DeepMind最新论文:强化学习“足以”达到通用人工智能
编者按:本文来自微信公众号“学术头条”(ID:SciTouTiao),作者:XT,排版:王落尘,编审:寇建超,36氪经授权发布。
从 1956 年达特茅斯会议首次定义人工智能(AI)至今,人工智能已经经历了 60 多年的发展历程,计算机领域的科学家们取得了一次又一次的革命性进步,从机器学习、深度学习到强化学习,科学家们设计开发出了许多复杂的人工智能机制和技术,来复制人类视觉、语言、推理、运动技能和其他与智能生命相关的能力。
尽管这些努力使得人工智能系统能够在有限的环境中有效地解决一些特定的问题,但目前还没有开发出像人类和动物一样 “会思考的机器” ,“通用人工智能(AGI)” 时代尚未到来,想要让机器完全模拟人类进行自主学习、模式识别、想象创造等活动看起来遥不可及。
尽管一些乐观主义者认为通用人工智能离我们不到十年,但一项针对机器学习专家的大型调查表明,如果存在通用人工智能,那我们可能要到 2040 年左右才能拥有它。
近日,来自 DeepMind 的科学家在提交给同行评议的期刊《人工智能》(Artificial Intelligence)上的一篇题为 “Reward is enough” 的论文中认为,人工智能及其相关能力不是通过制定和解决复杂问题而产生的,而是通过坚持一个简单而强大的原则:奖励最大化。

(来源:ScienceDirect)
该研究由 DeepMind 首席研究科学家、伦敦大学学院教授 David Silver 领衔,研究灵感源于他们对自然智能的进化研究以及人工智能的最新成就,在撰写论文时仍处于预证明阶段。研究人员认为,奖励最大化和试错经验足以培养表现出与智力相关的能力行为。由此,他们得出结论,强化学习是基于奖励最大化的人工智能分支,可以推动通用人工智能的发展。
“奖励最大化” 的人工智能实现途径
创建人工智能的一种常见方法就是在计算机中尝试复制智能行为的元素。例如,我们对哺乳动物视觉系统的理解催生了各种人工智能系统,来实现对图像进行分类、定位照片中的对象、定义对象之间的边界等等。同样,我们对语言的理解有助于开发各种自然语言处理系统,例如回答问题、文本生成和机器翻译。
这些都是狭义人工智能的实例,这些系统旨在执行特定任务,而不是具有一般解决问题的能力。一些科学家认为,组装多个狭义的人工智能模块会产生更高的智能系统。例如,我们可以拥有一个软件系统,在单独的计算机视觉、语音处理、NLP 和电机控制模块之间进行协调,以解决需要多种技能的复杂问题。
相比之下,通用人工智能有时也被称为人类级别的人工智能,它更像是《星球大战》中的 C-3PO,因为它可以理解上下文、潜台词和社会线索,甚至被认为可能完全超过人类。

(来源:pixabay)
Deep Mind 的研究人员提出的另一种创建人工智能的方法:重新创建产生自然智能的简单而有效的规则。为什么自然界中的的动物和人类会表现出丰富多样的智能行为?Silver 等人指出,可能是由于每一种能力都源于对一个目标的追求,而这个目标是专门为激发这种能力而设计的。为此,该研究设计了一个替代假设:最大化奖励的一般目标足以驱动表现出自然和人工智能研究的大部分(尽管不是全部)能力的行为。”
这种假设基本上是遵守达尔文的生物进化论。从科学的角度分析,在我们周围看到的复杂有机体中,并没有自上而下的智能设计。数十亿年的自然选择和随机变异过滤了生命形式,使其适合生存和繁殖,能够更好地应对环境中的挑战和情况的生物设法生存和繁殖。其余的都被淘汰了。
这种简单而有效的机制导致了具有各种感知、导航、改变环境和相互交流的技能和能力的生物去进化。
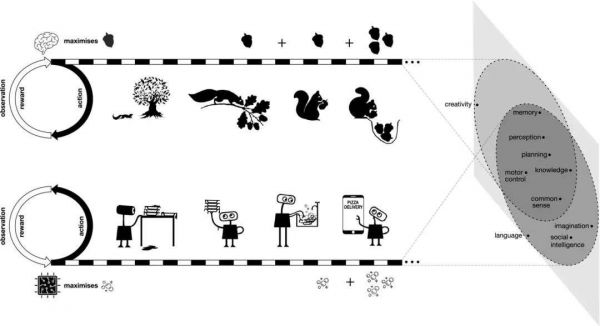
图 | “奖励就足够” 的假设,假定智力及其相关能力可以被理解为在其环境中行动的主体促进奖励的最大化
研究人员在论文中写道:“动物和人类面临的自然世界,以及人工代理未来面临的环境,本质上都是如此复杂,以至于它们需要复杂的能力才能在这些环境中生存下来。因此,以奖励最大化来衡量的成功需要各种与智力相关的能力。在这样的环境中,任何使奖励最大化的行为都必须表现出这些能力。从这个意义上说,奖励最大化的一般目标包含许多甚至可能的所有智能目标。”
例如,考虑一只松鼠,它为了寻求减少饥饿的奖励。一方面,它的感官和运动技能帮助它在有食物时定位和收集坚果。但是,当食物变得稀缺时,一只只去寻找食物的松鼠必然会饿死。这就是为什么它也有计划技能和记忆来缓存坚果并在冬天恢复它们。松鼠具有社交技能和知识,可以确保其他动物不会偷吃它的坚果。如果你放大来看,饥饿最小化可能是 “活下去” 的一个子目标,这还需要一些技能,例如发现和躲避危险动物、保护自己免受环境威胁以及寻找季节性变化的更好栖息地。
研究人员写道:“当与智力相关的能力作为奖励最大化的单一目标的解决方案出现时,这实际上可能提供了一个更深入的理解,因为它解释了为什么这种能力会出现。相反,当每一种能力被理解为其自身专门目标的解决方案时,为了关注该能力的作用,为什么的问题就被绕开了。”
研究人员认为,在可能的奖励最大化方法中,最通用和可扩展的方法是智能体通过试错及与环境的交互来学习这样做。
通过 “奖励最大化” 发展能力
在这篇论文中,研究人员列举了一些高级示例,来说明 “在为许多可能的奖励信号最大化服务中,智能和相关能力将如何隐含地出现,对应于自然或人工智能可能指向的许多实用的目标。”
在知识和学习方面,研究人员将知识定义为代理人的内部信息,包含代理人选择行动、预测累积奖励或预测未来观察的特征,这些知识有先天具备的,也有后天学习而来的知识。奖励和环境也塑造了动物与生俱来的知识。例如,由狮子和猎豹等掠食性动物统治的敌对栖息地会奖励反刍动物,它们自出生以来就具有逃避威胁的先天知识。同时,动物也因其学习栖息地特定知识的能力而获得奖励,例如在哪里可以找到食物和住所。
通过列举生物世界的学习,说明环境可能同时需要先天和后天的知识,奖励最大化的代理将在需要时,通过自然代理的进化和人工代理的设计包含前者,并通过学习获得后者。在更丰富和更长久的环境中,需求的平衡越来越向学习知识转移。

(来源:VentureBeat)
在感知方面,动物的感官技能服务于在复杂环境中生存的需要。对象识别使动物能够检测食物、猎物、朋友和威胁,或找到路径、庇护所和栖息地;图像分割使他们能够分辨不同对象之间的差异,并避免致命错误,例如跑下悬崖或从树枝上掉下来;听觉有助于发现动物在伪装时看不到或找不到猎物的威胁;触觉、味觉和嗅觉也给动物带来优势,使其对栖息地有更丰富的感官体验,在危险的环境中获得更大的生存机会。
于是,研究人员假设感知可以被理解为服务于奖励的最大化。从奖励最大化而不是监督学习的角度考虑感知,最终可能会支持更大范围的感知行为,包括具有挑战性和现实形式的感知能力。
在社会智能方面,研究人员假设社会智能可以被理解为在包含其他代理人的环境中,从一个代理人的角度最大化累积奖励来实施,并推断出如果一个环境需要社会智能,奖励最大化将产生社会智能。
在语言理解方面,研究人员假设语言能力的全部丰富性,包括所有这些更广泛的能力,产生于对奖励的追求,而理解和产生语言的压力可以来自许多奖励增加的好处。例如,一个代理人能够理解 "危险" 警告,那么它就可以预测并避免负面的奖励;如果一个代理可以产生 "取" 的命令,可能会导致环境将一个物体移到代理的附近。这些奖励的好处可能最终会导致代理人具备各种复杂的语言技能。
它是一个代理人根据复杂的观察序列(如接收句子)产生复杂的行动序列(如说出句子),以影响环境中的其他代理人并积累更大的奖励的能力的一个实例。理解和产生语言的压力可以来自许多奖励增加的好处。
研究人员还讨论了泛化、模仿以及一般智能的奖励驱动基础,将其描述为 “在单一、复杂的环境中使单一奖励最大化 "。在这项研究中,研究人员在自然智能和通用人工智能之间进行了类比:“动物的经验流足够丰富和多样的,它可能需要一种灵活的能力来实现各种各样的子目标(例如觅食、战斗或逃跑),以便成功地最大化其整体奖励(例如饥饿或繁殖)。类似地,如果一个人工智能代理的经验流足够丰富,那么许多目标(例如电池寿命或生存)可能隐含地需要实现同样广泛的子目标的能力,因此奖励的最大化应该足以产生一种通用的人工智能。”
“奖励最大化” 的强化学习
按照人工智能之父 John McCarthy 的说法,“智力是在世界范围内实现目标的能力的计算部分”,而后来发展起来的强化学习将寻求目标的智能问题正式化,对应于不同智能形式的奖励信号,在不同的环境中如何实现最大化。
强化学习是人工智能算法的一个特殊分支,由三个关键要素组成:环境(Environment)、代理(Agent)和奖励(Reward)。通过执行操作,代理会改变自己和环境的状态。根据这些动作对代理必须实现的目标的影响程度,对其进行奖励或惩罚。在许多强化学习问题中,智能体没有环境的初始知识,并从随机动作开始。根据收到的反馈,代理学习调整其行为并制定最大化其奖励的策略。
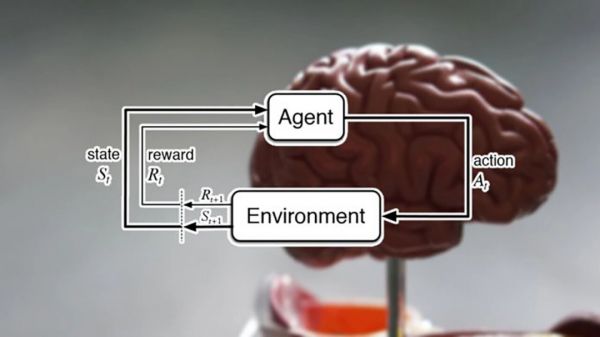
(来源:TechTalks)
在强化学习研究领域的一个著名的例子:敲锣训猴。驯兽师在训练猴子时,以敲锣为信号来训练猴子站立敬礼,每当猴子很好地完成站立敬礼的动作,就会获得一定的食物奖励;如果没有完成或者完成的不对,不仅不会得到食物奖励,甚至会得到一顿鞭子抽打。由于听到敲锣后站立敬礼是猴子在所处环境下能够获得的最大收益,所以时间长了猴子自然在听到驯兽师敲锣后,就会站立敬礼。
强化学习就是训练对象如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。在这篇论文中,DeepMind 的研究人员建议将强化学习作为主要算法,它可以复制自然界中看到的奖励最大化,并最终导致通用人工智能。
研究人员写道:“如果一个智能体可以不断调整其行为以提高其累积奖励,那么其环境反复要求的任何能力最终都必须在智能体的行为中产生。” 并补充说,一个好的强化学习代理可以在学习过程中获得表现出感知、语言、社会智能等的行为,以便在一个环境(如人类世界)中实现奖励最大化,在这个环境中,这些能力具有持续的价值。
在论文中,研究人员提供了几个例子,展示了强化学习代理如何能够在游戏和机器人环境中学习一般技能。例如,当被要求在围棋比赛中取得最大胜利时,AlphaZero 学会了跨越围棋许多方面的综合智能。
然而,研究人员强调,一些根本性的挑战仍未解决,他们并没有对强化学习代理的样本效率提供任何理论上的保证。而是猜想,当强大的强化学习代理被置于复杂的环境中时,将在实践中产生复杂的智能表达。如果这个猜想是正确的,它将为实现人工通用智能提供了一条完整的途径。
强化学习以需要大量数据而闻名,强化学习代理可能需要几个世纪的游戏时间才能掌握计算机游戏。研究人员仍然没有想出如何创建强化学习系统来将他们的学习推广到多个领域。因此,环境的微小变化通常需要对模型进行全面的重新训练。
研究人员还承认,奖励最大化的学习机制是一个未解决的问题,仍然是强化学习中有待进一步研究的核心问题。论文抛出了整个强化学习领域研究的一个核心问题,即如何在一个实用的代理中有效地学习奖励最大化。
“奖励最大化” 的优缺点
加州大学圣地亚哥分校的神经科学家、哲学家和名誉教授帕特里夏・丘奇兰(Patricia Churchland)将该论文中的想法描述为 “非常仔细和有见地的解决方案”。
然而,Churchland 也指出了该论文关于社会决策的讨论中可能存在的缺陷。Churchland 最近写了一本关于道德直觉的生物学起源的书,他认为依恋和联系是哺乳动物和鸟类社会决策的一个强大因素,这就是为什么动物为了保护他们的孩子而将自己置于极大的危险之中。
Churchland 说:“我倾向于将亲密关系以及其他人的关怀视为自己,也就是 “我和我” 的范围的延伸。在这种情况下,我认为,对论文假设进行小幅修改以实现对 “我和我” 的奖励最大化会非常有效。当然,我们群居动物都有依恋程度,对后代超强依恋、对配偶和亲属非常强依恋,对朋友和熟人很强依恋等等,依恋类型的强度会因环境和发育阶段而异。”
Churchland 表示,这不是一个主要的批评,并且很可能会非常优雅地融入这个假设。Churchland 说:“我对论文的详细程度以及他们考虑可能存在的弱点的仔细程度印象深刻。我可能也不对,但我倾向于认为这是一个里程碑。”
针对 “哪一个通用目标可以产生所有形式的智能” 这一问题。研究人员在讨论部分提到,在不同的环境中实现不同的奖励最大化可能会导致不同的、强大的智能形式,每一种智能都会表现出自己令人印象深刻的、但又无法比拟的一系列能力。一个好的奖励最大化的代理将利用其环境中存在的任何元素,但某种形式的智能的出现并不以它们的具体内容为前提。
相比于只有精心构建的奖励才有可能诱发一般的智力,研究人员认为人工智能代理智力的出现可能对奖励信号的性质相当稳健。此外,他们建议强化学习问题也可以转化为一个概率框架,接近于奖励最大化的目标。

(来源:pixabay)
数据科学家 Herbert Roitblat 对该论文的立场提出了挑战,即简单的学习机制和试错经验足以培养与智能相关的能力。Roitblat 认为,论文中提出的理论在现实生活中实施时面临着一些挑战。
Roitblat 说 “如果没有时间限制,那么试错学习可能就足够了,否则我们就会遇到无限数量的猴子在无限长的时间内打字的问题。” 无限猴子定理指出,一只猴子在无限长的时间内敲打打字机上的随机键,最终可能会打出任何给定的文本。
Roitblat 在《Algorithms are Not Enough》一书中解释了为什么所有当前包括强化学习在内的人工智能算法,都需要仔细制定人类创建的问题和表示。他表示,一旦建立了模型及其内在表示,优化或强化就可以指导其进化,但这并不意味着强化就足够了。同样,Roitblat 补充说,该论文没有就如何定义强化学习的奖励、动作和其他元素提出任何建议。
Roitblat 说:“强化学习假设智能体具有一组有限的潜在动作。已经指定了奖励信号和价值函数。换句话说,通用智能的问题恰恰是提供强化学习作为先决条件的那些东西。因此,如果机器学习都可以简化为某种形式的优化,以最大化某些评估措施,那么强化学习肯定是相关的,但它的解释性并不强。”
参考资料:
https://www.sciencedirect.com/science/article/pii/S0004370221000862
https://venturebeat.com/2021/06/09/deepmind-says-reinforcement-learning-is-enough-to-reach-general-ai/
https://www.jonkrohn.com/posts/2021/1/22/google-deepminds-quest-for-artificial-general-intelligence
相关推荐
DeepMind最新论文:强化学习“足以”达到通用人工智能
人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
强化学习:兵分三路,挺进产业
DeepMind和暴雪发出神秘预告,终极人机大战要来了?
人均年薪400万、公司年亏40亿,正在盖大楼的DeepMind最新财务数据曝光
控制AI之战:揭秘谷歌与DeepMind的爱恨情仇
当AI开始“踢脏球”,你还敢信任强化学习吗?
DeepMind巨亏42亿、独角兽惨遭3折贱卖,AI公司为何难有“好下场”?
DeepMind爆出无监督表示学习模型BigBiGAN,GAN之父点赞
南京大学教授俞扬:走出游戏世界的强化学习
网址: DeepMind最新论文:强化学习“足以”达到通用人工智能 http://m.xishuta.com/newsview45249.html