英特尔7nm GPU技术细节揭秘:集成超过1000亿晶体管
编者按:本文来自微信公众号“智东西”(ID:zhidxcom),作者:高 歌,编辑:云鹏 ,36氪经授权发布。
3月26日消息,本周三,英特尔的新任CEO帕特·基辛格(Pat Gelsinger)公开了基于7nm的Ponte Vecchio Xe-HPC GPU细节,该GPU将具有1000个执行单元(EU),内核数量超过8000个。
Ponte Vecchio GPU采用了7种关键技术,包含47个Tile,是有史以来尺寸最大、最复杂的GPU。
01. 英特尔新GPU:Foveros 3D封装不同代工厂Tile
英特尔的Ponte Vecchio GPU集成了超过1000亿个晶体管,47颗XPU Tile以及各种制程节点的混搭。这款GPU采用了Xe-HPC图形架构,该架构是基于英特尔7nm EUV节点的旗舰产品。
除此之外,该芯片还有大量基于不同工艺节点的Tile,其中一些Xe-HPC Tile由台积电等外部晶圆代工厂生产。
目前,尚无法确定英特尔是否会采用台积电的7nm或7nm+ EUV工艺节点,但是鉴于台积电代工的Xe Link I/O Tile采用了标准的非EUV 7nm工艺,英特尔可能会继续采用标准7nm工艺。

▲Ponte Vecchio GPU示意图(来源:Wccftech)
英特尔首席架构师Raja Koduri曾经说Ponte Vecchio GPU采用了7项先进技术,技术媒体Wccftech给出了具体名单:
英特尔7nm工艺、台积电7nm工艺、Foveros 3D封装、EMIB(嵌入式多芯片互连桥接)技术、英特尔增强型10nm SuperFin工艺、Rambo Cache(兰博缓存)与HBM2显存。
Raja Koduri也在推特上公布了47颗Tile分别是什么:16颗Xe HPC(internal/external)、8颗Rambo(internal、2颗Xe Base(internal)、11颗EMIB(internal)、2颗Xe Link(external)和8颗HBM(external)。
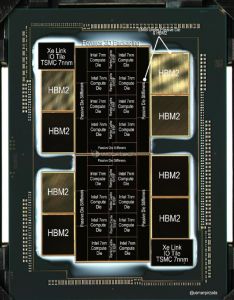
▲Ponte Vecchio GPU各Tile示意图(来源:Wccftech)
Ponte Vecchio实际上由两个独立GPU芯片组成,每个GPU包含六个Xe-HPC计算单元。
一对Xe-HPC计算单元直接与兰博缓存相连,兰博缓存采用了英特尔增强型10nm SuperFin工艺。
每个GPU还连接了四个HBM2显存,HBM2采用4Hi或8Hi堆叠(可以简单理解为4层或8层)。一共八个HBM2可以提供多GB的内存容量和带宽负载。此外,每个GPU上还有8个Passive Die Stiffeners。
总体来说,英特尔Xe HPC这款MCM结构GPU处理器使用了最先进的Foveros 3D封装技术,将多个来自不同代工厂,使用不同工艺制作的Tile集成在一个平台上,EMIB技术则将HBM2、Xe Link I/O等Tile与GPU互连。
所有这些整合形成了Ponte Vecchio Xe-HPC GPU,Raja Koduri发布了一个有趣的乐高示意图,其中显示了Ponte Vecchio GPU的各个Tile。

▲Raja Koduri推特上的乐高示意图(来源:Wccftech)
02. 执行单元数量将超1000,提供40倍双精度浮点算术能力
英特尔此前曾介绍过,其Xe-HPC GPU将具有1000个执行单元(EU)。到目前为止,Xe LP有96个EU,它们构成了总共768个内核。
新GPU的每个子层(subslice)有8个EU。第12代GPU中的subslice类似于英伟达SM单元或AMD的CU单元。
而在英特尔的9.5和11代GPU上,每个subslice具有8个EU,因此如果12代保持相同的层次结构,人们将能看到大量由subslice组成的超级切片。从目前的图片上看,英特尔第12代GPU将有8个算术逻辑单元(ALU),与11代和9.5代保持一致。
大致来说,一个GPU芯片将有1000个EU单元,8000个内核,而实际内核数量还要更多。而Xe HP GPU的HPC尺寸也将更大。
Wccftech列出了英特尔GPU的实际EU单元、对内核数量的估计。功率和TFLOPS(每秒浮点运算次数)等数据:
英特尔Xe HP (12.5) 2-Tile GPU:1024个EU单元,8192个内核,20.48 TFLOPS,1.25 GHz,300W;
英特尔Xe HP (12.5) 4-Tile GPU:2048个EU单元,16384个内核,36 TFLOPS,1.1 GHz,400W-500W。
英特尔Xe类GPU具有下面几种可变矢量宽度(vector width):SIMT(GPU)、SIMD(CPU)、SIMT+SIMD(最高性能)。
Raja Koduri谈到,英特尔的Xe HPC GPU能够扩展到1000个EU,EU通过几个高带宽内存通道与XE内存结构相连,并且每个EU单元都进行了升级,可以提供40倍的双精度浮点计算能力。
兰博缓存则将在整个双精度工作负载中提供可持续的FP64计算性能。
就工艺优化而言,以下是英特尔针对7纳米工艺节点的一些关键改进:
1、相较10nm节点具有两倍的密度缩放优势;
2、内部的节点优化;
3、DR(Design Rules)的4倍缩减;
4、采用了EUV光刻技术;
5、新一代Foveros和EMIB封装。
英特尔的Ponte Vecchio GPU将首先在Aurora超级计算机中使用,并于今年的晚些时候实现量产出货。
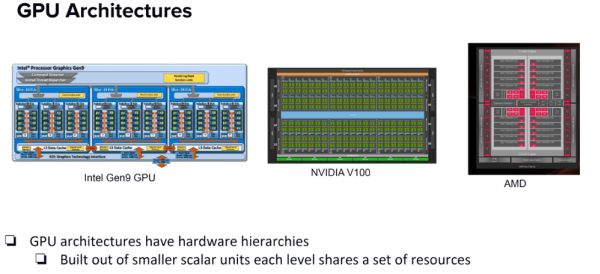
▲英特尔9代GPU与英伟达V100、AMD GPU的架构比较(来源:Wccftech)
在HPC(高性能计算)领域,英特尔Ponte Vecchio GPU将与英伟达的Ada Lovelace和AMD的CDNA 2图形架构竞争,Ada Lovelace和CDNA 2也将使用类似的设计。
03. 结语:英特尔GPU版图扩大,GPU市场又起波澜
相较于英特尔的CPU内核,其GPU的市场关注度一直比较低。本次英特尔花费2年时间打造出了这款Ponte Vecchio GPU,可能将是英特尔扩展GPU版图的重要一步。
前文提到的Aurora超级计算机由美国能源部与英特尔联手打造,是Ponte Vecchio GPU推广中的重要一步。但是英特尔的GPU版图能否成功扩充,还是要看Ponte Vecchio GPU与英伟达、AMD等公司GPU产品的竞争情况。
来源:Wccftech
相关推荐
英特尔7nm GPU技术细节揭秘:集成超过1000亿晶体管
跳票数年,英特尔10nm终现身:SuperFin重新定义晶体管架构,节点内性能提升超过15%
英特尔的7nm失败了吗
台积电市值超过英特尔,昔日霸主英特尔走到三岔口
下一个倒下的会不会是英特尔?
焦点分析 | 股价回10年高点,重新设计7nm,英特尔转型关键点
2020年新iPhone揭秘:大招来了
历史性时刻:英伟达市值反超英特尔
你追我赶的英特尔和台积电
AI芯片大战背后:英特尔对英伟达虎视眈眈,国内芯片公司蠢蠢欲动
网址: 英特尔7nm GPU技术细节揭秘:集成超过1000亿晶体管 http://m.xishuta.com/newsview40831.html