北大图灵班本科生带来动画CG福音,“最懂骨骼的卷积网络”,无需配对样本实现动作迁移
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者 鱼羊 金磊,36氪经授权发布。
我有一个动画形象,我有一套人体动作,可想要把它们组合成真正的动画,可不是 1+1 这么简单。
别看这体型迥异的三位动作整齐划一,支撑动画的骨架却差异甚大。
这也就意味着,想给新的动画角色套上已经做好的动作,依然需要对骨骼进行重构,费时费力。
好消息是,来自北大和北京电影学院的最新研究,正在化繁为简。
根据这项研究结果,从左到右,一个动作迁移深度学习框架就能解决,并且,不需要任何配对示例。
也就是说,现在,同一个动作可以被更轻松地应用于不同的形象了。
这篇论文中了计算机图形学顶会SIGGRAPH,代码现已开源。
论文一作,分别是北京电影学院研究科学家Kfir Aberman,和北大图灵班大三本科生李沛卓。
对于这一成果,论文通讯作者陈宝权教授诙谐地表示:这是最懂骨骼的卷积网络。
而且据说,论文和代码发布之后,就有相关工业界公司来跟研究团队接洽了。
所以这究竟是怎样一个“骨骼惊奇”的神经网络?
最懂骨骼的卷积网络
论文的主要技术贡献,是提出了全新的骨骼卷积和骨骼池化算子。
这些算子都是骨骼感知的,也就是说,它们能显式地考虑骨骼的层次结构和关节的邻近关系。
据作者李沛卓介绍,由于骨骼不具有和图片(image)一样规整的结构,但又拥有相对于一般的图(graph)更特殊的结构,新算子的设计亦是整个研究过程中最棘手的环节。
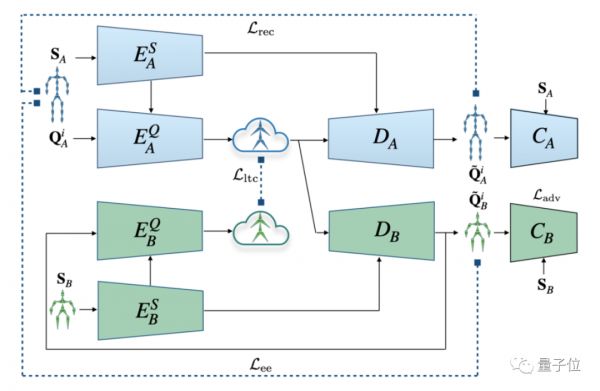
研究人员使用静态骨骼位置+动态关节旋转来表示骨骼上的动作,并把不同骨骼之间的动作迁移视作无配对的域转移任务,将动态静态部分分别处理,构建了用于同胚骨骼之间无需配对示例的动作迁移深度学习框架。
框架结构类似于GAN,包含两对自动编码器构成的生成器,在共同的隐空间中实现不同骨骼之间的动作迁移。还引入了判别器,以提高生成结果的质量。
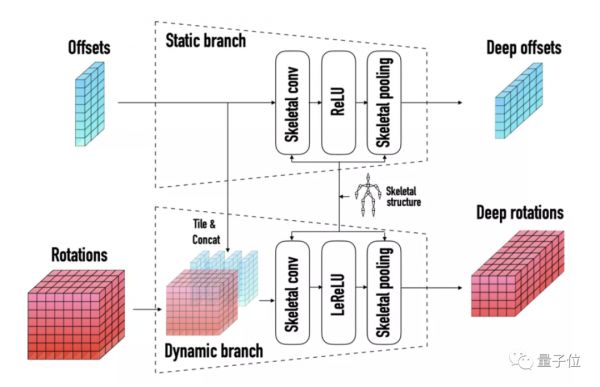
在这其中,研究人员利用骨骼卷积算子来充分利用骨骼的拓扑结构。
具体而言,在对一个关节及其对应的单个骨骼做卷积时,将其所有距离为 d 的邻接骨骼对应的通道提取出来。同时将静态部分和动态部分的通道进行拼接,进行时间轴上的1维卷积。
骨骼池化,则是将不同拓扑不同的同胚骨骼合并到一个公共基本骨骼的过程。
研究人员介绍,这是不同骨骼的自动编码器能达到统一隐空间的基石。
效果更“服帖”
那么,“骨骼如此惊奇”的神经网络,效果如何?
接下来,我们就一起看下与其它方法比较的结果。
这个运动处理框架,是在Pytorch中实现,实验是在配备了NVIDIA GeForce GTX Titan Xp GPU(12 GB)和Intel Core i7-695X/3.0GHz CPU(16 GB RAM)的PC上进行的。
在做测试时,编码器的输入是源动作,而解码器的输入,是编码器输出的隐变量和目标骨骼信息。
而后,根据目标骨骼的拓扑结构选择相应的解码器,得到迁移后的动作。
主要做比较的方法包括:CycleGAN和NKN。
而做比较实验的情况也分为两种:
只使用一个自动编码器,但使用不同的骨骼信息,进行同拓扑骨骼之间的动作迁移。
使用完整的两个自动编码器,实现不同拓扑结构之间的动作迁移。
首先,来看下第一个情况下的比较:同一拓扑结构的源骨骼、目标骨骼。
下图从左至右,依次表示输入、CycleGAN、NKN和研究人员的方法。
不难看出,根据输入的这段鬼步舞,研究人员方法的“贴合度”更高。
另外,是第二种难度更高的情况:不同拓扑结构的源骨骼、目标骨骼。
同样的,从左至右依次为:输入、CycleGAN、NKN和研究人员的方法。
在这种情况下,在小人儿“踉跄”和“打斗”动作中,该方法也完胜CycleGAN和NKN。
看完定性比较,再来看下定量比较。
不难看出,在两种情况下,都达到了最优。
北大大三本科生一作
这篇SIGGRAPH论文,有两位共同一作。
其中一位,是北大图灵班大三本科生李沛卓。

李沛卓毕业于重庆一中,2016年入选重庆信息学竞赛省队,2017年以高考总分687分的成绩,北大信息科学与技术学院录取。
目前,李沛卓师从陈宝权教授,研究方向是深度学习和计算机图形学,正在北京大学视觉计算与学习实验室和北京电影学院未来影像高精尖创新中心(AICFVE)实习。
另一位,是北京电影学院AICFVE的研究科学家Kfir Aberman。
他博士毕业于以色列特拉维夫大学,现在从事深度学习和计算机图形学研究。在今年的SIGGRAPH 2020上,他有两篇一作论文入选。
另外,据论文通讯作者陈宝权教授透露,今年的SIGGRAPH上,“亮相”的北大本科生还不止李同学一位:
李沛卓(图灵班17级)、翁伊嘉(图灵班17级)、倪星宇(图灵班16级)、蒋鸿达(博士19级)四位同学与国内外学者合作……相关成果将发表在7月份的 SIGGRAPH 会议。
因为疫情,今年的 SIGGRAPH 会议改为在线,第一次“出道”的四位同学遗憾不能现场享受传统的视觉盛宴。基于 SIGGRAPH 的创意基因,这次虚拟会议更值得期待。
而作为一名本科生,拿到顶会论文是相当不容易的事情,在我们专访李沛卓时,他表示:
作为一个大三学生能收获一篇SIGGRAPH是很幸运的。
一方面有我自己努力的成果,但更重要的是我们团队中教授以及学长的帮助指引和付出。
我对图形学本来就特别感兴趣,能收获这篇论文更加鼓励了我继续这方面的研究。
后生可畏,后生可畏啊。
最后,也祝愿几位同学,在科研的道路上再创佳绩~
传送门在此:
项目地址:https://deepmotionediting.github.io/retargetinghttps://github.com/DeepMotionEditing/deep-motion-editing
中文版论文:https://mp.weixin.qq.com/s/Af-1RIIuTeVUcl54ixRypA
相关推荐
北大图灵班本科生带来动画CG福音,“最懂骨骼的卷积网络”,无需配对样本实现动作迁移
图灵奖颁给《玩具总动员》打造者,他们是动画特效先驱,奥斯卡得主,图形学集大成者
“数字虚拟人”堪比真人,「原力动画」首次公开硬核科技
人形AI捉迷藏惊煞网友:飞檐走壁纯靠自学,表情丰富还会合作,姚班学霸吴翼参与
中国高校人工智能专业最全院校排名&课程对比
互动动画「石膏岛」,探索互动影游的「混血商业模式」
LSTM之父,被图灵奖遗忘的大神
面向动作捕捉和虚拟拍摄领域,「中科深智」提供实时动画和虚拟制作的全工作流解决方案
自主研发无穿戴AI视频动捕技术,「云舶科技」要减少虚拟偶像的制作成本
图灵奖颁给深度学习三巨头,他们曾是一小撮顽固的“蠢货”
网址: 北大图灵班本科生带来动画CG福音,“最懂骨骼的卷积网络”,无需配对样本实现动作迁移 http://m.xishuta.com/newsview23848.html