语音识别揭秘:你的手机究竟有多理解你?
编者按:本文来自微信公众号“苏宁财富资讯”,作者 沈春泽,苏宁金融研究院金融科技研究中心副主任,36氪经授权发布。
在我们的生活中,语言是传递信息最重要的方式,它能够让人们之间互相了解。人和机器之间的交互也是相同的道理,让机器人知道人类要做什么、怎么做。交互的方式有动作、文本或语音等等,其中语音交互越来越被重视,因为随着互联网上智能硬件的普及,产生了各种互联网的入口方式,而语音是最简单、最直接的交互方式,是最通用的输入模式。
在1952年,贝尔研究所研制了世界上第一个能识别10个英文数字发音的系统。1960年英国的Denes等人研制了世界上第一个语音识别(ASR)系统。大规模的语音识别研究始于70年代,并在单个词的识别方面取得了实质性的进展。上世纪80年代以后,语音识别研究的重点逐渐转向更通用的大词汇量、非特定人的连续语音识别。
90年代以来,语音识别的研究一直没有太大进步。但是,在语音识别技术的应用及产品化方面取得了较大的进展。自2009年以来,得益于深度学习研究的突破以及大量语音数据的积累,语音识别技术得到了突飞猛进的发展。
深度学习研究使用预训练的多层神经网络,提高了声学模型的准确率。微软的研究人员率先取得了突破性进展,他们使用深层神经网络模型后,语音识别错误率降低了三分之一,成为近20年来语音识别技术方面最快的进步。
另外,随着手机等移动终端的普及,多个渠道积累了大量的文本语料或语音语料,这为模型训练提供了基础,使得构建通用的大规模语言模型和声学模型成为可能。在语音识别中,丰富的样本数据是推动系统性能快速提升的重要前提,但是语料的标注需要长期的积累和沉淀,大规模语料资源的积累需要被提高到战略高度。
今天,语音识别在移动端和音箱的应用上最为火热,语音聊天机器人、语音助手等软件层出不穷。许多人初次接触语音识别可能归功于苹果手机的语音助手Siri。
Siri技术来源于美国国防部高级研究规划局(DARPA)的CALO计划:初衷是一个让军方简化处理繁重复杂的事务,并具备认知能力进行学习、组织的数字助理,其民用版即为Siri虚拟个人助理。
Siri公司成立于2007年,最初是以文字聊天服务为主,之后与大名鼎鼎的语音识别厂商Nuance合作实现了语音识别功能。2010年,Siri被苹果收购。2011年苹果将该技术随同iPhone 4S发布,之后对Siri的功能仍在不断提升完善。
现在,Siri成为苹果iPhone上的一项语音控制功能,可以让手机变身为一台智能化机器人。通过自然语言的语音输入,可以调用各种APP,如天气预报、地图导航、资料检索等,还能够通过不断学习改善性能,提供对话式的应答服务。
语音识别(ASR)原理
语音识别技术是让机器通过识别把语音信号转变为文本,进而通过理解转变为指令的技术。目的就是给机器赋予人的听觉特性,听懂人说什么,并作出相应的行为。语音识别系统通常由声学识别模型和语言理解模型两部分组成,分别对应语音到音节和音节到字的计算。一个连续语音识别系统(如下图)大致包含了四个主要部分:特征提取、声学模型、语言模型和解码器等。
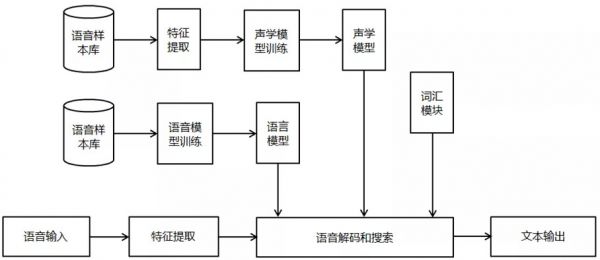
(1)语音输入的预处理模块
对输入的原始语音信号进行处理,滤除掉其中的不重要信息以及背景噪声,并进行语音信号的端点检测(也就是找出语音信号的始末)、语音分帧(可以近似理解为,一段语音就像是一段视频,由许多帧的有序画面构成,可以将语音信号切割为单个的“画面”进行分析)等处理。
(2)特征提取
在去除语音信号中对于语音识别无用的冗余信息后,保留能够反映语音本质特征的信息进行处理,并用一定的形式表示出来。也就是提取出反映语音信号特征的关键特征参数形成特征矢量序列,以便用于后续处理。
(3)声学模型训练
声学模型可以理解为是对声音的建模,能够把语音输入转换成声学表示的输出,准确的说,是给出语音属于某个声学符号的概率。根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数与声学模型进行匹配,得到识别结果。目前的主流语音识别系统多采用隐马尔可夫模型HMM进行声学模型建模。
(4)语言模型训练
语言模型是用来计算一个句子出现概率的模型,简单地说,就是计算一个句子在语法上是否正确的概率。因为句子的构造往往是规律的,前面出现的词经常预示了后方可能出现的词语。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的时候预测下一个即将出现的词语。
它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。
(5)语音解码和搜索算法
解码器是指语音技术中的识别过程。针对输入的语音信号,根据己经训练好的HMM声学模型、语言模型及字典建立一个识别网络,根据搜索算法在该网络中寻找最佳的一条路径,这个路径就是能够以最大概率输出该语音信号的词串,这样就确定这个语音样本所包含的文字了。所以,解码操作即指搜索算法,即在解码端通过搜索技术寻找最优词串的方法。
连续语音识别中的搜索,就是寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。搜索所依据的是对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个高权重,并设置一个长词惩罚分数。
语音识别本质上是一种模式识别的过程,未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。当今语音识别技术的主流算法,主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、以及近年来基于深度学习和支持向量机等语音识别方法。
站在巨人的肩膀上:开源框架
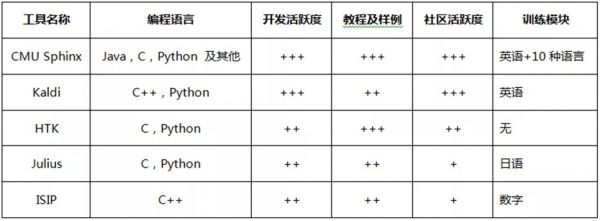
目前开源世界里提供了多种不同的语音识别工具包,为开发者构建应用提供了很大帮助。但这些工具各有优劣,需要根据具体情况选择使用。下表为目前相对流行的工具包间的对比,大多基于传统的 HMM 和N-Gram 语言模型的开源工具包。
对于普通用户而言,大多数人都会知道 Siri 或 Cortana 这样的产品。而对于研发工程师来说,更灵活、更具专注性的解决方案更符合需求,很多公司都会研发自己的语音识别工具。
(1)CMU Sphinix是卡内基梅隆大学的研究成果。已有 20 年历史了,在 Github和 SourceForge上都已经开源了,而且两个平台上都有较高的活跃度。
(2)Kaldi 从 2009 年的研讨会起就有它的学术根基了,现在已经在 GitHub上开源,开发活跃度较高。
(3)HTK 始于剑桥大学,已经商用较长时间,但是现在版权已经不再开源软件了。它的最新版本更新于 2015 年 12 月。
(4)Julius起源于 1997 年,最后一个主版本发布于2016 年 9 月,主要支持的是日语。
(5)ISIP 是第一个最新型的开源语音识别系统,源于密西西比州立大学。它主要发展于 1996 到 1999 年间,最后版本发布于 2011 年,遗憾的是,这个项目已经不复存在。
语音识别技术研究难点
目前,语音识别研究工作进展缓慢,困难具体表现在:
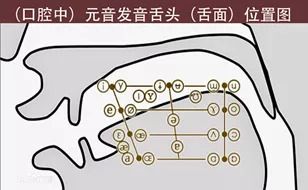
(1)输入无法标准统一
比如,各地方言的差异,每个人独有的发音习惯等,如下图所示,口腔中元音随着舌头部位的不同可以发出多种音调,如果组合变化多端的辅音,可以产生大量的、相似的发音,这对语音识别提出了挑战。除去口音参差不齐,输入设备不统一也导致了语音输入的不标准。
(2)噪声的困扰
噪声环境的各类声源处理是目前公认的技术难题,机器无法从各层次的背景噪音中分辨出人声,而且,背景噪声千差万别,训练的情况也不能完全匹配真实环境。因而,语音识别在噪声中比在安静的环境下要难得多。
目前主流的技术思路是,通过算法提升降低误差。首先,在收集的原始语音中,提取抗噪性较高的语音特征。然后,在模型训练的时候,结合噪声处理算法训练语音模型,使模型在噪声环境里的鲁棒性较高。最后,在语音解码的过程中进行多重选择,从而提高语音识别在噪声环境中的准确率。完全消除噪声的干扰,目前而言,还停留在理论层面。
(3)模型的有效性
识别系统中的语言模型、词法模型在大词汇量、连续语音识别中还不能完全正确的发挥作用,需要有效地结合语言学、心理学及生理学等其他学科的知识。并且,语音识别系统从实验室演示系统向商品的转化过程中还有许多具体细节技术问题需要解决。
智能语音识别系统研发方向
今天,许多用户已经能享受到语音识别技术带来的方便,比如智能手机的语音操作等。但是,这与实现真正的人机交流还有相当遥远的距离。目前,计算机对用户语音的识别程度不高,人机交互上还存在一定的问题,智能语音识别系统技术还有很长的一段路要走,必须取得突破性的进展,才能做到更好的商业应用,这也是未来语音识别技术的发展方向。
在语音识别的商业化落地中,需要内容、算法等各个方面的协同支撑,但是良好的用户体验是商业应用的第一要素,而识别算法是提升用户体验的核心因素。目前语音识别在智能家居、智能车载、智能客服机器人方面有广泛的应用,未来将会深入到学习、生活、工作的各个环节。许多科幻片中的场景正在逐步走入我们的平常生活。
相关推荐
语音识别揭秘:你的手机究竟有多理解你?
TikTok在国外究竟有多厉害?
退出或删除账号仍会“追踪”用户,只有Facebook这样搞吗,隐私究竟有多透明?
揭秘你所不知道的字幕组
冲顶 APP Store,「Spot」究竟有什么社交魔力?
内容审核员成高危职业,互联网的黑暗面究竟有多可怕?
扎克伯格曾销毁的笔记本,究竟有什么秘密?(上)
肖战输了,老罗、黄章也没赢:粉丝们的能力究竟有多大?
朋友圈刷屏的“浪迹情感”被封!PUA究竟有多可怕?
时代呼唤鸿蒙:华为打破魔咒究竟有多难?
网址: 语音识别揭秘:你的手机究竟有多理解你? http://m.xishuta.com/newsview14585.html