Science子刊:人脑存在加速学习机制,算力赛过最新AI算法
编者按:本文来自微信公众号“新智元”(ID:AI_era),36氪经授权发布。
来源:Science等
编辑:啸林
机器学习虽然受人脑启发,但实验神经科学和ML两个学科已经70年没有沟通。以色列交叉学科团队发现,人脑存在加速学习适应机制,新机制人工神经网络计算能力远超最新AI算法。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
机器学习和深度学习算法的起源,是连接大脑中神经元的突触强度的学习机制,它越来越多地影响着当代生活的几乎所有方面。
半个世纪以前,研究人员试图模仿这些大脑的功能,将神经科学和人工智能联系起来。但是,从那时起,实验神经科学并未直接推动机器学习领域的发展,两个学科一直在相互独立并行发展。
在今天发表在《科学报告》的一篇文章中,研究人员称,他们已经重建了实验神经科学和机器学习之间中断70年的桥梁。

我们大脑的高级学习机制可能会导致更高效的AI算法。图片来源:巴伊兰大学Ido Kanter教授
该研究的主要作者,巴伊兰大学物理系和多学科大脑研究中心的Ido Kanter教授说:“据信,大脑中的学习步骤通常可持续数十分钟甚至更长,而在一台计算机中,则可持续一纳秒,或者说是一百万次快一百万次。”
研究人员着手证明两个假设:一,我们总认为大脑学习非常缓慢,这可能是错误的;二,大脑可能有加速学习机制。
出乎意料的是,两个假设都被证明是正确的。尽管大脑相对较慢,但其计算能力优于典型的最新人工智能算法。

通过在神经元培养上进行新型人工神经网络实验,研究人员首先证明了增加的训练频率会加速神经元适应过程。
这项工作的主要贡献者Shira Sardi表示:“每秒观察10次相同图像的学习效果与每月观察1000次相同图像的效果一样。”
另一位贡献者Roni Vardi博士补充说:“快速重复相同的图像可将我们的大脑适应能力提高到几秒钟而不是几十分钟。大脑的学习甚至可能更快,但这已经超出了我们目前的实验限制。”

其次,研究人员展示了一种受大脑启发的新学习机制。这种机制是在人工神经网络上实现的,其中对于连续学习步骤,局部学习步长会增加
在手写数字的简单数据集MNIST上进行了测试,其成功率大大超过了常用的机器学习算法,例如手写数字识别,尤其是在提供较小型的数据集进行训练的情况下。
实验神经科学与机器学习之间连接的重建,有望在有限的训练示例下促进人工智能(尤其是超快速决策)的发展,对于人类决策,机器人控制和网络优化的许多情况同样适用。
下面,开始论文干货。
论文介绍
突触强度的改变通常持续数十分钟,而神经元(节点)的时钟速度范围约为一秒。尽管大脑相对较慢,但其计算能力优于典型的最新人工智能算法。遵循这种速度/能力悖论,我们通过实验得出基于小型数据集的加速学习机制,这些机制在千兆赫处理器上的利用有望导致超快决策。
与现代计算机不同,定义明确的全局时钟不能控制大脑的运行过程。相反,它们是相对事件时间(例如,刺激和诱发的尖峰)的函数。根据神经元计算,使用经过分支的树突树的衰减输入求和,每个神经元将异步输入电信号求和,并在达到阈值时生成短电脉冲(峰值)。每个神经元的突触强度会根据来自其他突触的相对输入时间进行缓慢调整。如果从突触中感应出信号而没有产生尖峰,则基于与来自同一神经元上其他突触的相邻尖峰的相对时序来修改其关联强度。
最近有实验证明,每个神经元都起着独立阈值单元的作用。信号通过树突树到达后,每个阈值单元都会被激活。另外,基于树突信号到达定时实验上观察到的一种新型自适应规则,这类似于当前归因于突触(连接)的慢速自适应机制。这种树突适应发生在更快的时间尺度上:大约需要五分钟,而突触修饰则需要数十分钟或更长时间。
研究过程
1.实验结果表明,适应率随训练频率的增加而增加。
在这项研究中,研究人员将神经元培养种植在添加了突触阻滞剂的多电极阵列上,这种突触阻滞剂可通过其树突细胞在细胞外刺激这个被膜片钳夹住的神经元。

通过神经元树突在细胞内刺激被研究的神经元,并为每种刺激路径生成不同的尖峰波形。更详尽解释请参阅论文原文“材料和方法”部分。
适应过程包括一个训练集:50对刺激。通过进一步测试神经元刺激的响应时间和强度是否正常,我们量化了神经元适应的效果,确定下来了应该以怎样的细胞外刺激幅度来进行研究。
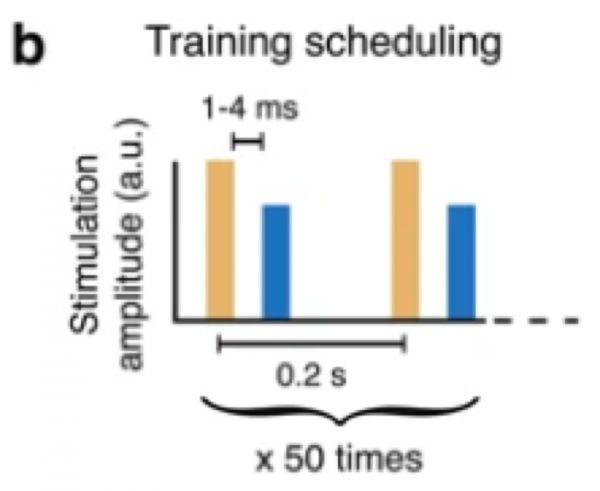
神经元的正常延迟时间:1-4毫秒

为了量化初始反应,降低细胞外刺激幅度,直到未观察到可靠的诱发峰。
2.加速基于生物学启发机制的有监督的可实现学习规则。
与生物学机制的暗示相符合,随着训练频率的增加,适应过程将大大加速,

这可能意味着随时间变化的递减适应步长(等式1):

当前的适应步骤 + 1 d ,等于权重递减的前一个, 代表离散时间步长,0是一个常数,1 /τ代表训练频率,而Δ是一个常数,代表当前训练步骤的增量效果。
使用可实现规则和二进制分类的有监督在线学习,研究了两种情况:突触适应和树突适应:
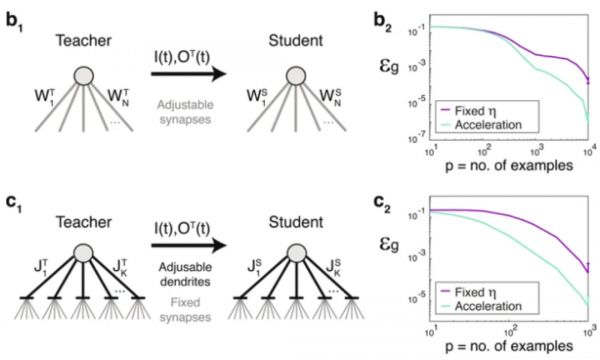
我们首先检查了时间依赖的适应步骤(等式 1)对加速生物学学习过程的影响。Teacher给student提供了异步输入和二进制输出关系,它们都具有最简单的分类器感知器的相同架构,输出节点由泄漏的集成并发射神经元。
结果清楚地表明,泛化误差,ε g的实验启发式的时间相关η(等式 1)基本上胜过固定η情景(上图)。这种加速的学习源于以下事实:突触学习中的权重收敛到极限,权重消失或超过阈值。
3. 使用在神经网络上测试的MNIST数据库,在无法实现的规则的有监督学习中检查了实验启发式的时间相关学习步骤机制。
这个数据库包含大量手写数字示例(如下图),通常用作原型问题,用于量化针对各种图像处理任务的机器学习算法的泛化性能。
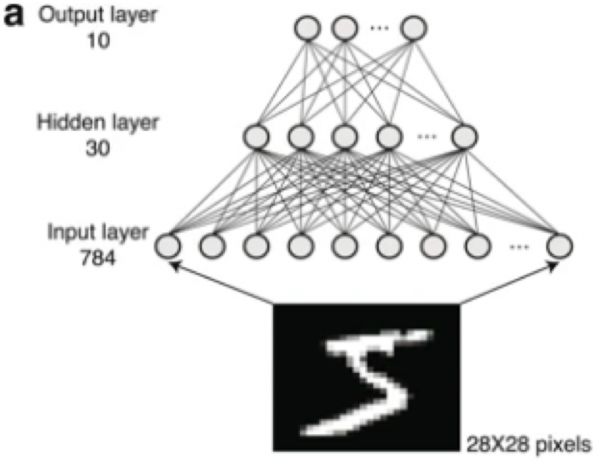
在这项研究中,我们使用MNIST数据库的一小部分,没有任何数据扩展方法。常用的训练网络由784个输入(代表一个数字28×28像素),一个隐藏层(本研究中为30个单位)和十个代表标签的输出(如上图)组成。常用的学习方法是反向传播策略:
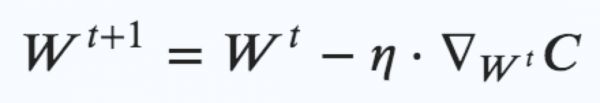
其中将步长上的权重朝着成本函数的梯度负号C的步长η进行修改。一种改进的方法是动量策略和权重的正则化(上图为等式2):
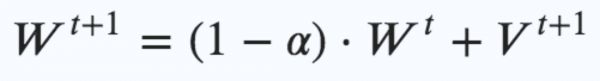

动量μ和正则化α在区域[0,1]中是常数,并且 0η0是一个常数。
我们优化了动量策略(等式2)的绩效 ( ,,0)(μ,α,η0) 使用交叉熵代价函数(材料和方法)对有限的训练数据集进行了比较,并将其性能与以下两种由时间相关的η组成的实验启发式学习机制进行了比较。
论文中对加速度还有更详细的公式给出,篇幅所限,本文就不做更多介绍了。
结果:在线训练集由300个随机选择的示例组成:每个标签以随机顺序出现30次。经过300个学习步骤,加速方法的性能优于动量法超过25%,测试精度分别从约0.43提高到0.54。
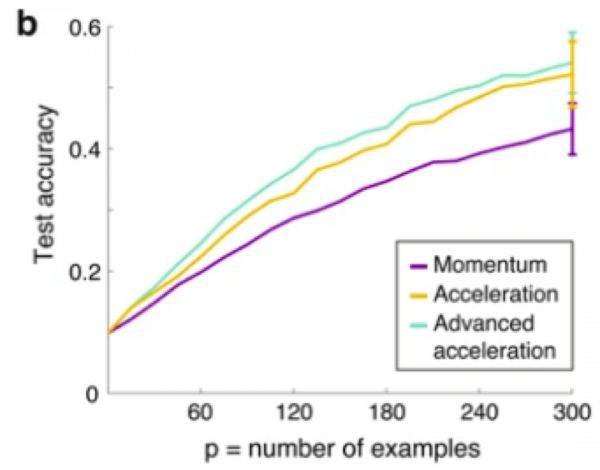
对于给定数量的网络更新,结果表明,较小的示例集可产生更多信息。为了最大程度地提高在线场景(尤其是小型数据集)的测试准确性,平衡的示例集和平衡的时间训练顺序是重要的组成部分。
论文结论
基于连贯的连续梯度增加的η,针对小组的训练示例,脑启发式的加速学习机制优于现有的通用ML策略。在各种成本函数上运行(例如平方成本函数)均会出现一致的结果,但是性能会相对下降(见下图)。
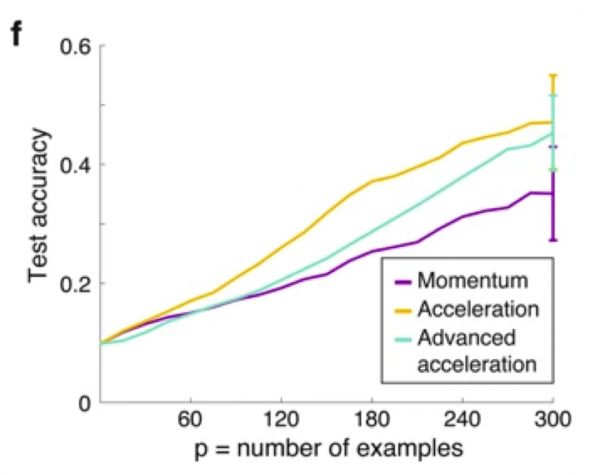
因为给定数据集的最大性能取决于所选的加速方法(见下图),在培训过程中调整学习方法可以提高绩效。
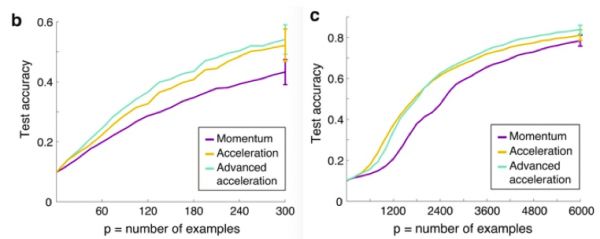
但是,除了可能的用于更新η的高级非线性函数外,在网络更新次数高的情况下,加速方法的最终调度和使性能最大化的受训实例的排序也值得进一步研究。
实验神经科学和ML的桥梁有望进一步推进利用有限的数据库进行决策,这是许多方面的现实:人类活动、机器人控制和网络优化。
本文研究机构
巴伊兰大学缩写BIU,建立于1955年,位于以色列拉马特甘,是一所公立大学,也是目前以色列规模第二大的学术研究机构。
参考链接:
研究人员重建了神经科学与人工智能之间的桥梁:
https://techxplore.com/news/2020-04-rebuild-bridge-neuroscience-artificial-intelligence.html
论文参见:《科学报告》:脑实验暗示适应机制优于通用AI学习算法
https://www.nature.com/articles/s41598-020-63755-5
网址: Science子刊:人脑存在加速学习机制,算力赛过最新AI算法 http://m.xishuta.com/newsview21873.html