我们给AlphaGo做了一次智商检测,结果发现……
题图来自视觉中国,本文来自微信公众号:格致论道讲坛(ID:SELFtalks),作者:刘锋,《人工智能学家》主编,《互联网进化论》作者
人工智能爆发的今天,特别是AlphaGo 战胜了人类,获得了世界冠军,这让大家有些困惑,甚至是恐慌,人工智能会不会超越人类,甚至成为主宰?
关于这个问题众说纷纭。
包括霍金、马斯克在内的很多人提出了人工智能威胁论。
如果要在科学上解决这个问题,我们需要找到一个定量的方法,去分析人工智能与人类智力的发展水平。
最著名的人工智能测试是图灵测试。

但图灵测试主要是评价一个智能系统能否达到人类的智能水平,并不能够定量分析智能系统与人类智能的关系。
一、定量评价智能系统的智能水平
从2012年左右开始,我和科学院的石勇教授、刘颖教授对这个问题进行了持续研究,试图寻找一个新的能够定量分析这个问题的方法。

这是我们在2007年开展的研究项目。当时判断整个互联网正向着与人类相似的类大脑结构进化的方向发展,并提出了这个模型。
在2012年的时候,我们最初希望去测试一个类大脑系统的智商。
但是经过两年的研发,最终从类大脑系统的智能智商评测转变成AI通用的智商评测,这个转化包含了互联网和人工智能关系。
为什么在很长时间里没有关于AI定量的分析?
主要面临两个困难,第一是人工智能系统没有形成统一的模型,第二就是人工智能系统与以人类为代表的生命体之间没有形成统一的模型。
通俗地说,人类和AlphaGo机器人、IBM的Watson系统等很多的智能系统之间没有一个统一的模型,告诉我们在智能方面有什么共性。
没有这样的模型,就没有办法持续深入下去做定量分析,然后评判到底谁优谁劣。
我们在2012年开始研究的时候,困惑了我们长达两三年。
我们也大量的研究了前人的分析结果。
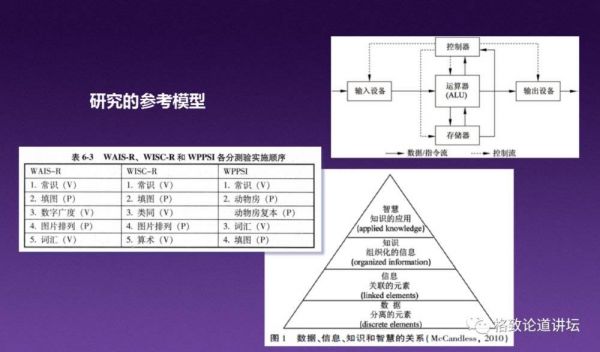
第一,首先会想到人类的智商和评测。但是我们发现,人类的智商和评测不能直接作为AI的智商评测。
譬如韦特斯勒的评测方法,主要是常识的评测和动手能力,但是很多智能系统连机械臂没有,没有办法进行评测。
但是韦克斯勒的方法给我们一个启发,就是我们的智力不是单一的要素,它有很多子要素组成,比如常识能力、计算能力、动手能力等等。
第二个给我们启发的是AI领域和计算机领域中著名的冯诺依曼架构。
它启示我们,智能系统应该有智能的输入输出和存储能力。
第三,就是知识管理里面比较著名的KIDW模型,它启示我们人类的智慧里面最顶级、最重要的能力是创新能力,而不是我们平时的数据、掌握的信息或者知识掌握多少。
基于前沿研究,我们团队在2014年发表了第一篇论文,提出了标准的智能模型,认为任何一个智能模型同时具备知识的输入、输出、掌握和创新能力。
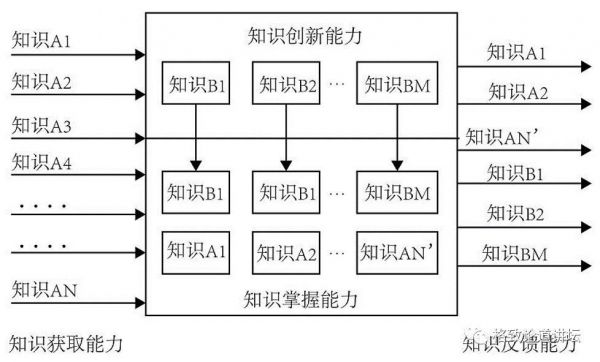
任何一个智能体是这四个方面的组合,只是能力强弱不同而已。
比如老鹰看的更远,它识别的更清晰。
像IBM的Waston系统掌握常识能力很强,这就是为什么跟人类的对抗里面它能获胜。
AlphaGo 也是这样,在人类特定的规则之下,它掌握了规则并战胜人类,这也是一种知识掌握的能力。
更为重要的是创新能力。
比如伟大的科学家牛顿看到了苹果落到地上,发现了万有引力。
门捷列夫在睡梦中想出元素周期表,这些是人类原生出来的创新知识。
这反映出智能系统在不同的智力方向上强弱不同,我们希望用这一套模型去寻找智慧统一模型。
如果把智慧模型和著名的冯诺依曼架构做了关联,可以看到以红线划出来的方框。
给冯诺依曼架构加上创新发生器和云端共享知识库,冯诺依曼架构就可以从计算机的模型、AI模型转变成把人类囊括进去的模型。
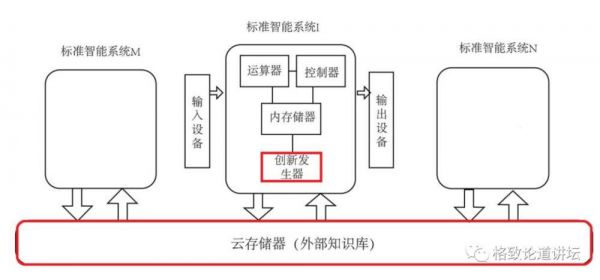
基于以上的研究,我们在2014年发表的论文里面,基于标准智能模型四个大的领域,又模仿、学习韦克斯勒的结构,把它又拆分成20多个智慧的子系统。
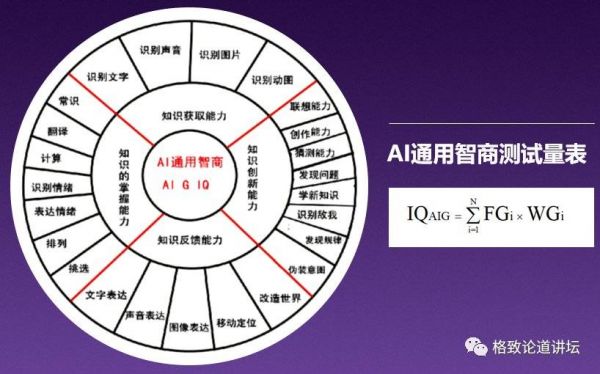
上图中,可以看到输入和输出,包括图像的识别和输出、声音的识别和输出、文字的识别和输出。
像我们掌握的常识,包括计算能力、翻译能力、分类能力等,这些划分为知识的掌握能力。
更为重要的,就是知识的创新能力,可以看到拆分成了若干个重要的分类,譬如发现规律、创新创造能力、猜测预测能力,甚至包括能够识别敌我能力、撒谎的能力。
这些能力往往会被我们忽略,震惊于AlphaGo的能力,震惊于IBM Waston系统能力,但是这些创新创造能力也许是我们人类真正重要的部分,而且还没有概括完全,还有一些更深层次的创新能力。
然后,我们基于专家的打分法——德尔菲法,对整个子元素授予它的权重,形成了可以定量测试的方法。
二、智能系统的智能水平测试结果
在2014年和2016年,我们分别对像Google系统、Siri系统,还有6岁儿童、12岁少年、18岁的成人进行了测试。

当时测试的人工智能系统比较多,只列出了前十位的名单。
大家可以看到,2016年人工智能增长确实比较快,但是跟6岁的儿童相比依然有相当的差距。
两年的测试过程显示,虽然人工智能有很快的增长,但是在最重要的知识创新领域,依然进展非常缓慢。
大家也许提问,AlphaGo 的智商怎么评测呢?
比如,我们把它下棋功能放在知识掌握部分,并为其赋予权重。
但是我们发现AlphaGo在其它方面很弱,甚至创始人被称之为AlphaGo的人肉手臂,因为它连下棋的能力没有,还要靠人类帮它下棋。
当然,其它的猜测能力、判断能力、区别敌我能力,AlphaGo是不具备的,只在下棋这个局部领域非常强大。
如果对AlphaGo进行综合智商评测,它的得分非常低。
我们所表达的含义,就是从科学的角度看,人工智能想威胁到人类其实还非常远。
我们的这项研究在2017年10月份也得到世界范围内的关注,像麻省理工科技评论、CNBC以及日本、欧洲和中东的媒体,对这项研究给予了报道。
但是这项研究依然处于起步的阶段,它背后包括大量的科学问题还需要我们探索,希望将来能把最新的进展向大家进行汇报。
本文来自微信公众号:格致论道讲坛(ID:SELFtalks),作者:刘锋,《人工智能学家》主编,《互联网进化论》作者
相关推荐
我们给AlphaGo做了一次智商检测,结果发现……
加拿大新冠肺炎快速检测盒被发现检测结果不可靠
DeepMind新成果:让AI做了200万道数学题,结果堪忧
人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
百度正用谷歌AlphaGo,解决一个比围棋更难的问题
那个AlphaGo背后的男人,获得2019 ACM计算奖
十分好读 |《人工智能全球格局》:赢了柯洁的AlphaGo,依然算不上人工智能吗?
AI能判断性取向?不服气的我做了个实验,结果……
世界智能手机AI智商测试发布,苹果、华为、三星排名前三
Facebook首届Deepfake检测挑战赛结果:准确率65.18%
网址: 我们给AlphaGo做了一次智商检测,结果发现…… http://m.xishuta.com/newsview31230.html