AI「智能体组织」时代开启,微软提出异步思考AsyncThink
从大语言模型(LLM)到智能体(Agent),代表了人工智能(AI)系统从“言”到“行”的范式跃迁。
更进一步,当多个 Agent 以组织形态出现,并通过协同合作、并行工作产出超越个体智能的成果时,AI 的下一个范式——“智能体组织”(agentic organization)——便出现了。
然而,尽管当前的 LLM 作为个体 Agent 已经展现出令人惊讶的推理能力,但要真正实现“智能体组织”的愿景,LLM 不仅要能够独立思考,还必须作为一个有组织的系统进行协同思考。
为此,微软团队提出了一个名为“异步思考”(AsyncThink)的 LLM 推理新方法,即把内部思考过程组织成可以并发执行的结构,从而解决现有并行思考方法中存在的延迟高、适应性、动态性差等难题。
实验表明,与并行思考相比,AsyncThink 在提高数学推理准确性的同时,将推理延迟降低了 28%。此外,AsyncThink 还可以将其学到的异步思考能力进行泛化,无需额外训练即可有效应对未见任务。

论文链接:https://arxiv.org/pdf/2510.26658
研究方法
AsyncThink 的核心为“组织者-工作者”(Organizer-Worker)思考协议。其中,LLM 扮演两个角色:
一方面,它是一个“组织者”,负责把复杂问题拆分成子任务,并通过“Fork”(分叉)和“Join”(合并)来安排任务的顺序;另一方面,它还是一个“工作者”,执行这些子任务并返回中间结果。
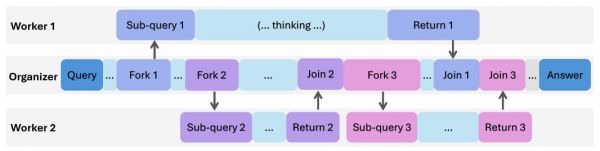
图|AsyncThink 的思考协议示例。该协议通过 Fork-Join 操作实现异步思考,从而控制思考轨迹。
通过这种方式,模型不仅能并行处理多个子问题,还能动态调整思路,实现更灵活、更高效的推理。
为训练 AsyncThink 模型,他们提出了一个两阶段训练过程:冷启动格式微调、强化学习。
1.冷启动格式微调
这一阶段是让现有的 LLM 经过冷启动格式微调,掌握 AsyncThink 框架的组织语法与行动结构。
在数据合成环节中,由于现有语料中几乎不存在“组织者–工作者”的思考样本,研究团队采用GPT-4o生成合成训练数据。GPT-4o 首先分析每个输入问题,识别出可独立求解的思考片段;随后按照AsyncThink 协议格式分别生成组织者与工作者的推理轨迹。
在结构初始化环节中,为了提升模型结构的灵活性,研究团队随机采样不同的组织动作序列,并将其中一种结构样例嵌入训练提示中,让模型在各种结构下都能学习,从而生成更具多样性的思考拓扑。
在数据合成与结构初始化完成后,研究团队对基础 LLM 进行监督微调,赋予模型发出有效组织者行动的能力。
在这一阶段,模型尚未学会用异步思考产生正确的答案,而只是模仿格式。
2.强化学习
由于第一阶段只教授了组织者行动的句法结构,模型仍然缺乏利用这种思考机制来生成最终答案的能力。因此,研究团队进行了第二阶段——强化学习,通过奖励来指导模型学习效率高、准确性高的策略。
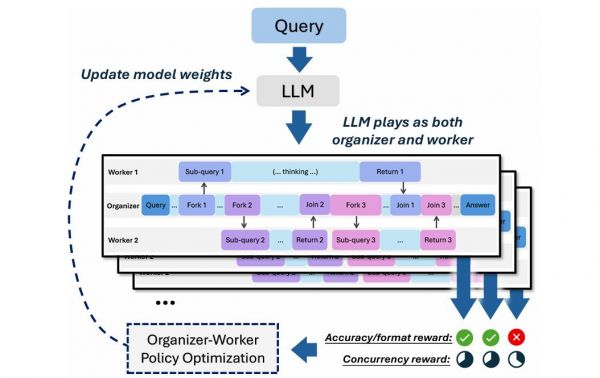
图|AsyncThink 强化学习框架示意图。
在奖励模型中,通过准确性奖励确保最终答案是正确的;通过格式奖励确保模型生成的轨迹是可执行的;通过思考并发奖励促使模型寻找机会进行异步而非顺序思考。
训练时,研究团队改进了群组相对策略优化(GRPO) 算法,让它适应异步结构。模型生成的不再是一条简单的思维链(CoT),而是一个由组织者和多个工作者组成的“思考结构”。最终的奖励会共享给整个结构的所有输出,确保每个部分都朝同一个目标优化。
通过精细的奖励模型和优化机制,AsyncThink 模型能够动态且高效地协调其内部“智能体组织”来解决实际问题。
实验评估
研究团队评估了 AsyncThink 模型在多解倒计时、数学推理和数独任务上的表现。实验表明,与序列思考和并行思考模型相比,AsyncThink 始终能实现更高的准确性,同时降低延迟。
此外,研究团队还通过消融研究进一步分析了其性能,凸显了 AsyncThink“两阶段训练过程”的有效性。
具体如下:
1.多解倒计时实验
AsyncThink 的全对率达到 89.0%,比并行思考(68.6%)和序列思考(70.5%)都高。这意味着它不仅准确率更高,还能覆盖更多解答。

图|多解倒计时任务评估结果。≥a Correct 表示模型能否成功找到给定问题的唯一正确解。
2.数学推理实验
在 AIME-24 上:AsyncThink 的准确率为38.7%,延迟为 1468.0;在 AMC-23 上:AsyncThink 的准确率为 73.3%,延迟为 1459.5。相较传统并行推理,它在保证精度的同时减少了约 28% 的推理延迟。
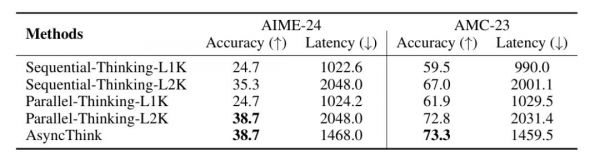
图|AIME-24 和 AMC-23 的数学推理评估结果。
3.跨任务泛化实验
虽然只在倒计时任务上训练,但直接迁移到 4×4 数独时,AsyncThink 依然表现最好(准确率达到 89.4%,且延迟最低)。表明 LLM 学到的不是具体的模式,而是一种可迁移的组织性思考模式。
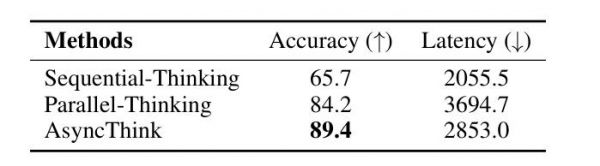
图|AsyncThink 在 4 × 4 数独任务上的评估结果。
4.消融实验
在消融实验中,研究团队发现:格式微调(Format SFT)能够让 LLM 学会“语言”,即如何 Fork 与 Join;而强化学习(RL)让 LLM 学会“策略”,即何时 Fork、如何 Join 才能更快更准;并发奖励(Rη Reward)则让 LLM 学会“效率”——平衡准确率与延迟。
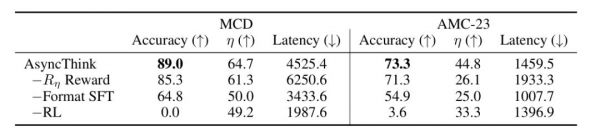
图|通过移除 AsyncThink 的关键组件进行的消融实验结果。
未来工作
尽管 AsyncThink 在提升 LLM 推理准确性和降低推理延迟方面表现出显著优势。但它只是实现“智能体组织”这一愿景的一个起点。
在未来的工作中,研究团队将围绕“规模/多样性扩展”“递归智能体组织”“人-AI智能体组织”三方面继续探索“智能体组织” 。
1.扩展智能体的规模和多样性
首先是扩展“工作者”的数量。未来的工作应该探索异步思考的 scaling laws:随着智能体池容量从少数几个增长到数百甚至数千,准确性-延迟的权衡将如何演变。
其次是扩展智能体的多样性。超越同质化的智能体池,转向由异构专家工作者组成的大型组织。这些智能体可以针对特定领域(如数学、编码、数据分析)进行微调,且至关重要的是,它们可以配备不同的外部工具(如代码解释器、数据库查询引擎或网络搜索 API)。这为组织者带来了更复杂和更强大的学习问题。
2.递归智能体组织
在这个范式中,任何工作者都可以动态地被提升为子组织者,从而获得 Fork 自己的子工作者团队的能力。这将实现一个灵活的分层结构,自然地适用于需要多级分解的深度嵌套和复杂问题。例如,一个出色组织者可能会委托一个宽泛的查询,例如“解决 * 问题”,而指定的工作者则充当子组织者,Fork 出三个新的子工作者并行独立地测试不同的引理(lemmas)。
3.人类-AI智能体组织
一个关键前沿是通过将人类直接整合到智能体组织中来创建人类-AI协作框架。这可能涉及“人类作为组织者”,使用 Fork 协议将任务分配给 AI 工作者,或者“人类作为工作者”,由 AI Fork 出需要人类判断的任务。此外,协作规划将允许人类和 AI 在执行前共同设计异步策略。这一方向超越了纯粹的 AI 自主性,将实现强大的混合智能。
本文来自微信公众号 “学术头条”(ID:SciTouTiao),整理:潇潇,36氪经授权发布。
相关推荐
在“范式转移”的时代,如何重塑“职业”的定义
智能体迈入L4时代,纳米AI多智能体蜂群,可创作史上最长10分钟AI视频
智能体大杀四方,人类工作危在旦夕?
对话清华大学张亚勤:智能体是大模型时代的APP
AI智能体,为什么看不懂?
迈进全域AI时代!吉利宣布:Eva智能体、新AI座舱来了
AI智能体上线,营销人下线? | AI无悖论
科普之旅 | 漫话智能体-当机器学会思考
AI时代的智能体,离人人可用还有多远?
智能体崛起
网址: AI「智能体组织」时代开启,微软提出异步思考AsyncThink http://m.xishuta.com/newsview143974.html