用大数据理解“玄学”
编者按:本文来自微信公众号“IT时报”(ID:vittimes),作者:郝俊慧,36氪经授权发布。
1.科学数据如何共享和治理?
2.当数据被定位为生产要素和资源,如何在开发利用和开放共享中取得平衡?
3.科学研究“第四范式”的终极目标何时实现?
2007年1月11日,图灵奖得主吉姆·格雷发表了一次演讲“科学方法的革命”,将科学研究分为四类范式:实验归纳、模型推演、仿真模拟和数据密集型科学发现。
吉姆·格雷预测,未来世界上所有的科学文献和科学数据将联机,并且实现互操作。17天后,他驾驶帆船驶向大海,从此再没回来。
14年后,吉姆·格雷没能看到,他的精准预言已部分成为现实:随着海量数据成为新的科学研究基础设施,构造基于数据的、开放协同的研究与创新模式,已是被科学研究者公认的最佳方式。
然而,当科学数据成为科学研究的关键成果和重要的战略性资源,科学数据如何共享和治理?当数据被定位为生产要素和资源,如何在开发利用和开放共享中取得平衡?科学研究“第四范式”的终极目标何时实现?
在6月2日举行的2021浦江创新论坛之新型技术论坛——“数生万物”科学数据创新大会上,与会的全球科学家们从不同角度尝试回答这些问题。
同日,上海市研发公共服务平台管理中心、上海科技创新资源数据中心联合发布《上海科学数据共享倡议书》,建议坚持开放互通原则,构建数据共享体系,建设一批具有学科领先性、数据权威性的科学数据平台和专题数据库,推动上海成为科学数据资源的集散地。
01 大数据时代的科学研究
数生万物时代,科学研究的“第四范式”已被科学家们普遍采用。
“大数据正在成为认识地球的新钥匙、知识发现的新引擎、角色支持的新手段。”中国科学院院士、博士生导师郭华东介绍,在全球可持续发展的科学研究中,大数据已经有了广泛应用。
比如,通过对2015—2019年全球火烧迹地观测数据的分析,郭华东团队得出结论,火烧迹地分布面积、气候变化引起的极端高温和干旱,是导致澳大利亚东部和东海沿海罕见地产生火灾的重要原因。
同样,在对1990—2015年间的冰川模型和气象数据进行模拟分析后,结果显示,全球冰川储量减少6%,相当于全球海平面上升了12毫米。

图源:Pixabay
大到地球,小到个人,大数据都能让人类更加精准地认识对方。
复旦大学类脑智能科学与技术研究院院长冯建峰的研究更加有趣——“科学算命”。通过大规模的医疗健康数据,科学家不仅可以帮人看病、救命,还能预测将来。
在上海浦东张江,有一个3000多平方米的“特殊影像中心”,5台全世界最先进的核磁共振仪器试图“看懂”人类的大脑。每个大脑都被分成10万个小碎片,利用核磁仪器采集到的大规模数据,冯建峰团队通过数据反解,可以将大脑某些部位的变化与实验者的行为一一对应起来。

图源:Unsplash
大数据也让“读心术”成为可能。
比如,抽烟和喝酒如何影响人的行为?答案可能让你大跌眼镜:抽烟会让大脑更加碎片化,而喝酒却会让大脑越来越“一根筋”,只会做一件事,这是“烟酒不分家”的另类科学解释。
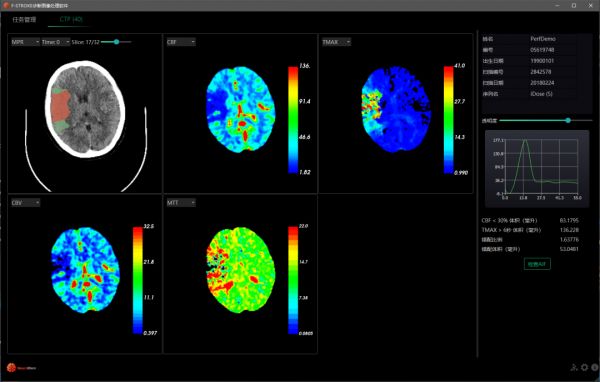
更多“第四范式”的科学研究结果已开始惠及百姓生活,冯建峰团队前几年开发了一款针对脑卒中的软件F-stroke,目前已经在100多家医院应用。
图源:neuroblem.com
中国是全球脑卒中率最高的国家,在脑卒中的治疗方案中,发病时间是非常重要的判断因素:4.5个小时内,可以通过静脉溶栓治疗,而6小时内,则需要机械取栓,但问题是,如果病人半夜发病,早晨被发现,谁知道到底发病多久呢?
通过F-stroke全自动卒中影像处理系统,只要通过拍摄脑部核磁共振,并通过软件进行评估,便基本可以判断病人是不是还适合做溶栓,从而为病人赢得宝贵的抢救时间。
02 数据共享之问
然而,尽管第四范式的优越性已经充分体现,但困扰科学家的普遍问题是,数据从何而来?
2015年8月,一篇发表在《科学》杂志上的心理学实验复现评估论文引发心理学界巨震,研究者选取了社会心理学和认知心理学领域100篇顶尖刊物发表的文章,对其结论的可重复性进行了验证。结果显示,61%的研究是不可复现的。
“不可复现的原因很多,但样本量少应该是其中之一。”中国科学院分子细胞科学卓越创新中心生物信息学平台主任石建涛认为,既然是科学发现,如果有类似数据,就应该能够被验证。因此,如果一开始研究时,就有足够的大样本量进行验证,那科学结论会更加扎实,即便验证,不可复现的可能性也会较低。
冯建峰很羡慕郭华东。和国内有一整套地理大数据不同,在脑科学领域,“国内还没有一套成体系的数据”,但在美国和欧洲国家,已有相当成熟的同类项目。比如英国的UK Biobank数据库,采集了50万人基因的数据,通过这些数据,研究人员能够找到基因组成和变异、行为、环境、种族背景等因素与疾病之间的联系,并确定它们是如何影响医疗结果,而且,这些数据都对国际研究者开放共享。

图源:Unsplash
“国内有些科学家并不愿意将数据拿出来。”一位不愿具名的科学家在接受《IT时报》记者采访时表示,当论文作为科研成果的“指挥棒”时,有些科研机构担心数据共享后,被其他研究者捷足先登,发表论文;还有些研究者担心,自己还没有对采集到的数据做足够深度的挖掘,一旦共享过早,可能会被其他研究者挖掘到数据更大的价值。
多位科学家都向《IT时报》记者提及,全球性的基因图谱绘制工程和基于质谱的蛋白质组学公用数据库,经过10年左右的发展,已经形成相对完善的科技数据共享机制,且有相当成果出现。
据了解,第一批质谱蛋白质组学数据资源建立已超过10年,比较著名的有PeptideAtlas、GPMDB和PRIDE,期间有许多优秀的数据资源陆续出现,对于那些想从海量数据中挖掘新成果的研究者而言,是挖不完的“金矿”。
只是,目前如此规模的全球性数据资源共享项目,仅在某几个科学领域存在,大部分科研工作者依然只能自己采集、分析数据,甚至要自己研发算法做模型分析,科研的资金成本和时间成本,都很难得到质的提升。
03 打造数据银行
2018年3月,《科学数据管理办法》正式发布,科学数据开放共享上升为国家战略。
作为中国科学界的“扛把子”,中科院正在打造一家“科学数据银行”。
论坛上,中国科学院计算机网络信息中心工程师姜璐璐介绍,科学数据银行(ScienceDB)将打造成一个国际化的数据长期共享和数据发布的资源库,并可以确保出版数据的长期管理、持续访问,对于学术界、学术期刊以及出版商等数据的利益相关者,也可以提供配套的数据发布和获取服务。
也就是说,希望在科学期刊上发表论文的作者,可以同步将数据发布在数据银行里,不仅便于编辑对数据进行审核,同时论文的读者也可以找到ScienceDB发表的数据页面,从而获取这篇文章背后的数据。
图源:ScienceDB官网
“国际某些科学期刊已经在尝试这样的做法。”中科院脑科学与智能技术卓越创新中心副主任孙衍刚告诉《IT时报》记者,目前,一些顶尖期刊要求作者在发表前,必须将数据上传至指定平台,其目的之一就是为了推动科学数据的共享。
当日论坛上,两个名词被反复提及,一个是前文提及的《科学数据管理办法》,另一个,则是以欧洲为代表提出的FAIR原则。
“这是两个不同的科学数据治理角度,但最终目标殊途同归。”国家基础学科公共科学数据中心主任胡良霖指出,尽管从字面上看,《科学数据管理办法》重在管理,强调安全可控、充分利用,FAIR原则是指数据“可找寻、可访问、可交互、可在用”,强调发现和利用数据价值,但回溯中国科学研究的历史,愿意拿出数据的中国科学家并不多,国家政策的出台,恰恰是一个推手,从管理的角度将全国科学数据共享工作往前助推了一把。
可喜的变化是,2018年管理办法出台,2019年,中国科学数据中心成立,国内数据管理正在加快落实推进。同时,胡良霖透露,随着ScienceDB逐渐被国际认可,已有很多国外数据在向中国汇聚。
目前,胡良霖正在联合国内20多个国家科学数据中心,希望可以将目前国内已经在用的科学数据使用标准梳理出来,形成中国的科学数据标准白皮书,从而帮助科学家们在采集数据初期便能尽量使用共同标准,为最后数据共享奠定基础。
作者/IT时报记者郝俊慧
编辑/潘少颖 挨踢妹
排版/黄建
图片/IT时报、Pixabay、Unsplash、neuroblem.com、Unsplash、新华社、ScienceDB官网
相关推荐
用大数据理解“玄学”
大数据说话:中小企业正在被“激活”
年轻人痴迷的玄学,是一门好生意吗?
家电企业“去家电”,用改名玄学能到达科技彼岸吗?
爬虫整顿风暴冲击波持续 杭州大数据服务商接连被查
芯片国产化替代加速中,「道合顺」推出元器件大数据查询平台
房晟陶对话赖奕龙:化玄学为工程
中国旅游研究院、携程联合发布“国内旅游复兴大数据报告”
大数据分析和处理的方法
大数据服务商博拉网络:三分之一营收来自汽车客户 新业务拉低毛利率至34%
网址: 用大数据理解“玄学” http://m.xishuta.com/newsview44770.html