刚刚,Facebook把服务27亿人的AI硬件系统开源了

本文转自微信公众号:机器之心(ID:almosthuman2014),由机器之心编译
一直以来,社区对 Facebook 的硬件研究比较关注。在今日的开放计算项目全球峰会上,Facebook 技术策略主管 Vijay Rao 开源了全新的 AI 硬件:面向 AI 训练与推理的硬件系统 Zion 与 Kings Canyon,以及针对视频转码的 Mount Shasta。这篇博客内容对此进行了详细介绍。
Facebook 的基础设施现在每月为其整个应用和服务系统上超过 27 亿的人提供服务。他们的工程师设计并创建了高级、高效的系统来扩大这一基础设施,但是随着工作负载的增长,单靠通用处理器已经无法满足这些系统的需求。晶体管增长的速度已大大放缓,这就需要开发出专门的加速器和整体的系统级解决方案来提高性能、功率和效率。
为基础设施创建高效的解决方案需要共同设计优化了工作负载的硬件。为此,Facebook 一直与合作伙伴共同开发针对 AI 推理、AI 训练和视频转码的解决方案。这几个都是其发展最快的服务。今天,Facebook 发布了其用于 AI 训练的下一代硬件平台 Zion、针对 AI 推理的新定制芯片设计 Kings Canyon 以及用于视频转码的 Mount Shasta。
AI 硬件
AI 工作负载的使用贯穿 Facebook 的架构,使其服务相关性更强,并改善用户使用服务的体验。通过大规模部署 AI 模型,Facebook 每天可以提供 200 万亿次推测以及超过 60 亿次语言翻译。Facebook 使用 35 亿多公开图像来构建或训练其 AI 模型,使它们更好地识别和标记内容。AI 被应用于各种各样的服务中,帮助人们进行日常互动,并为其提供独特的个性化服务。
Facebook 上的大多数 AI 流程都是通过其 AI 平台 FBLeaner 进行管理的,该平台包含集中处理各部分问题的工具,如特征库、训练工作流程管理以及推理机。与设计并发布到 Open Compute Project(OCP)的硬件相结合,这将能够促使 Facebook 大规模、高效地部署模型。从一个稳定的基础开始,Facebook 专注于创建与供应商无关的整合硬件设计,并且为实现工作效率最大化,继续坚持分解设计原则。结果就是 Facebook 推出了用于工作负载训练和推理的下一代硬件。
AI 训练系统 Zion
Zion 是 Facebook 下一代大存储统一训练平台,设计上能够高效处理一系列神经网络,包括 CNN、LSTM 和 SparseNN。Zion 平台能够为其严重的工作负载提供高存储能力和带宽、灵活高速的相连、强大的计算能力。
Zion 采用了 Facebook 全新的、与供应商无关的 OCP 加速模块(OAM)。OAM 形状系数让 Facebook 的合作伙伴(包括 AMD、Haban、GraphCore 和 Nvidia)可以在 OCP 通用规范上开发自己的解决方案。通过单个机架使用 TOR 网络转换,Zion 架构让 Facebook 能够在每个平台上自由扩展到多个服务器。随着 Facebook AI 训练工作负载的规模和复杂性不断增长,Zion 平台也会随之扩展。
Zion 系统分为三个部分:
8 插槽服务器
8 加速器平台
OCP 加速器模块
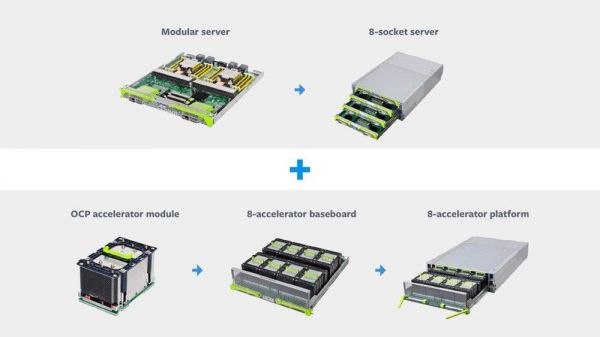
AI 训练解决方案基础模块
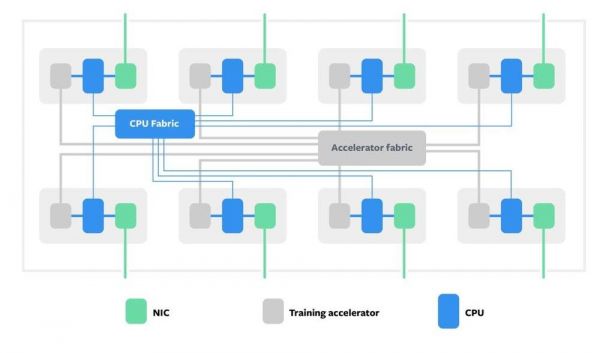
Zion 连接模块图解
Zion 将系统的内存、计算和网络密集型组件分离,使每部分都可单独扩展。该系统为 8 个 NUMA CPU 插槽提供了一个大型 DDR 存储池,以满足工作负载存储容量密集型组件的需求,例如 SparseNN 的嵌入表。对 CNN 或者 SparseNN 密集部分这样的存储-带宽密集型和计算密集的工作负载,每个 CPU 插槽都连接了 OCP 加速模块。
系统有两个高速结构:连接所有 CPU 的相干结构和连接所有加速器的结构。因为加速器存储带宽高但存储容量低,因此通过以这样的方式对模型进行分区来有效利用可用的总存储容量,从而使访问频率较高的数据驻留在加速器上,访问频率较低的数据驻留在具有 CPU 的 DDR 内存上。所有 CPU 和加速器之间的计算和通信都是平衡的,并且通过高速和低速相连有效地进行。
通过 Kings Canyon 执行推理
一旦我们训练完模型,就需要将其部署到生产环境中,从而处理 AI 流程的数据,并响应用户的请求。这就是推理(inference)——模型对新数据执行预测的过程。推理的工作负载正急剧增加,这反映了训练工作的大量增加,目前标准 CPU 服务器已经无法满足需求了。
Facebook 正与 Esperanto、Intel、Marvell 和 Qualcomm 等多个合作伙伴合作,开发可在基础设施上部署和扩展的推理 ASIC 芯片。这些芯片将为工作负载提供 INT8 半精度的运算,从而获得理想的性能,同时也支持 FP16 单精度的运算,从而获得更高的准确率。
整个推理服务器的解决方案分为四个不同的部分,它们会利用已发布到 OCP 的现有构建块。利用现有组件可以加快开发进度,并通过通用性降低开发风险。该设计的四个主要组成部分为:
Kings Canyon 推理 M.2 模块
Twin Lakes 单插槽(single-socket)服务器
Glacier Point v2 承载卡(carrier card)
Yosemite v2 机架
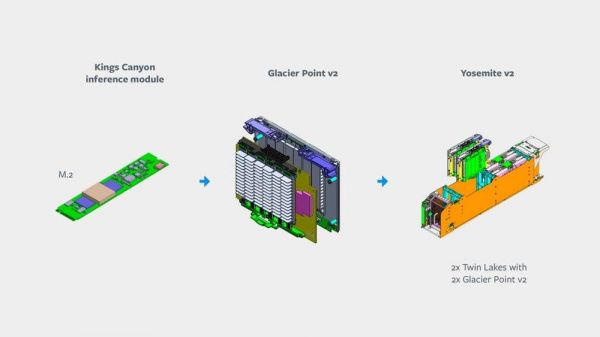
图:AI 推理解决方案模块
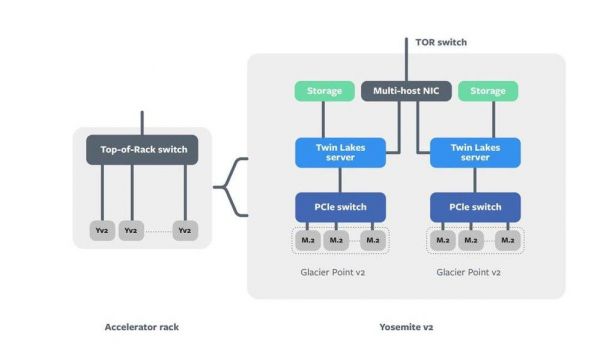
图:AI 推理解决方案连接模块图解
在系统级别,每个服务器都结合了 M.2 Kings Canyon 加速器和 Glacier Point v2 承载卡,后者主要连接到 Twin Lakes 服务器。一般可以将两组前面的组件安装到更新的 Yosemite v2 机架中,然后通过多主机 NIC 连接到 TOR 交换机。更新版的 Yosemite sled 是目前现存 Yosemite v2 sled 的迭代升级,它将 Twin Lakes 主机的其他 PCIe 通道连接到 NIC,以获得更高的网络带宽。
每个 Kings Canyon 模块都包含 ASIC、相关内存和其它支持组件,其中 CPU 主机通过 PCIe 通道与加速器模块通信。Glacier Point v2 包括一个集成的 PCIe 交换机,允许服务器同时访问所有模块。
深度学习模型有很高的储存要求。例如,SparseNN 模型具有非常大的嵌入表征表,它会占用好几 GB 的存储空间,并且还可能会持续增长。这样的大模型可能不适合加载到单独设备的内存中,不论是 CPU 还是加速器都不行,所以这就要求在多个设备内存上进行模型分割(model partitioning)。当数据位于另一个设备的内存中时,分割将产生很多通信成本。因此,好的图分割(graph-partitioning)算法将尝试捕获局部的概念,从而降低通信成本。
通过合适的模型分割,我们可以运行非常大的深度学习模型。例如 SparseNN 模型,如果单节点的内存能力不足以支持给定的模型,我们可以考虑在两个节点中共享模型,并提升模型能访问的内存量。这两个节点可以通过多主机 NIC 连接,并支持高速信息处理。这将增加整体的通信成本,但我们可以利用跨多个嵌入表存在访问差异的事实,相应地对表进行排序而降低通信延迟。
神经网络硬件加速器编译器
ASIC 不运行通用代码,因为它们需要特定的编译器才能将图转化为在这些加速器上执行的指令。Glow 编译器的目标是将供应商的特定硬件从更高级的软件堆栈中抽象出来,使基础设施不受供应商限制。它接受来自框架(如 PyTorch 1.0)的计算图,并为这些机器学习加速器生成高度优化的代码。

Glow 编译器
使用 Mount Shasta 进行视频转码
自 2016 年以来,Facebook Live 直播的平均数量每年翻一番。自 2018 年 8 月在全球推出以来,Facebook Watch 的月浏览量已经超过 4 亿,每天有 7500 万人使用。为了优化所有这些视频,使其能适应多种网络环境,Facebook 生成了多个输出质量和分辨率(或比特率),这个过程称为视频转码。
完成这个转码过程所需要的计算是高度密集型的,通用 CPU 无法满足 Facebook 日益增长的视频需要。为了走在需求的前面,Facebook 与博通和芯原合作,设计为转码负载进行优化的定制 ASIC。
视频转码流程被分解为许多不同的步骤,下面将给出更详细的介绍。这些步骤都是在今天的软件中运行的,所以为了提高效率,Facebook 与供应商合作,为转码工作流程的每个阶段创建了包含专用芯片的定制 ASIC。使用定制化的硬件来完成这些工作负载使得这一过程的能源使用更加高效,并支持实时 4K 60fps 流媒体等新功能。单个视频编解码器是标准化的,而且不经常修改,因此在这种情况下,定制芯片内在缺乏灵活性并不是一个显著的缺点。
视频转码的第一个阶段称为解码,在解码过程中,上传的文件被解压,以获得由一系列图像表示的原始视频数据。然后,可以对这些未压缩的图像进行操作,以更改它们的分辨率(称为缩放),接下来再次使用优化设置进行编码,将它们重新压缩到视频流中。
将输出视频与原始视频进行比较,计算质量指标,这些指标代表了相对于原始上传视频的质量变化。一般所有的视频都采取这种做法,以确保所用的编码设置可以产生高质量的输出。视频编码和解码使用的标准称为视频编码方式;H.264、VP9 和 AV1 是目前使用的主流编码协议。
在 ASIC 上,除了每个软件算法都被芯片内的专用部件所取代外,其他步骤都是相同的。平均而言,Facebook 希望这一视频加速器比其目前的服务器效率高很多倍。他们希望业界的目标编码在 10W 功耗内至少处理 2x 4K 分辨率和 60fps 的并行输入流。ASIC 还需要支持多种分辨率(从 480p 到 60fps 的 4K)和多种编码格式(从 H.264 到 AV1)。
视频转码 ASIC 通常有以下主要逻辑块:
解码器:接收上传的视频;输出解压缩的原始视频流
缩放器(Scaler):缩放解压缩的视频
编码器:输出压缩(编码)视频
质量度量:衡量编码步骤之后的视频质量损失
PHY:芯片与外界的接口;连接到服务器的 PCIe 和内存的 DDR
控制器:运行固件并协调转码流程的通用块
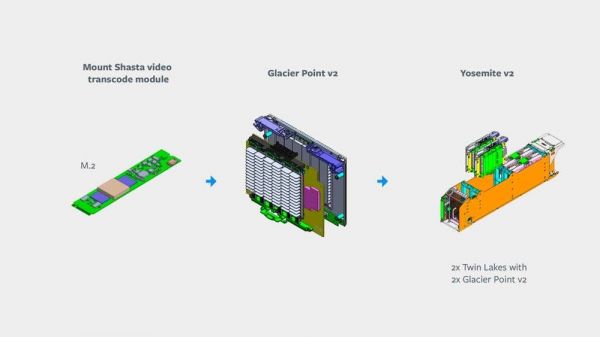
视频转码解决方案基础模块
与推理一样,Facebook 利用现有的 OCP 构件在数据中心部署这些转码 ASIC。ASIC 将安装在带有集成散热器的 M.2 模块上,因为这种常见的电气外形可以在不同硬件平台上重复利用。它们被安装在 Glacier Point v2 (GPv2) 载体卡中,该载体卡可以容纳多个 M.2 模块。这个 GPv2 载体卡具有和 Twin Lakes 服务器一样的物理外形,意味着它可以适配 Yosemite v2 机架,并在其中与 Twin Lakes 服务器配对。
因为转码 ASIC 功耗低、体积小,Facebook 希望通过将尽可能多的芯片与单个服务器相连接来节约成本。高密度的 GPv2 实现了这一点,同时还提供了足够的冷却能力来承受数据中心的运行温度。
一旦完成软件集成工作,Facebook 将平衡分布在不同数据中心位置上异质硬件 fleet 的视频转码工作负载。为了在与各种机器学习和视频空间供应商的合作过程中扩大规模,他们还努力确保软件以开放的形式开发,并推广和采用通用的界面和框架。
相关推荐
刚刚,Facebook把服务27亿人的AI硬件系统开源了
facebook的“硬件开源”启示录
2019年不可错过的45个AI开源工具,你想要的都在这里
Uber竟然把曾炫耀过的自动驾驶可视化软件开源了
AI战「疫」:百度开源业界首个口罩人脸检测及分类模型
旷视为何加入“开源之战”?
关于开源这件事,openEuler到底做得怎么样了?
最前线 | 旷视决定开源AI“生产力工具”,能否比肩谷歌、脸书?
最前线 | 狂发一波产品服务,华为的AI计算生态迈开第一步
为什么在AI领域,不开源会被骂?
网址: 刚刚,Facebook把服务27亿人的AI硬件系统开源了 http://m.xishuta.com/newsview1539.html