对话深势科技张林峰、孙伟杰:AI for Science,从开始到现在

“我们希望推动一个开源的体系,从科学研究到工业研发,再到人类命运共同体。”
文丨程曼祺
编辑丨宋玮
多年前,杨振宁曾在一次高能物理学术讨论会上说:“The party is over”。因为上一个物理大发现时代已然远去。
现在,派对又开始了。
AI for Science,用 AI 加速科学发现,正成为 AI 最新、最激动人心的方向。由斯坦福大学前校长参与创立的 AI for Science 公司 Xaira Therapeutics,去年一启动就募资超 10 亿美元;OpenAI 也在今年成立 “OpenAI for Science” 部门,刚在上个月雇了一位黑洞理论物理学家。
早在 6 年多前,中国的 AI for Science 创业实践已经开始。最适合讲述这个故事的是张林峰和孙伟杰。
2018 年,25 岁的他们创立深势科技。 2022 年 3 月,张林峰写文:《AI for Science 2022:未来已来,即将开始流行》。8 个月后,ChatGPT 才发布。
深势的启动资源不是来自 VC,而是中关村颠覆性技术研发和成果转化项目资金——1200 万元人民币。张林峰在普林斯顿读博期间提出了 “深度势能分子动力学” 方法(DeePMD,Deep Potential Molecular Dynamics)。它后来获得了全球高性能计算权威奖项 “戈登·贝尔” 奖。
DeePMD 引入 AI,优化了量子论中一个长久的问题:对 “第一性原理计算”,即 1926 年提出的薛定谔方程等量子论基础方程的求解。在不太损失精度的情况下,DeePMD 能将第一性原理计算的范围从上百个原子扩展到上百亿原子,即从小到难以描述的纳米尺度扩大到显微镜可以看到的细胞、细菌尺度。
这个成果能用于发现新材料、新药物,这些领域都要了解物质性质。更长远看,人类的终极科学想象:无限能源(核聚变)、消灭疾病、走向宇宙,都需要对物质的更深探索。
张林峰的博士生导师之一,中科院院士鄂维南曾说:这是他三十多年没见过的机会,在他的学术生涯中,他一直没找到那些真正想解的问题的方法,现在他看到了。
1993 年出生的张林峰来自山西汾阳,因参加物理竞赛保送北大。在定位于跨学科教育的元培学院,他同时修了物理、数学、计算机。与张林峰同龄的孙伟杰来自黑龙江佳木斯,主修政经哲。两个北方高个儿男孩是院篮球队、羽毛球队队友,也在元培学生会体育部搭档。
理科生张林峰浪漫而热忱:保送大学时,他在清华和北大之间选了北大,他向往自由、天天写诗,还学了一段经济学,想 “经世济民”。申请博士时,张林峰拿到 MIT offer,但在普林斯顿看到爱因斯坦沉思过的草地后,他说自己走不动道了。文科生孙伟杰逻辑清晰,当被问及 “怎么看 Anthropic 创始人预测 5-10 年内,人类寿命会翻倍?”,他说:“5 到 10 年没法科学上验证寿命是否翻倍,观测时间不够。”

张林峰刚来普林斯顿时,在草地上撞见一只小鹿。“它独立、轻逸、灵动。它超然物外,沉浸在自己的世界里。在很长时间里,我跟它一样,处在一种 Detachment 模式里。对此我心存感激。”(《醉在普林的日子(上)》)
深势的早期投资人,众源资本冉翀说:“张林峰有极强的历史感和科学视野,他能从科学演化的路径上理解 AI 的意义,极为笃定 AI for Science 的未来,也清楚通向目标的关键节点和缺乏什么。” 更让他惊讶的是,“每次和伟杰交流,都很难感受到他是文科生。他对科学与技术的理解非常深刻。”
成立 6 年多来,深势科技推出了 Hermite 药物计算设计平台、Piloteye 能源电池研发平台;以及一系列预训练科学模型,如分子大模型 Uni-Mol、实验表征大模型 Uni-AIMS 、蛋白质大模型 Uni-Fold、基因大模型 Uni-RNA 等;科学文献大模型 Uni-SMART;和综合这些积累的科研平台与科研 Agent,“玻尔科研空间站” 和 SciMaster;服务了宁德时代、比亚迪、多氟多、长安汽车、京东方、东阳光药、人福医药、诺泰生物等企业客户。
张林峰和孙伟杰在创业时就定下目标:做一家源自中国、引领世界的科技公司。
“我们希望推动一个开源的体系,从科学研究到工业研发,说的再大一点,到人类命运共同体。” 在看到许多美国的科学家朋友的研究经费受限甚至被暂停后,张林峰说。
中国很少有创业者会直白提出宏大的愿景。还没有实现的理想与抱负,有被嘲笑和误解的危险。但这只是实现理想的过程中最轻的代价。
起点:用 AI 加速 “第一性原理计算”
“这是一系列统一的问题:即复杂高维的物理量和方程,能不能被 AI 有效表示、逼近和加速求解。”
晚点:所有新方向都来自一个原初的好奇心或疑问,对你来说,驱使你在博士期间走向 AI for Science 的初始问题意识是什么?
张林峰:那可以回到更早一些。在去普林前,我本科和伟杰都在北大一个特殊的学院元培,这里允许大家自由探索不同科目,我最后确定要做物理。
慢慢我意识到,我们的学习方式有欠缺:比如大二学广义相对论时,我学了黎曼几何之后才学古典微分几何,而数学系的顺序是反过来的。这是因为物理要讲广义相对论,势必涉及黎曼几何:1905 年,爱因斯坦在提出狭义相对论后,试着将它和引力统一,做到中间发现缺少必要的数学工具, 后来他和其它学者交流后才得知有一个已经存在的工具,就是黎曼几何。于是他又学了黎曼几何,在狭义相对论 10 年后,做出了纳入引力的广义相对论。
而我们上课的过程,是直接讲怎么统一狭义相对论和引力,把黎曼几何当成工具去推导场方程,就搞定了;考试也是考能否推导。至于它怎么来的、数学上怎么定义,都没有深入地讲。如果真要扎实地学,其实应该从古典微分几何开始学。另一个困惑是,到大三时,我已学完了弦论和相关数学,那么之后呢?
当时我觉得,我们这一代希望从底层科学出发做点儿事的同学,都缺点儿让人兴奋的大问题。
在相对论和量子力学被建立的那段岁月,很多成果都是二十多岁的年轻人在几年内做出来的,但这样的机会已经不存在了。就像杨振宁先生曾说的:“The party is over”。
晚点:从 “the party is over” 到找到研究方向,转折怎么发生的?
张林峰:本科末期我在做电子结构研究时,开始接触 “从头算”(ab initio),即从最基础的方程出发解决材料化学问题,得到了一些突破,正好可以用到量子化学里,这是我第一次真切体验科研探索的快乐。所以 2016 年去普林斯顿读博士时,我有两个导师,一个是应用数学方向的鄂维南院士,另一个就是计算化学方向的罗伯托·卡尔(Roberto Car)。
2016 年也是 AI 的转折年,那一年有了 AlphaGo。开学前,我原本还想选 Haldane(邓肯·霍尔丹,研究拓扑量子物态理论)开的凝聚态场论,当时鄂老师看了我选的课后说:“你本科已经学了这么多,就算跟大师学也只是再学一遍。我觉得你现在应该做机器学习。” 第二周,Haldane 就得了诺奖。诺奖往往不是一个领域的开始,而是盖棺定论。
当时我感到,接下来推动物理等基础科学进步的,很可能就是这一波 AI。那是 16 年 10 月,是我们整个研究的起点。
晚点:AI 和 Science 的含义都很广,在你们的研究之初,AI 是指机器学习,Science 是指什么?
张林峰:简单来说,是指量子物理中,对薛定谔方程的加速求解。
我最开始做机器学习时,它已经能做图像识别、用强化学习打游戏。但科学领域少有 ImageNet(李飞飞发起的图像识据集)这样适于机器学习的 “data ready” 的任务。大多数科学问题的数据都很稀疏,结构复杂,变量之间存在深层关联。
那时鄂老师把我和 Roberto 找来讨论,他对 Roberto 说:“我觉得机器学习几年内就要把你做的 ab initio molecular dynamics(从头算分子动力学)颠覆了。”
“Ab initio” 计算(第一性原理计算)就是从第一性原理出发求解万物。这个原理在电子、原子尺度上就是薛定谔方程——很简洁的一个方程,1926 年被提出,到 1929 年,Dirac(保罗·狄拉克,量子力学的奠基人之一,1933 年与薛定谔共获诺奖)断言,几乎所有化学和绝大部分物理都可以被这个方程涵盖。
但薛定谔方程难以被精确求解。怎么降低这个方程的计算复杂度,贯穿量子物理的百年探索。
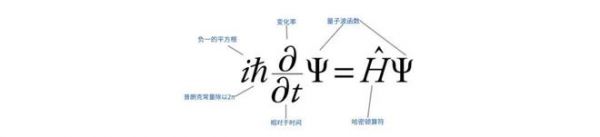
薛定谔方程
晚点:为什么说 AI 有可能会颠覆这件事?
张林峰:这需要先解释一下,在 AI 之前,我们是怎么简化这个计算的。
薛定谔方程描述的是粒子,如电子、原子的波函数的性质和演化规律。它的输入是原子和电子的位置,它的输出是这些粒子在空间中的分布状态。
首先,这个输入就非常复杂:比如一个水分子有一个氧原子和两个氢原子,每个原子在三维空间的坐标都由 (x,y,z)3 个数表达,那 3 个原子就是 9 个数,然后还有电子(1 个水分子有 10 个电子)的位置。一个水分子的输入就非常多。原则上,蛋白也可以被这个方程描述。但一个蛋白通常包含几百个氨基酸,对应几万到几十万个原子。它的输入就会特别大。
孙伟杰:这就涉及另一个方程——DFT(density functional theory,密度泛函理论的核心方程)。DFT 把薛定谔方程粒子间的相互作用,简化成了每一个粒子和外场间的相互作用。它损失了一些精度,但能算几十个原子到上百个原子间的相互作用,计算范围更大了。
晚点:几十到上百个原子是什么概念?一滴水里有多少个原子?
孙伟杰:一滴水里大概有超过 10^20 (10 的 20 次方)量级的原子。
晚点:所以要处理日常生活中的物质,DFT 的计算还是太复杂了?
孙伟杰:对。首先我们研究的大多数材料和药物反应都在纳米尺度,1 纳米是 10^−9 米,但一个原子的直径只有约 0.1 纳米,所以几纳米的空间就会包含成千上万个原子的相互作用。上百个原子的计算范围显然不够。
然后还要考虑时间,原子间的一次相互作用大概要 10^−15 到 10^−12 秒;而要形成我们想观察的现象,可能需要几百纳秒到几微秒,甚至几毫秒,如蛋白质的很多性质。过去的方法能算的时间也不够。
所以,即便有了 DFT 这个简化后的方程,很多问题仍解决不了。随着原子数量上升,薛定谔方程的计算复杂度会以 10^7 上升,而 DFT 方程也会以 10^3 上升。
Roberto Car 之前做的最大突破,就是在 DFT 的基础上,又模拟了分子间相互作用的关系。这就是前面提到的 ab initio molecular dynamics(从头算分子动力学)。(注:Roberto Car 和 Michele Parrinello 在 1985 年发表了论文《分子动力学和密度泛函理论的统一方法》(Unified Approach for Molecular Dynamics and Density-Functional Theory),提出了 Car-Parrinello 分子动力学方法。)
严格说,这不是真正的 “从头开始”,而是一个近似计算。Car 和 Parrinello 提出这个方法已经 40 年了,它深刻影响了计算化学、理论化学和统计物理。
晚点:所以在 2016 年那个时间点,你们是看到有了 AI 后,Car 和 Parrinello 的方法还可以被优化?
张林峰:简单说,在 DFT 框架下,依然需要求解电子的相互作用,计算依然复杂。然后对 DFT 进一步简化,就得到了分子动力学方程。
给定原子状态 R1、R2……一直到 Rn,每一步作用的这个能量是 E(Energy),它的受力就是 e 对每个位置的负梯度,等于 Fi。
原子的相互作用每演化一步,原子坐标就会更新;能量也会跟着变化。就跟放电影一样,会一帧一帧往后推。在过去,每一步都用量子力学的方式去算,很贵、规模很小。
我们的建模目标就是,能不能用 AI 去表示这样一个以 “从 R1 到 Rn 的原子坐标” 为输入、以能量为输出的函数。
晚点:这个建模的成果,就是后来获得了戈登·贝尔奖的 Deep Potential 模型?
张立峰:对,它其实是用 AI 做了一个代理模型,使它具有 “从头算” 的精度,也就是模拟 DFT 的精度;但计算效率高得多,可以大规模、长时间的模拟粒子的相互作用。
(注:相关论文为 Deep Potential Molecular Dynamics: a scalable model with the accuracy of quantum mechanics《深度势能分子动力学:一种具有量子力学精度的可扩展模型》,2018 年 4 月发表于《物理评论快报》。)
晚点:可以说,从薛定谔方程到 DFT 密度泛函,再到包括 Deep Potential 的一系列的近似或模拟,核心都是要在不损失太多精度的情况下提升计算效率?
张林峰:其实这中间不止一条路,从 2016 年底开始,我们试了很多方向:从 “能不能用神经网络替代复杂的波函数去求解”,到 “密度泛函的表达形式能不能更高效准确”,再到 “原子间相互作用的势函数能不能很精准地建模”。
本质上,这是一系列统一的问题:即复杂高维的物理量和方程,能不能被 AI 有效表示、逼近和加速求解。
这有点像围棋,它规则明确,但从当前棋局推到下一步的建模关系很复杂。物理规律也是清晰的、早就有的,但难点是基于这些规律求解。这就是我们从 2017 年开始,很快取得很多进展的方向。
从 “两亿核时” 到 “笔记本跑半小时”
“那时一下有了超过 6 个数量级的计算加速,用笔记本就能干过超算。”
晚点:你们当时取得的第一个 milestone 是什么?
张林峰:当时处理的第一个关键问题是,如何用神经网络给原子体系建模。我们就想,能不能把一堆原子坐标作为输入,把能量作为输出,让神经网络直接学到这个过程?
答案是不能。因为粒子有各种不变性;对波函数,要处理电子的交换反对称性;而对原子体系,则要处理平移旋转的不变性和交换的不变性。
以前的方法都不够通用,比如处理水时,就根据水的性质加描述,这就像特征工程,它能处理水,就不能处理硅。当时我们最大的突破,就是找到了一个相对统一的方法来表示多种不同的不变性。
晚点:这是个数学问题,还是一个计算问题?
张林峰:本质上是一个数学问题——就是怎么处理对称性建模和高维对称函数。
解决这个问题后,我们把它放到 TensorFlow(Google 在 2015 年发布的 AI 算法开发框架)框架里去实现,进展很快。2017 年 5 月就有了第一个 demo。到 6 月时,我们在笔记本上模拟的数据已经和 Roberto Car 组里非常昂贵的 “从头算” 数据很一致了。
晚点:你曾分享过,你在飞机上用自己的笔记本就跑出了水分子的状态。
张林峰:其实训练好模型后,跑第一性原理(指 ab initio 计算),用笔记本只要不到半小时,而之前需要两亿核时的计算。
晚点:两亿核时是什么概念?
孙伟杰:核时就是一个 CPU 核计算 1 小时。当时 1 核时大约 1 毛钱,2 亿核时是约 2000 万人民币。现在是越来越便宜了。
晚点:所以这个突破的意义在于大幅压缩了计算成本?
张林峰:这是一方面。那时一下有了超过 6 个数量级的计算加速,用笔记本就能干过超算。以前跟导师是一个月讨论一次,讨论完改代码、再跑一个月;现在是上午讨论,下午笔记本跑完就能继续讨论。我们变得特别高产,其实是因为能算得非常快。
更重要的是计算规模。当时已经看到,这套方法从微观还能继续往上涨到介观(mesoscopic,微观到宏观之间,纳米~微米尺度)、宏观(毫米~米尺度)的物理尺度。
这是个系统性的全面机会:从电子相互作用、凝聚态物理到化学材料,再到天气预报、汽车、飞机等工程建模,都有望被这样的新方法改变。
晚点:在计算加速上,2012 年神经网络兴起后,GPU 等计算硬件有很大发展,这给你们的研究带来了什么?
张林峰:其实 2017 年底,普林斯顿就买了 200 多块 P100(英伟达 2016 年发布的数据中心 GPU),整个学校都可以用,但闲置率很高。
核心原因是那时 AI 还没真正火,要实现一个算法得写很多代码,TensorFlow 每次都要从头编,软件会提示:是否需要 CUDA(英伟达提供的、调用 GPU 并行计算能力的软件平台) Support。当时看这么多机器闲置,又着急算,就点了 Yes,瞬间就编通了。这样训练速度又提升了 10 倍,而且我们能用几百块卡。
到 2018 年时,我发现生产力几乎是无穷的,为了不让卡闲着,我们开源了所有代码,这就是 DeePMD-kit 项目,由此也开始建立 DeepModeling 开源社区,这极大加速了对很多问题的探索。
这也让我们很早就意识到了 Infra(基础软件层)的重要性,包括 TensorFlow 这类框架和 CUDA、GPU 算力。
晚点:有了这个成果后,2018 年夏天,鄂维南老师正式总结了 AI for Science 这个概念,是看到了哪些更大的空间?
张林峰:这个方法论背后是一个更普遍的问题:过去很多难题都是高维函数的建模与求解。而机器学习恰好擅长处理高维问题。所以鄂老师后来写过一篇文章,说机器学习是应用数学的最后一块拼图。
晚点:你们当时解决的问题是用机器学习加速第一性原理计算。而一般提到 AI for Sicence,会想到 Goolge DeepMind 开发的蛋白质结构预测模型 AlphaFold。这两种方向是什么关系?
张林峰:这刚好是 AI 在科学中的两种作用。
一是处理有充足数据的问题,AlphaFold 就属于这一类——当时已有约 20 亿条蛋白序列、近 20 万个已解析的结构。AI 在这里主要用于拟合数据,建立从序列到结构的映射。这有点像 ImageNet。
二是处理规则清晰、但缺乏数据的问题。微观物理就属于这一类——没有直接可观测的大量数据,但可以用第一性原理算出结果,只是以往算起来很麻烦。
DeePMD 的作用就是根据物理方程生成 “合成数据”,再来训练模型——把原理本身变成了数据来源。在这里,AI 的作用是在规律指引下加速求解。
孙伟杰:类似的思路在自动驾驶、具身智能、核聚变等初期缺少数据的领域有很多应用,就像当年的 AlphaGoZero(注:用强化学习生成棋谱,自己和自己对弈来学习下棋)。
起步的 5 年:做微尺度的 “达索”,培养最优秀的低年级本科生
“没有哪个单一专业的人是 ready 的:懂化学的不熟算法,会算法的不精通工程……所以深势发展中有一个关键脉络,就是培养了一批最优秀的低年级本科生。”
晚点:2018 年有了这些进展后,你们是怎么决定一起创业的?
孙伟杰:我和林峰本科时的革命友情特别深厚,从大一开始,我们就是学院篮球和羽毛球队队友,后来又一起在元培学生会体育部,他是部长,我是副部长。
2018 年林峰已经做出了 DeePMD,夏天回国时住在我的宿舍,我了解了他在做什么。当时我在北大继续读研,也在一家投资机构实习,本身就在寻找 AI 创业机会。而正式考虑创立深势,是鄂老师拉我们一起讨论。
晚点:他怎么和你们说的?
张林峰:他说 30 多年没见过这样的机会。他觉得自己虽然 30 岁出头就在普林斯顿做正教授了,但一直没找到那些他真正想解的问题的解决方案,而现在看到了。如果要真的让这件事落地,光在学校里做不下去,学校人太少,也没能力做工程化。
所以鄂老师和我说:你应该现在毕业、回国,然后创业。一开始我惊讶于这么跳脱的建议,不过很快就想清楚了:机会是 AI for Science ,不是 get simulation done,然后发论文,这完全是两件事。TensorFlow 等 AI 生态的成熟也创造了条件。
最后我们的共识是,做一家 “源自中国、引领世界的科技公司”,让 AI for Science 真正影响整个科研领域。
晚点:你们正式开始做公司,怎么迈出从前沿技术到商业化的第一步?尤其你们 2018 年底成立时,这个领域在全球都很新,没有太多能对标的公司,外界的理解成本也比较高。
孙伟杰:在起步阶段,我们其实同时要解决三件事:业务方向、钱,还有人。
业务方向相对容易,虽然 AI 是新方法,但分子动力学本身已有应用,大的下游场景有化工、药物、材料、半导体、新能源等。从 2019 年 5 月到 8 月,我们密集做了行业调研,最后选的第一个方向是药物,有 3 个标准:
一是看技术重要性和潜力:分子计算是药物研发的核心之一,同时,这个场景也能持续拉动技术升级。
二是看商业模式:制药公司的支付意愿很强、客单价高。
三是看行业分工:药物行业链条划分相对清晰,业内本就有很多外包研发组织(CRO),我们的计算结果可以快速得到验证。
同时,当时国外已有薛定谔和 Accelrys 等公司,国内也开始有 AI 制药的萌芽。所以到 2020 年,我们很快就有了第一个产品——Hermite 药物计算设计平台。(薛定谔是为制药等行业提供科学计算服务的一家公司,1990 年成立,目前市值 14 亿美元;Accelrys 是一家为化学、材料和生命科学提供建模、仿真和数据分析软件的公司,2010 年成立,2014 年被达索系统以 7.4 亿美元收购。)
晚点:既然这个链条已经相对成熟了,作为新产品的 Hermite 和薛定谔等的差异是什么?
孙伟杰:薛定谔当时没有引入机器学习方法,是用之前的方法基于分子动力学方程来计算蛋白质之间的相互作用。
晚点:你们怎么解决启动资金的?2018 到 2019 年是上一轮 AI 热潮的融资低谷期。
孙伟杰:第一笔钱不是融资,是全国颠覆性技术创新大赛的金奖奖金,一共 1200 万,分 3 年给到。所以第一年我们没有着急融钱,本打算 2020 年春节后正式启动融资,结果赶上了疫情。
晚点:但你们还是在 2020 年下半年拿到了百度风投领投的天使轮,当时怎么向投资人解释深势的价值的?
孙伟杰:我会告诉大家,世界上所有物质归根结底都由原子构成,如果我们能清楚理解原子尺度的相互作用,理论上就可以求解所有材料和药物的性质,这会给化工、药物、材料、能源领域的底层研发带来大变化。
晚点:你们怎么描绘商业前景的?
孙伟杰:2020 年,我们还发现了另一个非常值得参考的对标,就是达索系统(法国工业仿真公司)。
任何研发范式成熟的标志之一,一定是这套研发流程能用电脑来做了,能用计算机精确、高效地模拟了,否则就是经验性的手艺。而达索系统的底层,就是把所有飞机、汽车图纸搬到电脑里,用电脑做设计,再用一系列固体力学、流体力学、电磁学、光学的技术去模拟这些设计能不能跑起来、是不是安全。
用这个逻辑去看药物和材料等分子、原子相关工业门类,研发流程都不成熟,都是重复性实验。所以做药的人会自嘲是在 “炼丹”。在这些领域构建更成熟的研发范式,是个很大的商业机会。
具体方法上,达索是把经典物理,如固体、流体、电磁的规律内化到了软件里。而深势是要把量子力学内化到软件里。在微观世界的工业研发中,量子力学才是第一性原理。
于是 2020 年,我们明确了深势的第一个五年计划是做 “微尺度工业研发的平台”,就是微尺度的达索。我们找到了这样一个巨大的工业场景和深刻科学规律的匹配。
晚点:起步阶段的第三件事是人才,你们当时面临什么状况,怎么搭建团队的?
张林峰:这是最难的问题。没有哪个单一专业的人是 ready 的:懂化学的不熟算法,会算法的不精通工程,我们还需要懂产品和商业落地的人;还要同时做新的研发。所以深势发展中有一个关键脉络,就是培养了一批最优秀的低年级本科生。
晚点:为什么从低年级本科生开始?这好像不是一个创业团队找人的常规选择。
张林峰:到了大三、大四,多数科学背景优秀学生的议程会相对固定:不少人开始着手出国申请,博士毕业后大多数人又会找教职,能来加入创业的人才不多。
同时,我们最初的核心成员中,有一位正好在北大做过辅导员,他熟识一批最优秀的本科生。这些实习生进来后,一开始是我在黑板上讲,很快发现黑板不好使,每次来个新人我都得从头讲一遍,研发也越走越深。所以后来从人才培养、教学到比赛,我们都自己搞了一套。

“几位 21 年夏天毕业的伙伴前来合影”(图片来自张林峰文章:《在 DP“读大学” 的少年们》DP 指深势科技。)
晚点:你们内部有一套专门的量子力学、计算化学的课程体系?
张林峰: 我们先用现成的学习工具和平台:笔记本用 Colab、线上课用 Coursera、比赛用 Kaggle……但这些平台当时都不怎么面向物理和生化环材等领域。于是我们做了 AI for Science 版的 Colab、Kaggle,也组织了比赛。后来很多人是通过打我们的比赛、参加我们的 DeepModeling 社区活动崭露头角的。
孙伟杰:DeepModeling 也是现在全球最大的 AI for Science 开源社区:这里一是能发现人才;二是会不断冒出新场景——能看到有人拿我们的工具做这、做那。它变成了一套交叉人才的培养和挖掘机制。
晚点: 其实你们相当于在探索一种新的教育和学习方式,打破了越来越细致的学科分工。
孙伟杰:AI 时代 “学习” 正发生巨变,更多是在 “干中学”,是 “按需学习”。因为搜索引擎解决了信息获取,AI 解决了知识获取,未来学习的关键是围绕要解的问题,自己定义学什么、怎么学。
大家都是这样过来的:林峰不懂创业、金融、财务,他的商业启蒙读物是马斯克传记;我当时对技术一无所知,用两三个月时间啃了一遍大学数理化生教材,后面接着边做边学。我们做这些教育探索,本身也是被业务和研发问题逼出来的。
从机器学习到 Agent,AI for Scicence 经历的四个阶段
“机器学习数理建模→预训练→大语言模型→科研 Agent。”
晚点:资源有限时做这么多事,踩过的坑是什么?
张林峰: 最大的挑战是机会太多。因为用这套底层技术,可以深入的领域很多,我们也大致知道每一条路推到极限能做到什么状态,但你只能选少数几个方向。
晚点:你们当时都考虑过哪些方向?
张林峰:大部分 AI for Science 能做的事我们早期都过过一遍,包括 AlphaFold 的蛋白质预测、可控核聚变、AI for 材料。但我们当时的资源绝对不够,不可能放开手全力做,只能在一些方向先保留火种。
DeepMind、达索等,都是用百倍、千倍于我们的资源做和我们一样的事。而当 Google、Meta 也开始重视这些方向时,国内又会反思,说为什么中国就做不起来。
晚点:你想说,其实你们做了,只是大家当时没注意到?
张林峰:或者说,并不是真的没机会做出这些成果,而是资源太有限了。我们可以看到非常多机会,甚至是诺奖级的机会。但另一方面,我们需要从头培养本科生,解决机房、插电源、部署环境等基础问题;我们要反复审视优先级:把有限的资源投到最关键的落地瓶颈和技术上。这个过程中的 trade off(取舍)是最大的挑战。
晚点:取舍中,有错过什么方向吗?
孙伟杰:其实从 18 年到现在,最大的机会我们都抓住了。复盘下来,AI for Science 有四波关键机会:
一是机器学习与数理建模的结合,我们做了 DeePMD,推出了 Hermite。
二是把预训练大模型引入科研,我们在 2021 年开始做分子大模型 Uni-Mol、蛋白质大模型 Uni-Fold 和基因大模型 Uni-RNA 等系列模型。
三是用大语言模型提升科研效率,我们训练了专门的科学文献大模型 Uni-SMART。
四是多智能体(multi-agent)科研 Agent,我们做了 “玻尔科研空间站”、SciMaster 这样的科研平台和助手,贯穿读(文献研究)、算(科学计算)、做(干湿实验)的全流程。
而接下来,最重要的方向会是 “AI 科学家”。
晚点:引入预训练方法,这和你们之前用机器学习来做数理建模的区别是什么?
孙伟杰:之前用分子动力学算材料,比如说这个支架(指向现场的电脑金属支架)可能是铝镁合金,那么我们要专门训一个模型来预测它的硬度、光泽等性质。
而有了预训练后,就能建立更统一的模型。无论铝合金、高温合金还是某种分子,都可以用一个模型处理。
2020 年前后我们就看清了这条路——先做小模型、建数据库,再到预训练大模型。预训练的条件之一正是我们用 DeePMD 从第一性原理方程生成的大量数据。不过当时我们没有料到,LLM(大语言模型)的爆发会来得这么快。
晚点:在最新阶段,就是做科研 Agent 时,你们的产品思路是怎么形成的?
孙伟杰:科研作为生产活动的基础要素是读、算、做,对应一系列基础工具:数据库、科研软件、实验设备。当然还有一个最核心的要素,就是人。
AI 已经在改变读、算、做:比如在 “读文献” 阶段,玻尔科研空间站能帮助研究者迅速界定选题、生成可检验的假设;在 “做计算” 阶段,它能根据假设,调用不同科学计算工具,得到多个候选方案和优先级排序;在 “做实验” 阶段,它会调用自动化实验室做干、湿实验,以验证方案,实验数据回流后会持续迭代,直至输出最优方案。
而未来,Agent 作用在人这一层,甚至有潜力完全自主调用工具、执行科研任务。这反过来又会改变基础工具:因为 “读算做” 的工具过去是为人设计的,未来肯定要为 AI 设计。
张林峰:也可以这样理解这个脉络,每一种新技术出现,科研与新技术结合时都会有新瓶颈。
最初是神经网络如何在物理约束下表示物理量,DeePMD 解决的是这个问题;接着是大规模计算中的高性能优化与云端并发,这就是 DeePMD-kit 做的事:建立了一套同时覆盖超算、云端和本地的前沿算力体系。而当大语言模型出现后,新的瓶颈变成了科研知识的整合与挖掘,大量高质量文献和专利数据都需要重新标注,被建模和整合。
所以我们一直在做的是:在每一阶段新技术来了之后,去处理科研流程与新技术的连接。
晚点:这些事情都需要你们自己做吗?比如有的公司侧重文献挖掘,不涉及科学计算,也有一些公司专注实验自动化;而深势的科研 Agent 看起来涵盖全流程,做得过来吗?
孙伟杰:肯定不需要都做,我们现在做很多事,是因为市面上没有现成方案。一些相对成熟的环节,比如实验自动化硬件,我们就没必要做了。
但我们一定要整合整个研发流程:因为 “读、算、做” 是完整体系。研发不是发个文章就完了,要变成可用的成果,就需要计算,乃至真实的实验。整个链条的信息、数据要尽可能通畅。
晚点:通用大模型公司推出的 DeepResearch(深度研究)能力不能获得这些信息吗?
孙伟杰:我们自己做文献阅读这一环时,就发现过去的论文和专利语料库并不是 AI-ready 的,需要自建一套科学语料库。除了论文内容,完备的科学语料还应包括:
实验数据与图谱,如光谱、晶体结构、反应曲线等;
分子式与结构数据;
专利全文与附图;
科研笔记、实验日志、仪器参数记录;
以及经过结构化和标注的科学模态数据,可供模型直接理解和训练。
理论上,如果一个大公司想投资源做,也能做。问题是,作为创业公司,你能不能先抓住这个空白,迅速做出一款好产品。比如原子大模型(DPA)、分子大模型(Uni-Mol)和基因大模型(Uni-RNA)这三个模型,我们就是全球首发,处在第一梯队。跟随我们的都是国际大厂:DeepMind、Meta 后来做了原子大模型;英伟达做了类似 Uni-RNA 的 Evo 2(25 年 2 月发布,Arc 研究所、联合斯坦福大学、英伟达)、DeepMind 也做了 AlphaGenome(25 年 6 月发布)。
晚点:现在全球大科技公司和一批融资更多的美国 AI for Science 创业公司都加大了投入。你们还能看到和抓住多少市场空白?
张林峰:接下来的变化还会很大,最终会看到科研范式的变革。
变革的本质是交互界面问题——人与科研工具如何交互、科研共同体如何协作、生产关系如何重组。之前做的很多积累:整合全量数据,在每个科研方向训模型——无论是 DeepPMD,还是 AlphaFold——都是少数人在往深走,而现在 Agent 正把它们连起来。这才有点接近我们在 17 年设想的状态:AI 结合多个不同方向,整体提升科研能力。
这也迫使整个 community 重新思考:比如以前学术共同体的一大驱动力是 peer review(同行评议)的论文发表体系,而当 AI 已经能写论文、审论文,甚至自己搞定不那么原创性的研究时,发论文的意义是什么?类似的,以前实验科学家要找计算科学家合作分析数据,现在他可以直接让 Agent 调用软件做模拟和解释。
这些变化会比很多人想象得快,学科划分、交叉合作的模式乃至整个科研流程本身都会有大变化。
用一套平台服务不同方向和阶段的科研,服务 1000 甚至 1 万个客户
“做平台,更符合科技公司的属性,也能激发更多科学发现,而不仅是某一个领域的发现。”
晚点:深势在挑战一个高难度创业方向,中间遇到过什么大的挫折和低谷吗?
张林峰:最深陷泥潭时应该是 2022 年-2023 年。这不是因为具体挫折,而是当时我们处于一种需要持续自证的状态。
我们最初的核心课题是要验证技术,并证明我们有引领性,这需要拿出直观的成果。所以我们会做药物管线,从技术突破一路推到应用;也会把一个创新算法变成真正的工业软件,走完工程化、用户反馈和迭代的全过程。
但到了 2022 年,我们又看到做研发平台和重塑整个研发流程的机会,尤其是年底 ChatGPT 出现,这是机遇也是挑战——我们要迅速拥抱新技术,又要构建从文献、专利到实验的 “读、算、做” 闭环,真的加速科学发现。
晚点:还是一个有限资源下的优先级问题。
张林峰:我们是到 2023 年底突破了这个时期,一是证明了我们一系列模型的领先,比如前面提到很多大公司来 follow 我们的成果;同时我们也理清了之后的思路。
晚点:你们的早期投资人之一冉翀告诉我们,你们当时在 “垂直应用” 和 “通用研发平台” 间抉择过一段时间,后来选了做平台,为什么这么选?
孙伟杰:这是一个必须的取舍。因为研发平台和垂直应用,比如直接做药物管线的逻辑并不兼容。做管线要把全部赌注压在一两个关键资产上,要深入理解市场和临床需求;而做平台则要持续优化算法、算力和工具体系,让平台能持续迭代。一旦把资源押在某几条管线上,平台研发容易被牵制。
我们更愿意基于一套平台服务不同方向和阶段的科研,服务 1000 甚至 1 万个客户。这更符合我们的初心:做一家源自中国、引领世界的科技公司。
晚点:为什么平台更符合 “源自中国、引领世界的科技公司” 的定位?
孙伟杰:源自中国、引领世界是确定的。而我们认为做平台,让技术服务更多人,更符合科技公司的属性,也能激发更多科学发现,而不仅是某一个领域的发现。
其实这两者的价值没有高低,比如如果能做出一款新药,对社会的价值非常大。更多是说哪个声音在更强烈地呼唤我们,哪件事在我们心中投下了更大的阴影。
晚点:你们怎么考虑这个选择的商业潜力?比如在半导体领域,ARM、新思这类做 IP 和基础开发工具的公司的规模不如下游做具体芯片的公司,如英伟达、高通和 AMD。
孙伟杰:其实英伟达的 CUDA 生态也是一个 AI 底层开发平台。而且无论平台还是管线,都有做到千亿美元的潜力。达索现在的市值也有 500 多亿美元。关键不在方向,而在能否把一条路走深。
诺奖表彰 “第一个”,而基础平台要做 “最后一个”
“诺奖是一个已经存在的评价体系,而现在正在发生的科研范式的革新会冲击评价体系本身。”
晚点:在你们看过、做过的这么多能与 AI 结合的领域里,哪个方向最有潜力成为诺奖级成果?
张林峰:可以从另一个角度看这个问题,说回前面提到的的初心里的 “源自中国”。
过去 100 多年逐渐形成的 “科学无国界” 的共识正受到挑战。就以 AI 为例,它在推动科学发展,但它的底层模型也越来越集中和封闭。
而我们希望推动一个开源、开放的体系,从科学研究到工业研发,说的再大一点,到人类命运共同体。这个主张,在中国是更坚定的。
我自己在普林斯顿读博士时,看到比我大 10 到 20 岁的学长、学姐,他们的发展路线相对固定:读完博士,肯定是在几个顶尖学校里找教职。但现在可以看到,不少美国实验室的经费面临缩减,甚至暂停;对研究者要做什么、不做什么,限制也越来越多。
这个时候,科学家作为一个共同体,既要拓展人类认知边界,又要推动下一步产业创新,给人类带来更好的生存状态,这面临很大的挑战。所以一个能支持多学科交叉协作、能加速很多方向的基础平台就更迫切了。这往后才是诺贝尔奖的问题,即我们怎么认可一个科学贡献。
确实在 2022 年-2023 年时,要不要去冲击某个具体的科学新发现,对我们来说是个巨大的选择题。因为诺奖表彰的永远是 “第一个”;而基础平台恰恰要做 “最后一个”——当所有人都在上面工作时,它才真正成为底层标准。
但后来我们也看到,一个好的技术平台,其实可以容纳这个两个方面:因为它加速了发现,所以这里可能产生更多 “第一个”;同时,如果很多科学家都来用它,那它也是 “最后一个”。而兼具的方式就是定义新的科研交互界面,是找到科研 Agent 的 PMF。
晚点:所以你们看重的不是自己是否触及诺奖级成果,而是多少诺奖级的新发现是被你们的工具和平台加速的?
张林峰:其实 24 年 10 月 AlphaFold 得诺奖时,确实对我有一定影响,我当时也感叹过,我们曾站在过这样一个可能性——如果能有更多资源,全力放开去推,如果不是说处于人也要从头培养的状态。
但说后不后悔这个决定?肯定不后悔。因为我觉得 AI 加速科学发现,会对诺奖的意义都有很大冲击。诺奖是一个已经存在的评价体系,而现在正在发生的科研范式的革新会冲击评价体系本身。
不管我们存不存在,这个变化都一定会发生,但我们希望变化能朝更好的方向前进。

深势创立初期的部分团队成员合影,从左到右依次为:张林峰,深势创始人兼首席科学家;李鑫宇,北京科学智能研究院院长;孙伟杰,深势创始人兼 CEO;郑行,深势药物发现事业部总工程师;昌珺涵,深势自动化实验室负责人。
AI 科学家到来,越基础的学科越安全
“更大的挑战是,AI 时代,人的学习曲线被打断了。”
晚点:接下来一年,你们最想验证的一个问题或悬念是什么?
孙伟杰:AI Agent 现在已经能在 “读、算、做” 之间形成闭环,独立执行两三天的任务。我明年想看看,它能否自主调动这些工具,真正发现一两项新成果,比如在材料、化工、药物方面有新发现。
张林峰:我想验证的问题是,Innovator(创新者)到底长什么样。OpenAI 之前定义了 AGI 的 5 个阶段(注:Chatbot 聊天机器人、Reasoner 推理者、Agent 智能体、Innovator 创新者、Orgnizer 组织者),现在正是从 Agent 走到 Innovator 的发展期,AI 与 AI for Science 会正面相逢。
可能有两种路径:
一是从通用智能到科学智能——先学完全部历史信息,再往前走。
另一个方向,是从科学智能到通用智能——先理解最本质的规律。这就像是把 “数理化” 与 “政经哲” 的基础打牢,再走向社会。
无论是从通用智能走向科学智能,还是反过来,它们的碰撞点一定是 “Innovator” 模型应当长成什么样。这也是各家 AI 厂商发力的方向。所以 7 月底我们发布 SciMaster 的同时,也推出了一个 baby-level 的 Innovator——一个 AI for Science 的基座模型。
晚点:前面提到,你们认为接下来最重要的主题是 AI 科学家。如果 AI 科学家真到来了,我们会看到什么?生活会怎么变化?
张林峰:比较直观的,会有一批药物、材料的新成果,比如出现颠覆式的电池技术、高分子领域的突破等。
孙伟杰:每个人会拥有一个教授级的 AI 科学家朋友,可以随时请教任何问题。比如前几天北京暴雨后天空变成粉红色,我们就问玻尔这是怎么形成的,它给出了非常精彩的解释。
玻尔科学导航网页上的 “问题广场”。
从产业上,很多突破都已逼近现实:比如手机续航可能延长到十天甚至一个月;电动飞机会变得可行;更远一点,AI 还可能让药物研发像搜索信息一样简单——输入疾病,系统就能分析相关靶点,并快速生成候选药物。
晚点:Anthropic CEO 达里奥·阿莫迪(Dario Amodei)24 年 10 月曾在《仁爱机器》(Machines of Loving Grace)一文中预测,未来 5 到 10 年人的寿命会翻倍,这有可能吗?
孙伟杰:5 到 10 年没法科学上验证寿命是否翻倍,观测时间不够。
大的逻辑是,人类的几个终极愿景——消灭疾病、无限能源、走向宇宙,更快的通信和更强大的计算——都离不开原子、分子方面的科研努力。结合 AI 的科学研发平台会加速这些领域的创新与发现。
晚点:另一方面,你们觉得 AI 加速科学发现后,会有什么风险?我们可以提前做什么准备?
张林峰:风险有显式和隐式的。显式的,比如 AI 可以做药,也可以做毒品,这需要监管。
隐式的就是前面提到的,科研评价体系正被颠覆。科研的三要素——工具、内容、人——都在被重新定义:
工具上:Agent 的能力迅速增强,正在冲击传统科研工具和工业软件的边界;
内容上:AI 已能自动撰写论文、辅助研究,论文可能不再是核心成果的唯一载体;
人的层面:当 AI Scientist 出现后,如何评价人类科学家?
孙伟杰:我没那么担心显式的风险,因为合成新分子、开发新材料这些领域的供应链、环境评估等环节早就受到严格监管。
更大的挑战是,AI 时代,人的学习曲线被打断了。现在 AI 虽不能完全替代正式员工,却足以取代实习生,这意味着很多人失去了用初级工作练手、成长的机会;这可能产生结构性断层,是一代人要面临的问题。教育的变革速度往往落后于技术演进。
晚点:你们觉得五年之内,什么专业还是比较安全的?
孙伟杰:越是基础的学科越安全。物理、化学和数学,虽然未来会有更多 AI 参与,但它们依然是培养思维方式的核心学科。数学训练逻辑与抽象能力,物理培养对自然规律的直觉与推理。
在社会科学领域,政经哲塑造人理解世界与判断价值的方式。这原本就是一个学科。哲学分化后形成了两条线:自然科学的起点就是 “自然哲学”,牛顿那本书就叫《自然哲学的数学原理》,社会科学的起点是 “政治经济哲学”。北大的录取趋势也印证了这一点:现在数学、物理等基础理科的分数线最高,超过了之前最火的经管类专业。
另一类是和人的体验相关的:文学、艺术和体育,这都是 AI 无法取代的。
“什么时候是你最光辉的时刻?”“就是现在!”
“要有菩萨心肠,也要有雷霆手段。”“理想主义的实干家才能改变世界。”
晚点:你们两之间的相处和决策模式是怎样的,出现重大分歧时,怎么解决?
孙伟杰:创立公司后,好像没发生过特别剧烈的分歧和争吵。因为上学时把很多本质问题都吵完了,对彼此的三观都已充分了解和认可。
晚点:当时会因为什么事碰撞?
(两人笑而不语)
晚点:感觉你们已经想到了同一件事。
孙伟杰:简单说,是一些具体问题引发的一些更抽象的争论。因为我们曾在学生会搭档过,也各自领导或创立过社团,会遇到一些学生组织的传承问题。
晚点:在三观上,你们比较底层的相同点和不同点是什么?
孙伟杰:我们相似的地方有两点:一是都有自驱的欲望和原动力,区别在于,我的欲望更多来自多年体育训练带来的好胜心,而林峰的动力则更多来自他对世界和科学的好奇心。第二点,都有改变和做决定的勇气。
张林峰:我们还有一个共同点,就跟决定创业只要 5 秒一样,来北大也是很快就决定了。这里有更大的自由。
孙伟杰:我和林峰做选择上有一点是相似的,宁可放弃概率高但上限低的确定选项,也愿意赌更不确定但上限更高的机会。
晚点:那区别呢?我看林峰之前在个人公众号上写文章分享过《牧羊少年的奇幻之旅》。这本书就是在讲,你要去听 “你心的声音”。作为理科生,林峰很浪漫,写的不少随笔炽烈、热情;伟杰反而比较冷峻。
张林峰:刚来北大时,我没觉得要学物理,天天写诗的。也学了一段时间经济学,觉得这是经世济民的方法。
孙伟杰:林峰是外冷内热,虽然说他是个 “I 人”,平时感觉很难接近,但其实内心似火,对所有事情充满激情。我有点相反,我是外热内冷,很容易接触和接近,但其实内心的 bar(标准)比较高。
晚点:林峰有一年暑假还去流浪过, 当时为什么要做这件事?
张林峰:是高三的夏天,我买了几张火车票,带了个双节棍,就去闯沙漠了,我比较喜欢李小龙。那时写了很多日记,其实当时的思考和现在做的事也是一致的。
孙伟杰:大学刚开学不久,我就看到了林峰的这个小本子,他也写了很多中学的经历和感受,我很有共鸣。比如我们都看过相同的热血动漫,都会把自己带入那个傻傻的主角:龙珠的悟空、灌篮高手的樱木花道、海贼王的路飞。他还在沙漠里创作了一个个人 logo,和我中学时给自己创作的 logo 如出一辙。所以我一入学就知道了这是自己人。
张林峰:太中二了。
晚点:22 年 Uni-FEP 发布后,我看林峰写文章中提到,希望很多年以后,大家会看到理想主义真的可以改变世界。现在你们怎么理解理想主义?
孙伟杰:还得加另一句。要有菩萨心肠,也要有雷霆手段。
张林峰:理想主义的实干家才能改变世界。
晚点:现在还有偶尔 “中二” 的时候吗?
张林峰:2020 年,我回国时还是疫情,在酒店隔离了很久,重新看《灌篮高手》,后面有些内容动画版没拍,就有人用漫画拼成视频,然后到了一个画面所有弹幕都是 “都给我哭!”
那是一个名场面(湘北对决山王时,樱木花道问安西教练):“老爹,什么时候——”
孙伟杰:“是你最光辉的时刻?”
张林峰:“就是现在!”
实习生姚一楠、刘贺对此文亦有贡献。
题图来源:孙伟杰。大二时,元培体育部举办趣味羽毛球赛后,孙伟杰(左)和张林峰(右)从邱德拔体育馆骑车回宿舍。
相关推荐
1年半完成4轮融资,深势科技为何成为AI领域黑马?
两个北大学霸,3年融资十几亿,要“复刻”万物
「深势科技」获高瓴创投领投的A轮融资,以“AI+分子模拟”打造微观尺度工业设计新引擎
北大元培系AI公司,一年狂揽三轮融资,最新A轮斩获数千万美元
向着新一轮科学革命制高点攀登——2023全球科学智能峰会观察
合伙人张峰将离职,小米“第二个十年”的创业更进深水区
科研顶流给你当助手?深势科技联合上交大发布通用科研智能体SciMaster
对话孙宇晨:拟邀李林V神等赴巴菲特午宴望修正其投资论
请保持奇迹,这是疫情也无法磨灭的创新活力
讯飞星火深度赋能科研,加速AI for Science成为科技变革新引擎
网址: 对话深势科技张林峰、孙伟杰:AI for Science,从开始到现在 http://m.xishuta.com/newsview144129.html