立评论者来看片,并从1000多个标签中进行选择以描述他们所看到的内容,如血腥程度,浪漫程度,情节结论性等,由此生成了丰富的“微类型”。微类型的总量竟达76897种之多,比如“情感充沛的反体制纪录片”“基于真实生活的皇室掠影”,都是所谓的“微类型” ,其描述方式几乎要突破语言的极限。
基于内容的推荐算法需要耗费大量人力,协同过滤算法则难以应对缺乏数据的“冷启动”过程。此外,两种算法所共同面临的另一个难题是用户兴趣漂移,即用户的兴趣点随着时间变化,长期推送相似的内容会让用户感到乏味。为此,许多模型通过加入艾宾浩斯遗忘曲线,滑动窗口,长短期兴趣模型等方法进行改进。
不过,有时算法所设定的过快的更换速度也容易让用户措手不及。假如用户本着好奇心进入了自己本不熟悉的内容,又一不小心看完了,结果第二天首页可能被相似内容全部占领。说到底每个人的遗忘速度也是不一样的。人心难测,和所有现在的弱人工智能一样,推荐算法距离测量人心还有相当的距离。
推荐算法的“三宗罪”
自推荐算法成为影视平台竞相比拼的竞争力后,对推荐算法的诟病就从没有停止过。在算法逻辑之下,内容的价值单纯地被点击率、播放完成率等指标所取代,在此之下,趣味圈层化、内容低俗化和选择被动化可以说是推荐算法的三宗原罪。
趣味圈层化
推荐算法的问题之一就是趣味圈层化,用术语可以表示为“信息茧房”或是“过滤泡泡”。
“过滤泡泡”这个概念由Eli Pariser在2010年提出,指的是在算法推荐机制下,高度同质化的信息流会阻碍人们认识真实的世界。“信息茧房”由美国学者桑斯坦提出,是指算法使每个人都沉浸在自己想要看到的内容中,进一步压抑群体共识。虽然侧重点不同,但是这两个概念共同指向了算法对个体认知客观世界造成的挑战。

反映在影视推荐平台上,“信息茧房”或“过滤泡泡”首先造成了“聚类”与“区隔”。
在推荐算法投其所好的投喂下,令观者感兴趣的内容占满整块屏幕,虽然算法帮助小众爱好者在茫茫人海中找到彼此,但是在加速“聚类”的同时,也加深了不同群体之间的认知的沟壑,其结果是人们只跟与自己相似的用户分享趣味和观点。
内容低俗化
如果说趣味圈层化的问题还是存有争议的话,那么内容低俗化的罪名可以说是铁板钉钉的。在低俗的内容面前,任何其他的风格特征都显得缺少竞争力。如果单纯以点击量为目标的话而不设置其他限制的话,那么内容走向低俗几乎是个必然。
内容低俗化的问题在短视频平台较为严重,因为猎奇是绝大多数人的心理弱点,一条接一条的猎奇内容就像一口接一口的垃圾食品一样停不下来。相信不少人都有这样的经历,就是尽管严格控制自己手机上的观看内容,但是在拥挤的公交地铁上不经意地瞥见旁边人正在观看的猎奇内容,仍会被牢牢地锁住目光。
低俗和猎奇的内容充斥着屏幕,不仅会造成时间的浪费,虚假的内容也会对用户造成误导。被网友亲切地称为藏狐的科普up主张辰亮,就专门制作网络生物鉴定的短视频,来辟谣高热度的猎奇视频中的虚假信息。其中很多的网络视频伪造了民间传说中的“水猴子”,尽管小亮反复辟谣“水猴子”,但是还是有更多的“水猴子”被伪造出来。

“水猴子”是二十世纪最大的谣言之一,传说中的“水猴子”刀枪不入,趁人不备拖人下水。对“水猴子”的恐惧曾对建国之初的生产和建设造成了不小的危害。在今天,“流量即正义”的算法逻辑仍难以避免这些虚假内容的传播,也正因为推荐算法的这一缺陷,和“水猴子”的斗争仍有赖小亮们的坚持。

选择被动化
相较于前两桩指控,选择被动化的指控更接近于算法的根源性问题。
如果把影视的内容比作精神口粮,那么每天打开平台就可以受到主页精准投喂的用户,正在逐渐失去主动觅食的能力。尽管投喂的内容可能是更加可口美味的,但是就用户与平台之间的权利关系而言,推荐算法奠定了平台主动权。
个体意义上的被动是显而易见的,在推荐算法面前,甚至很多“主动觅食”的尝试都显得徒劳。试想,有多少人本想检索一下自己感兴趣的内容,却在打开主页的一瞬间沦陷于精心排布的主页内容之中。在惯性的观看行为之下,推荐算法成了时间的黑洞。

而从更宏观的层面来看,用户与其说是被算法操纵,毋宁说是被算法背后的资本所裹挟。用户一旦习惯于被动接受,算法就拥有了掌控用户趣味甚至认知的能力。这个能力被怎样使用,只是资本与技术以怎样的方式合谋的问题。
对抗与共存
尽管对于推荐算法的诸多弊病已经被讨论多年,但是在海量的内容之中,想要脱离算法的掌控,已经是不可能的事。除了社会层面上更严格的规制之外,在个体层面上,一些年轻人执着于抹去自己在平台上留下的一切痕迹,以略显徒劳的方式与推荐算法对抗。
他们本着“不点赞、不评论、不关注、不登录”的四不原则,只要让算法猜不透我,也就对我无可奈何。然而,这种绝交式的对抗策略,在抵制算法的诱惑的同时,也放弃了算法带来的便利,而算法的初衷是帮助用户找到与其需求相匹配的内容。
此外,从技术源头上深度考虑用户的行为与需求矛盾的实验也在进行。

IBM的研究员和麻省理工媒介实验室(MIT Media Lab)发展出了一种AI推荐技术,能够兼顾用户的喜好与道德准则。不同于此前静态的规则设置,这种技术可以在实例中学习道德准则,正如其可以学习用户偏好那样,并最终在道德准则和用户偏好中做一权衡。该方法首先被用于青少年电影推荐,因为在电影推荐中,青少年的偏好和成年人对他们的限制冲突最为明显。
在实验中,父母为孩子设定色情与暴力的尺度,算法在父母的要求和孩子的偏好之间做出权衡。该方法还被用于计算药物的剂量,在医生追求的稳妥和患者追求的生活质量之间进行平衡给出推荐方案。
尽管该方法在亲子电影推荐和医患用药建议情况下表现良好,但在只涉及一个用户的环境中会遇到限制。在这种情况下,用户将负责定义他们自己的道德准则和约束,而他们也可以轻而易举地违背自己设置道德准则的初心。不论如何,这一尝试代表了算法社会解决自身“囚徒“风险的另一种可能。
结语
在日益原子化的当代社会中,推荐算法可能是最懂你的人;然而过于亲密的关系之下,推荐算法可能又会成为人加之于自己头脑上的牢笼。不管是冷启动、细化分类、兴趣漂移等方面的诸多不便,还是趣味圈层化、内容低俗化以及选择被动化的“原罪”,对推荐算法的警惕会伴着它愈加广泛应用持续下去。如何摆脱算法的牢笼?社会层面的规制和技术层面的尝试都在进行。个体层面上,消除历史数据或许显得无力,但是意识到推荐算法的囚徒风险,已经是迈出算法牢笼的第一步。
参考资料
[1]雷锋网.AI算法与道德规则如何平衡?IBM推出AI推荐技术
[2]深燃.年轻人开始“反推荐算法”:算法不讲武德!
[3]雷锋网.揭秘优酷认知实验室
[4]王晓通.大数据背景下电影智能推送的“算法”实现及其潜在问题
本文来自微信公众号“文化产业评论”(ID:whcypl),作者:王艺璇,编辑:斯琴,36氪经授权发布。
相关推荐
大数据算法:知心朋友还是认知牢笼?
算法不是万能的:在算法时代,看见人的力量
结合大数据与认知智能,「百分点」为政府和企业提供数据服务整体解决方案
潮科技 | 认知计算:“机器认知”与“人类认知”的碰撞
算法操控大选,数据左右美国
医渡云首席AI科学家闫峻:医疗大数据技术如何重新认知现代医学?
隐私保护升级,大数据金融会死吗?
喻国明:算法是信息茧房的缔造者,还是打破者?
AI算法是服务了你,还是操纵了你?
人工智能还是人工智障?带你看看大型算法翻车现场
网址: 大数据算法:知心朋友还是认知牢笼? http://m.xishuta.com/newsview48638.html
