霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍
编者按:本文来自微信公众号“新智元”(ID:AI_era),36氪经授权发布。
来源 | arxiv
编辑 | 白峰、鹏飞

【新智元导读】最近,谷歌的研究人员发现神经进化方法非常适合训练基于视觉的强化学习(RL)任务的自注意力结构,使研究人员能够合并一些模块,包括对智能体有用的一些不可微分的操作,从而解决具有挑战性的视觉任务如马里奥赛车,其参数至少降低了 1000 倍。

心理学中有一种现象叫选择性失明,会使人们看不见东西。选择性关注使我们能够专注于信息的重要部分,而不会将精力分散到无关紧要的细节,而谷歌的这篇强化学习论文正是受此启发。
受神经科学启示,发现高效编码方法
关于大型神经网络的泛化性能讨论很多,虽然较大的神经网络比较小的神经网络具有更好的泛化能力,但原因并不在于它们有更多的权重参数。
研究表明,较大的神经网络允许优化算法在允许的解空间的一小部分内找到好的解决方案, 然后可以将这些解修剪成具有有用的归纳偏差的子网络,这些子网络具有较好的推广性。

神经科学家们指出,动物大脑天生具有高度结构化的连接,这种连接过于复杂,无法在基因组中明确定义,必须通过“基因组瓶颈”间接控制,在进化论中有个专门研究领域是关于这一瓶颈的,被称为间接编码。
先天行为是通过间接编码进入基因组的,因此动物大脑中的许多神经元回路是预先连接好的,并且从出生就准备运作。这些与生俱来的能力使得动物更容易适应不同的环境。
谷歌的研究表明,自我注意与间接编码具有相似的属性,即从少量关键查询参数即可生成大量的隐式权重矩阵。间接编码方法允许大型神经结构具有表达能力,同时最小化自由模型参数的个数。我们相信间接编码的工作所奠定的基础可以帮助我们更好地归纳偏差。
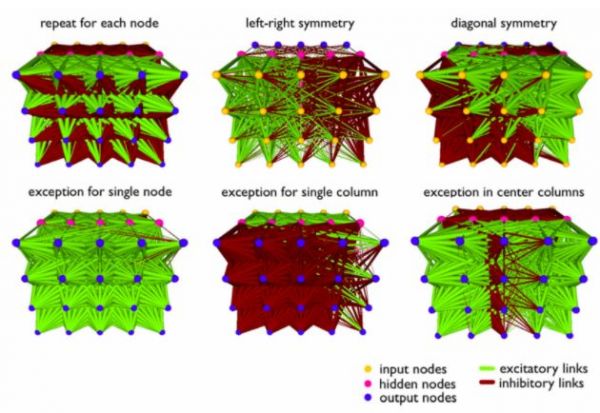
目前大多数用于训练神经网络的方法,无论是梯度下降法还是进化算法,都旨在求解给定神经网络的每个单独权重参数的值。我们将这些方法称为直接编码方法。而间接编码提供了一种完全不同的方法。这些方法针对一小组规则或操作(称为基因型)进行优化,这些规则或操作可以指导生成(大得多的)神经网络。
通过对参数较少的大型模型的权值进行编码,我们可以大大缩小解空间,而代价是我们的解空间被限制到了一个很小的子空间。我们将这种编码方法融入到我们的智能体中,从而得到一个归纳偏差,这个偏差决定了它擅长什么。
试水马里奥赛车
为了验证这种编码方法的有效性,我们在两个具有挑战性的、基于视觉的 RL 任务中进行评估:CarRacing 和 DoomTakeCover。
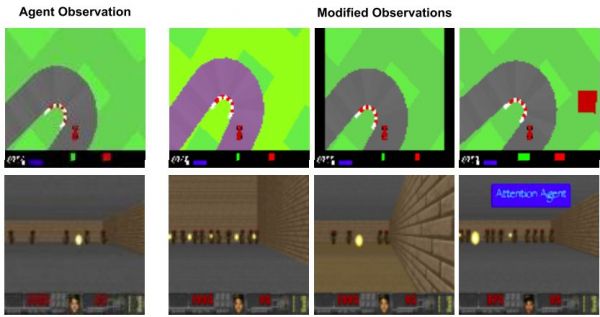
左:原始任务。观测值将调整为 96x96px,并输入给智能体。右:修改后的赛车场环境,颜色扰动,垂直框架,背景斑点。修改后的 DoomTakeCover 环境:更高的墙壁,不同的地板纹理,悬停文字。
在 CarRacing 中,智能体控制红色汽车的三个连续动作(向左/向右转向,加速和制动),以有限的步骤访问尽可能多的随机生成的轨道块。
在每个步骤中,如果没有碰到轨道块,智能体会收到-0.1 分的处罚,但对于其访问的每个轨道块,将获得+ (1000/n)分的奖励,其中 n 是块总数。只要所有的轨道块都被访问,或者 1000 步走完,就算一局结束。
如果 100 次连续测试的平均得分高于 900,则认为 CarRacing 问题已解决。许多研究员尝试使用 Deep RL 算法解决此任务,但直到 David Ha 和 JürgenSchmidhuber 提出《 Recurrent World Models Facilitate Policy Evolution.In Advances in Neural Information Processing Systems 》才部分解决。
DoomTakeCover 是我们进行的另一项任务,在该任务中,智能体必须躲避怪物发射的火球并尽可能长地存活。
每局持续 2100 步,但如果智能体被枪杀,则结束。这是一个离散的控制问题,智能体可以选择在每个步骤中向左/向右移动或保持静止。智能体每一次成功躲避,会获得+1 分的奖励,并且如果 100 局以上的平均累积奖励大于 750,则认为任务已完成。
引入 self-attention 进行数据处理
我们将自注意力机制引入到输入图像的处理,主要经过以下几个步骤:
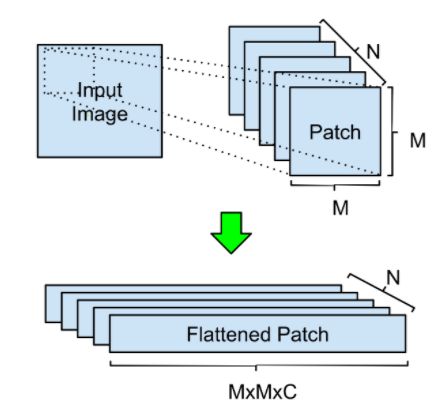
1、经过一些基本的图像预处理之后,使用 m 大小的滑动窗口和 s 大小的滑动窗口对输入进行卷积。输出形状(n,m,m,c) ,其中 n 是 patch 数,m 是每个 patch 的高 / 宽,c 是输入图像中的通道数,然后把数据压平。
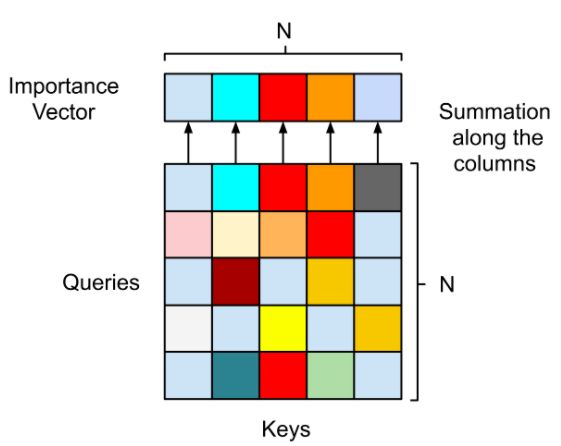
2、得到 keys 和 queries 后,计算他们的注意力矩阵。然后进行 softmax 激活,再将矩阵沿行求和,得到重要性向量。
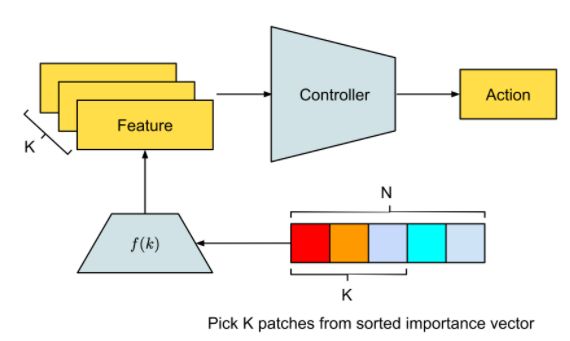
3、对 patch 的重要性向量进行排序,并提取最重要的 k 个 patch 的索引,然后将 patch 索引映射到相应的特征上,并输入给决策控制器以获得下一个动作。
正如人类大脑将大部分注意力分配给任务相关元素,并暂时对其他信号视而不见,智能体学会了忽略输入图像中的任务无关的区域。
不仅达成目标,参数还锐减 1000 倍
结构设计好之后,开始用神经进化算法对自注意力模块和控制器的参数进行训练,神经进化为什么是训练自注意力智能体的理想方法呢?因为神经进化可以去除基于梯度方法的不必要的复杂性,从而使计算更简单。此外,我们还用一些模块来增强自注意力的有效性,下面是实验的结果。
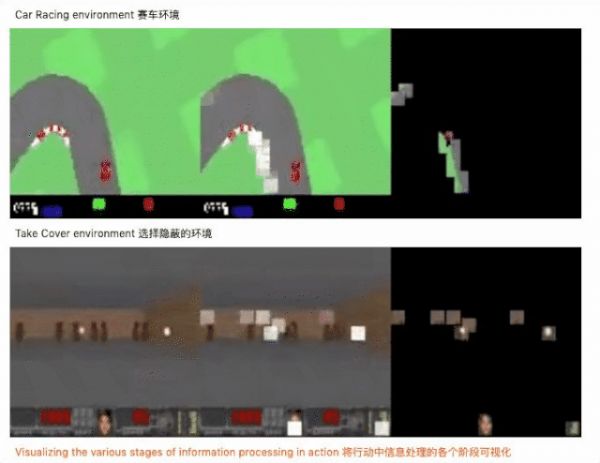
结果显示,经过神经进化训练的智能体,比传统方法需要的参数要少 1000 倍,并且能够解决具有挑战性的基于视觉的 RL 任务。
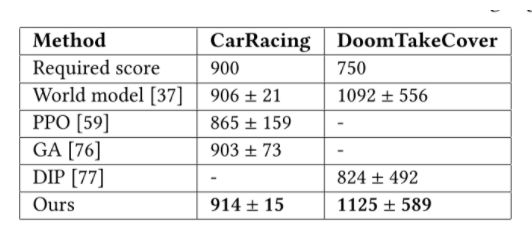
具体来说,在少于 4000 个参数的情况下,我们的自我注意智能体可以在 2D 赛车任务的 100 次连续试验中达到平均分 914,在 3D VizDoom 任务中达到平均分 1125(任务被认为解决了 900 分和 750 分) ,与现有的最先进的(SOTA)结果相当。此外,我们的智能体只关注任务的关键视觉点,因此即使无关要素被修改也能正常工作,而传统的方法可能会失效。
这项研究的目的是展示自注意力如何作为神经进化工具箱的一个强有力的工具,任何人都可以用我们开源的代码复现整个实验。我们希望我们的研究结果能鼓励大家进一步研究自注意力模型的神经进化方法,并重新激发人们对间接编码方法的兴趣。
论文链接:
https://arxiv.org/pdf/2003.08165.pdf
相关推荐
霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍
当AI开始“踢脏球”,你还敢信任强化学习吗?
NeurIPS多智能体强化学习竞赛夺冠的背后,是决策智能公司「启元世界」
非监督强化学习Get新技能:谷歌DADS算法助力智能体实现多样化行为发现
启元发布智能体训练云平台 旗下AI战胜星际争霸全国冠军
高薪挖“神经科学家”,苹果、谷歌想从动物身上汲取AI灵感
20条理由告诉你,为什么当前的深度学习成了人工智能的死胡同?
当智能体具备生命体征时,超级人工智能将给人类带来什么?
对话深度学习奠基人特伦斯:AI的进化动力与终极限制
机器学习圣杯:图灵奖得主Bengio和LeCun称自监督学习可使AI达到人类智力水平
网址: 霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参数锐减1000倍 http://m.xishuta.com/newsview19753.html