年轻人都在“反算法”,Spotify先站出来了
本文来自微信公众号:极客公园(ID:geekpark),作者:汤一涛,头图来自:视觉中国
作为煎饼果子圣地,天津人评价最高的煎饼店,一定不是人们趋之若鹜的网红店,而是“我家楼下那家”。
人们对于音乐的喜好,和天津人对煎饼果子的爱有异曲同工之处,好友热情分享过来的音乐,通常会被你归为“垃圾”。随着卡带、CD、MP3 逐渐被移动互联网取代,音乐应用最终承载起满足人们音乐品味的重任。
社交媒体上经久不衰的唯二的两个问题,一个是为什么“随机”推荐并不真的“随机”,另一个就是为什么音乐平台推荐的音乐都这么“垃圾”。如果有机会,估计所有人最想做的事情就是去面对面问一下音乐应用的程序员,自己到底怎么才能“调教”好这个 App,让它推荐更多自己喜欢的音乐。
以用户数最多的音乐平台 Spotify 为例,他们最近开发出了一种新的算法——偏好转化模型(Prefenrence Transition Model,PTM),想要预测,一年后的你会听什么音乐。
揭开 Spotify“算法黑箱”
抖音、微博、淘宝、YouTube、Spotify,这些平台的算法想尽办法猜测我们喜好,然后把它们觉得我们会喜欢的内容推给我们。
有些时候,这些算法确实猜得很准,我们看到的都是喜欢的内容。但从另一方面来说,我们只看了自己喜欢的内容。
互联网活动家伊萊·帕里瑟(Eli Pariser)在 2011 年的时候提出了他著名的“过滤气泡”(Filter Bubble)理论:算法会根据用户的地址、历史点击、过往搜索等用户相关信息猜测用户喜好。这个过程中,那些与用户意见相悖的信息就被过滤了。长期下来,用户就会无法接触新的想法和信息,逐渐隔绝在自己的意识形态泡沫中。
在处理过滤气泡的问题上,Spotify 一直因为精准的算法而为人称道。不只是让用户在自己熟悉的内容中打转,它总能帮用户发现那些新鲜的歌曲。而恰好,这些歌曲还很讨人喜欢。
“每周发现”(Discovery Weekly)是 Spotify 在 2015 年 7 月的王牌栏目。每周一,Spotiy 就会向用户推送 30 首完全没听过的歌曲。同时,它又总能带来非常好的用户体验。截至 2020 年 6 月 25 日,每周发现总共被播放了 23 亿小时,约合 26.65 万年,比人类文明存在的时间还长。
Spotify 是怎么做到这一切的?当然还是算法。
Spotify 主要使用了三种推荐机制——协同过滤算法(Collaborative Filtering Model)、卷积神经网络(Convolutional Neural Networks)和自然语言分析(Natural Language Processing)。
Netflix 是最早使用协同过滤算法来推荐内容的平台。在 Netflix 大获成功之后,这种算法就变得越来越流行。简单来说,它会根据用户之间的相似性而不是内容的相似性来推荐新事物。
对 Spotify 来说,摆在它面前的是一个巨大的数据库,里面装满了用户听过内容的历史。协同过滤算法会根据用户 A 听过的歌曲,找到也喜欢这些歌的另一个用户 B,然后向 A 推送只有 B 听过的歌曲。

“同喜 QRS,则尝试一下 P 和 T”|Erik Bernhardsson,前 Spotify 员工
但协同过滤算法的一大缺点是所谓的“冷启动”问题,只有掌握足够多的数据,协同过滤算法才能起作用。如果用户是一个还没有听过多少歌的新用户,或者内容库里有一首非常冷门歌曲,协同过滤算法就无法精准匹配。
这就引入了另一种算法——自然语言处理。Word2Vec 常被用在自然语言处理中,它可以将我们日常的对话编码成数学关系——向量。
Spotify 做了和 Word2Vec 相似的工作。它会抓取网络上描述音乐、歌曲或者歌手的词语,通过算法分配给它们不同的权重。这个权重,很大程度上代表了人们用这个词来描述音乐的概率。通过自然语言处理,Spotify 就能确定那两首歌彼此是相似的,从而解决冷启动问题。即使是冷门的歌曲或歌手,也能得到推荐。
Spotify 的第三种方式是卷积神经网。
在前两种算法的帮助下,Spotify 已经获得了足够多的数据,但卷积神经网络可以进一步提高了音乐推荐的准确性。
卷积神经网络会分析歌曲的特征,包括拍子、音调、模式、节奏、响度等。通过阅读这些歌曲的特征,Spotify 就可以根据用户的收听历史了解它们之间的相似性,匹配用户的喜好。

Daft Punk 的歌曲“环游世界”的数据分析图|The Echo Nest
正是通过这三种算法,Spotify 像魔法一般猜准了用户的喜好,打造出了千人千面的 Discover Weekly。
但即使 Spotify 已经成为了世界上最流行的流媒体播放软件,即使世界上最聪明的人在这里构建出了无比精巧的算法,过滤气泡的“诅咒”依旧存在。
于是,Spotify,又多做了一步。
但是,人是会变的呀!
2021 年 4 月,Spotify 联合多伦多大学发布了一篇论文《下一步去哪儿?一种用户偏好的动态模型》(Where To Next?A Dynamic Model of User Preferences)。
他们在 4 年间(2016 年至 2020 年)分析了 10 万名用户的收听数据,来观察用户的消费分布变化。他们发现,随着时间的变化,用户的消费习惯也在发生变化。先前的算法擅长捕捉用户的静态喜好,但当面对长时间的跨度时,却无法捕捉用户动态的喜好变化。对于 Spotify 的长期用户来说,他们依旧可能困在过滤气泡中。
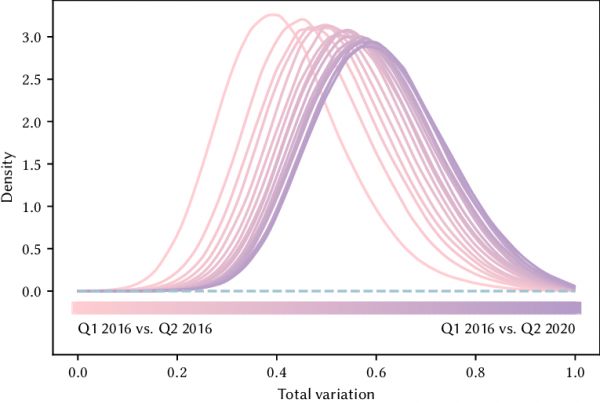
这是 2016 年第一季度对比随后每个季度的总消费变化直方图。颜色越深,对比的时间跨度就越长。比如,最左边的浅色曲线是 2016 年第一季度和 2016 年第二季度的对比;最右边的深色曲线是 2016 年第一季度和 2020 年第二季度的对比。随着时间的增加,变化也越来越明显|图片来源:Spotify
Spotify 同时发现,当免费用户消费的音乐种类越多时,他们越有可能转化为付费用户。也就是说,用户听到的音乐类型越多,他们越喜欢 Spotify。
那么该如何知道,一个人未来的音乐口味呢?Spotify 给出了一个新的算法——偏好转化模型(Prefenrence Transition Model,PTM)。
在这张偏好转化模型的草图中,我们可以大致窥见 PTM 的工作原理。
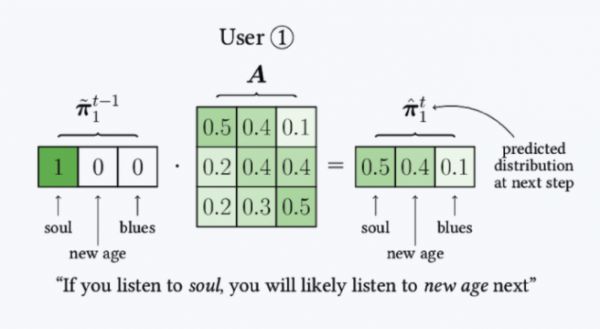
图片来源:Spotify
我们现在有个用户 1 号,根据历史,可以知道他喜欢听灵魂乐(Soul)。我们想知道,他以后会不会喜欢新世纪音乐(New Age)和布鲁斯(Blues)。
转换矩阵 A 是 PTM 的核心,将上述的数据输入 A,就会得到一个预测的结果。可以看到,新世纪音乐的数值(0.5)和灵魂乐(0.4)非常接近,那用户 1 将来很有可能会喜欢上新世纪音乐。
当然,这只是一个最简单的模型演示,实际情况要比这复杂得多。Spotify 总共归纳了 4000 种音乐流派。而在 Spotify 的数据库中,还有有 3.56 亿个这样的“用户 1 号”。

PTM 的核心算法:指数加权移动平均分布和泊松多项式两级分布|Spotify
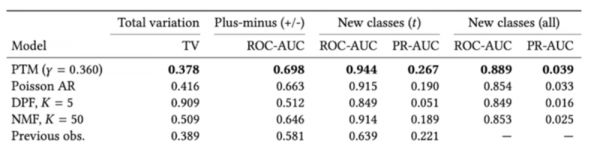
与之前的算法相比,PTM 在各项测试中都得到了最好成绩|Spotify
除了预测性能,PTM 的另一大特点就是可以直观地解释从一种音乐是如何转换到另一种音乐的。假定我们现在有两个音乐流派 a 和 b,PTM 就可以提供用户在听完 a 之后转换到 b 的概率。这就解释了两个问题:
1. a 到 b,哪条路径是最短的?
2. 如果用户听了 a,那么他接下来最有可能播放哪个流派?
回答这两个问题,大大提高了 PTM 的效率和预测准确性。
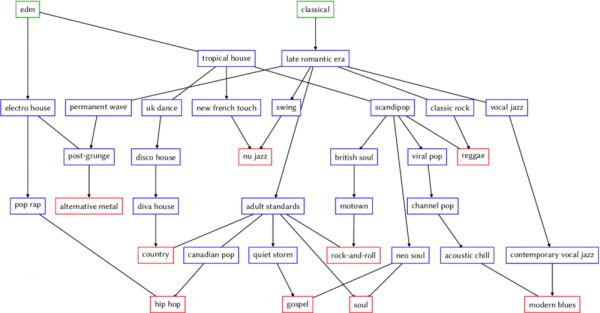
这是一张偏好转化的示意图,显示了初始流派(绿色)到目标流派(红色)的最短路径|Spotify
如何“驯服”算法
看起来,Spotify 已经做得很好了。但再聪明的算法,都可能时不时抽一下风。毕竟,人确实很复杂,没有人可以像你自己一样了解自己。
Spotify 官方也给出了一些建议,希望帮助你更好地“驯服”他们的算法。
给你喜欢的歌曲点个❤️。
如果你不喜欢一首歌,在 30 秒之前跳过它。30 秒是个关键节点,如果在这之前跳过一首歌,相当于算法在内部给它点了“不喜欢”。
听听新的歌手和他们的音乐。这样算法就可以更好地学习你的行为模式。
提供你的年龄和位置信息——要是你不介意的话。Spotify 会根据用户的年龄和地理位置推荐不同的音乐类型。
如果你不想 Spotify 注意到你的行为,可以使用“私密模式”。
最后,保持耐心。算法在设计中会忽略新的收听行为中一些迅速的、突然出现的峰值,因为许多人会分享他们的 Spotify 登录信息。因此新的收听活动可能不会立刻导致你的播放列表变化。
本文来自微信公众号:极客公园(ID:geekpark),作者:汤一涛
相关推荐
年轻人都在“反算法”,Spotify先站出来了
年轻人开始“反算法”
用算法「种」出的草莓里,藏着年轻人与农业的未来
Spotify算法是如何猜出你喜欢什么的?
Spotify:救命稻草还是行业公敌
对话 Spotify 创始人 Daniel Ek(下):董事会、行业生态和瑞典文化等
算法也能当“歌手”,这是什么魔幻事件?
Spotify为何要因为Apple One和苹果杠?影响自家服务销售
Spotify再回怼苹果:“垄断者从不说自己有错”
最前线丨Spotify指责苹果:偏袒自家服务,使竞争对手处于劣势
网址: 年轻人都在“反算法”,Spotify先站出来了 http://m.xishuta.com/newsview44837.html