罕见,月之暗面杨植麟、周昕宇、吴育昕回应一切:打假460万美元、调侃OpenAI
智东西11月11日报道,今天凌晨,月之暗面核心团队在社交媒体平台Reddit上举行了一场有问必答(AMA)活动,月之暗面联合创始人兼CEO杨植麟等人在Kimi K2 Thinking模型发布后不久,正面回应了模型训练成本、跑分与实际体验差距等热点议题。
Kimi K2 Thinking模型训练成本仅为460万美元的网络传言喊得响亮,不过,杨植麟已经打假了,他称,这并非官方数据,训练成本很难量化,因为其中很大一部分用于研究和实验。他还透露,月之暗面已经在研究K2的VL(视觉-语言)版本了。
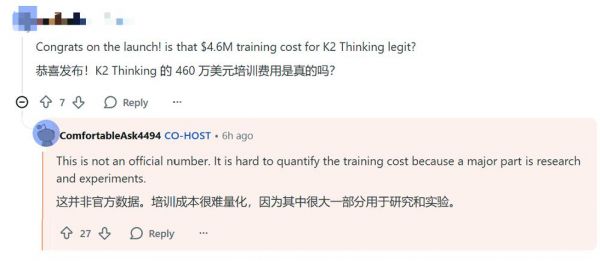
有不少海外网友提出了十分尖锐的问题,比如Kimi K2 Thinking的推理长度过长,榜单成绩与实际体验不符等问题。杨植麟解释了背后的原因,他称现阶段该模型优先考虑绝对性能,token效率会在后续得到改善。榜单高分与实测的脱节,也会在模型通用能力补齐后获得改善。
10月底,月之暗面开源了混合线性注意力架构Kimi Linear,首次在短上下文、长上下文、强化学习扩展机制等各种场景中超越了全注意力机制,引来不少开发者关注。杨植麟称,Kimi Linear的KDA混合线性注意力模块,很可能会以某种形式出现在K3中。
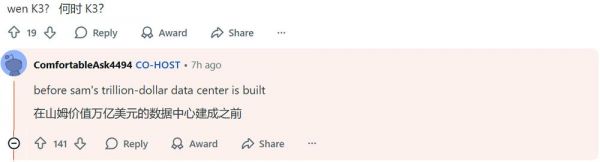
而当网友问及K3的发布时间时,杨植麟戏谑地回应道:“在Sam价值万亿美元的数据中心建成之前。”
月之暗面团队似乎还在另外几条评论中调侃了OpenAI。当网友问及有无AI浏览器的开发计划时,月之暗面联合创始人兼算法团队负责人周昕宇称,要做出更好的模型,并不需要再去套一层新的Chromium壳。而当网友好奇OpenAI为何要烧掉那么多钱时,周昕宇称:“这个问题只有Sam才知道。我们有自己的方式和节奏。”
面对外界关于“开源是否会带来安全风险”的提问,杨植麟回应称,开放安全对齐技术栈有助于更多研究者在微调开源模型时保持安全性,同时他也强调需要建立机制,确保这些后续工作遵循安全协议。
他还在另一条评论中补充道:“我们拥抱开源,因为我们相信对AGI(通用人工智能)的追求,应该带来团结,而不是分裂。”
月之暗面联合创始人吴育昕也一同参与了这场问答,杨植麟、周昕宇、吴育昕围绕Kimi系列模型的架构创新、训练细节、开源策略以及未来规划与网友进行了交流。
01.K2 Thinking现有优先级是性能,独特文风背后有诀窍
在这场活动中,最受关注的焦点是Kimi K2 Thinking模型,这是月之暗面最新发布的开源推理模型。
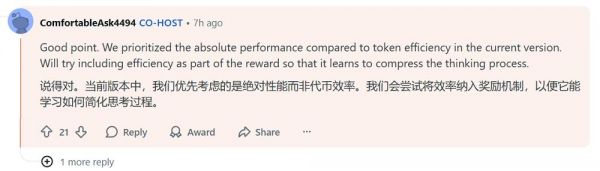
有网友称,自己测试了Kimi K2 Thinking与GPT-5 Thinking,前者的正确率领先,但推理时间更长,像是在不停复查自己。对此,杨植麟称,他们正在积极优化token使用效率。当前版本中,优先考虑的是绝对性能而非token效率。月之暗面会尝试将效率纳入奖励机制,以便它能学习如何简化思考过程。
还有网友质疑,Kimi K2 Thinking是否经过专门训练,以在HLE这一基准测试中取得好成绩?它的高分似乎与实际使用中的智能水平不太相符。
杨植麟回应道,Kimi K2 Thinking在提升智能体推理能力方面取得了一些进展,使其在HLE测试中得分较高。月之暗面正在努力进一步提升其通用能力,以便在更多实际应用场景中充分发挥智能的作用。
另有网友问道:“为何K2 Thinking能在一次推理中保持如此长的思维链,而GPT-5不行?”
杨植麟解释道:“我认为推理时间取决于API吞吐,而推理token的数量取决于模型训练方式。我们在训练Kimi K2 Thinking时倾向于使用更多的思考token以获得最佳效果。我们的Turbo API会更快,同时Kimi K2 Thinking原生采用INT4,这也提升了推理速度。
Kimi K2 Thinking是一款纯文本模型,有网友提问称,这究竟是为了达到SOTA而做出的短期权衡,还是一项长期投资?杨植麟回应,获得正确的VL数据和训练需要时间,因此月之暗面选择先发布文本模型。
Kimi K2系列模型不阿谀奉承、直接的文风在AI界算是一股清流,有不少网友认可这种风格。吴育昕称,这种写作风格是模型后训练数据和评估的重要组成部分。
谈及KDA,杨植麟称,从历史上看,混合注意力在长输入和长输出任务上要超越全注意力一直很困难。KDA在所有维度上都展示了性能提升,包括长思维链RL场景,同时保持了线性注意力的高效性。
另一位网友补充道,希望KDA能结合扩散模型使用。杨植麟认为这一想法是可行的,但文本扩散(text diffusion)比较困难,可能是因为在将扩散应用到文本上时,还没有足够好的先验。
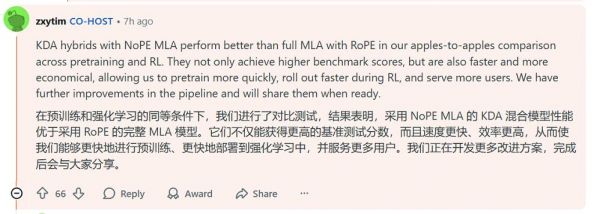
周昕宇在技术层面进一步解释了KDA的对比优势。他称,KDA混合架构结合NoPE MLA后,在预训练和强化学习阶段均优于采用RoPE的完整MLA。不仅基准得分更高,还更快、更经济,使他们能够更高效地训练、部署并服务更多用户。未来,月之暗面还有进一步改进,成熟后会公开。
近期,DeepSeek、智谱都曾发布以视觉方式作为输入,以提升效率的探索。不过,周昕宇称,他个人认为这种方法过于刻意,自己更倾向于继续探索特征空间,寻找更通用、与模态无关的方法来提高模型效率。
此前,月之暗面曾经在模型中采用了Muon作为优化器,网友认为这一优化器相对来说未经测试,这一决定似乎有些疯狂。
周昕宇解释了采用Muon的历程。他称,Muon是一个未经其他厂商测试的优化器,但月之暗面已经用它进行了所有的扩展测试,结果都通过了。他们对自己的研究成果充满信心,网友或许认为Muon只是运气好,但实际上有几十种优化器和架构没有经受住这样的考验。
02.“被封禁”已超出控制范围,上下文窗口将进一步扩展
月之暗面三位联合创始人还集中回应了与模型服务、开源等相关话题的疑问。有网友称,Kimi在自己的公司已经成为主要的测试模型,但生产环境会切换到美国本土的模型。这主要是因为领导层担心Kimi是“中国大模型”,可能存在一些风险。
这位网友还分享,自己很喜欢使用Kimi App,自己一位在亚马逊工作的朋友也很喜欢这一应用,但由于亚马逊有规定必须使用自家的AI助手,禁止在工作场合使用其他主流的AI助手App。网友担心,随着Kimi逐渐变得知名,她会不会再也无法在工作场合中使用呢?
吴育昕回应称:“虽然被“封禁”往往超出我们的控制范围,但开源该模型有望成为消除部分顾虑的有效途径(企业可以自行部署)。我们希望看到一个更加信任的世界,但这需要时间。”
上下文一直是影响AI模型在生产环境应用的重要因素。目前,Kimi K2 Thinking最大支持256K的上下文,有网友反馈这对大型代码库而言并不算大。杨植麟称,月之暗面应该能在未来的版本中增加上下文长度。
还有网友希望月之暗面能将模型上下文窗口提升到100万个token,周昕宇回复道,月之暗面之前已尝试过100万个token的上下文窗口,但当时的服务成本太高。未来他们会重新考虑更长的上下文窗口
当被问及有无AI浏览器的开发计划时,周昕宇十分犀利地回复道:要做出更好的模型,并不需要再去套一层新的Chromium壳。杨植麟称,月之暗面目前将专注于模型训练,但会不断更新kimi.com ,使其包含最新功能。
还有不少网友提到,希望月之暗面能推出规模更小的模型。杨植麟称,Kimi-Linear-48B-A3B-Instruct就是月之暗面发布的小型模型之一,未来他们可能会训练更多模型并添加更多功能。
目前,Kimi已经提供了编程订阅方案,这一计费方式是基于API请求次数,有网友称这种模式导致资源消耗偏高。月之暗面回应称,API请求次数计费能让用户看到费用明细,同时也更符合企业的成本结构。不过,他们会尽快找到更好的方案。
03.结语:中国AI创新能力获得认可
从社区中海外开发者的热烈提问和尖锐反馈可以看出,以Kimi系列为代表的中国模型正受到前所未有的关注。
月之暗面此次在Reddit平台的公开问答,集中回应了全球网友对Kimi技术细节的大量兴趣和疑问。这种关注背后,也折射出全球开发者对中国AI创新能力的认可。
本文来自微信公众号“智东西”(ID:zhidxcom),作者: 陈骏达,编辑:云鹏,36氪经授权发布。
相关推荐
罕见,月之暗面杨植麟、周昕宇、吴育昕回应一切:打假460万美元、调侃OpenAI
DeepSeek风暴里的月之暗面
月暗杨植麟,并没有回应一切
消息称AI创业公司月之暗面将获蚂蚁、阿里投资,估值15亿美元
晚点独家丨月之暗面探索 o1,跟字节抢来华为刘征瀛
月之暗面估值240亿,创始人却被前投资人告上国际仲裁庭
月之暗面创始人杨植麟被前投资人提起仲裁,称将提出抗辩
月之暗面创始人杨植麟被前投资人发起仲裁 代理律师称将提出抗辩
大模型公司月之暗面融资超10亿美元:阿里领投 创始人为清华90后学霸杨植麟
月之暗面卷入仲裁漩涡,都是利益惹的祸?
网址: 罕见,月之暗面杨植麟、周昕宇、吴育昕回应一切:打假460万美元、调侃OpenAI http://m.xishuta.com/newsview144178.html