假期被玩坏了的奥特曼,正在玩弄全世界的算力
如今,春天英伟达的GTC,秋天OpenAI的DevDay,是硅谷最重要的盛会。它们预告了未来。
在刚过去的OpenAI开发者日上,除了发布了ChatGPT Apps SDK、AgentKit、GPT-5 Codex,奥特曼提到的几组截至2025年的数据,揭示AI行业正在驶向何方:
平台400万开发者;
8亿ChatGPT周活用户;
API调用每分钟60亿token。
让我们就此做一点大胆地假设与简单的计算。
第一,OpenAI整体每月tokens消耗。
基于API的调用,显然不是OpenAI对外提供AI服务的全部。去年,OpenAI曾披露它的基于ChatGPT的消费者订阅业务,收入占比约为75%。而按照OpenAI对未来的收入路线规划,ChatGPT订阅收入占比将逐步下滑,取而代之的是API、Agents与其他新业务占比。当然,目前OpenAI正在布局Agents相关产品线,并开始探索广告与电商业务,但相比其他两大业务,可以说仍然处于商业化早期阶段。
不妨让我们假定,目前,OpenAI来自API的收入,仍然占据25%,而且,收入占比对应着token的消耗数量。
那么,OpenAI基于API的token消耗量,每周将达到60*60*24*7=60万亿tokens,每月则约为260万亿。相应的,基于ChatGPT订阅的token消耗量,每周将达到180万亿tokens,每月约780万亿。整个OpenAI每月的token消耗合计约为1040万亿。
这意味着OpenAI与谷歌处于相同烈度的竞争之中。谷歌的AI工厂同样在疯狂地生产token,从5月的480万亿tokens,骤增至6月的980万亿。当时,Veo 3发布不久,Nano Banana尚未发布。谷歌目前月均token消耗量肯定已经突破千万亿量级。而OpenAI这次公布的数据应该也没有统计Sora 2放量所带来的。
第二,ChatGPT用户画像。
OpenAI的ChatGPT目前拥有约8亿周活用户,每周消耗约180万亿tokens,折算下来人均每周使用约22.5万tokens。一项研究将典型推理任务设定为输入10k、输出1.5k tokens,据此估算,平均每位用户每周大约执行20次此类推理任务,也就是在每个工作日向ChatGPT提出约四个重要问题。
当然,这一抽象的平均值,掩盖了几个实际应用场景中的结构性差异:少数中重度用户贡献了绝大部分token消耗;不同重要程度的问题,交互深度与轮次并不相同。
第三,开发者用户画像。
若将API调用主要视作由开发者生态贡献,那么,相对2023年,OpenAI平台上的开发者人数增长了2倍,而API消耗的token数量却增加了20倍。简言之,短短两年间,平均每位开发者消耗的token数量增长了10倍。
促成人均消耗量大幅增长的,也许正是深度推理与智能体在各行各业,尤其首先是编码行业的渗透。
在演讲中,奥特曼宣布GPT-5 Pro将开放API。它就非常适合协助完成非常困难的任务,在金融、法律、医疗保健等领域,以及更多需要高准确性和深度推理的领域。此外,OpenAI的GPT-5 Codex正式发布,从8月以来,Codex的日使用量增长了10倍以上。
这个趋势仍在增强。智能体的摩尔定律就预言了它能处理的任务的复杂度每7个月翻倍;多智能体间的协作,至少将推理消耗进一步放大到简单对话的15倍以上。
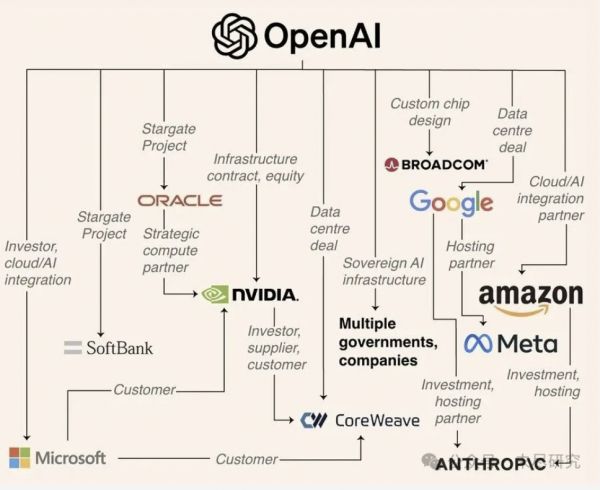
难怪在绑定英伟达10GW的数据中心后,OpenAI又与AMD打得火热,约定了总计高达6GW的数据中心。奥特曼已经开始营销它强大10倍的GPT-6,并将数据中心规模提升至2033年得到惊人的250GW。
第四,Sora 2的峰值GPU需求。
从文本推理到多模态生成,算力消耗的曲线将更急剧陡峭。奥特曼还宣布Sora 2也将开放API。多模态将不断向现有应用场景渗透,也有望创造出新的应用市场。
但由于OpenAI越来越不透明,不再公开技术细节,对Sora 2算力消耗的估算也不得不建立在一系列大胆而高度敏感的假设之上。总体而言,它与模型与视频的性能参数,以及工作负荷模式密切相关。
在初代Sora发布的时候,风险投资机构Factorial Funds的Matthias Plappert,就曾基于多重假设估算出,72万张H100才能满足它的峰值需求。他假设,初代Sora的参数规模为200亿,且以24帧/秒编码,采样步数为250步,它与典型的DiT模型类似,即6.75亿参数的模型,8倍的压缩率,以及单帧画面524×10^9次浮点运算。他还假设Sora在TikTok与Youtube上的渗透率分别为50%与15%。他还考虑了算力实际利用率,峰值需求与候选视频需求。
可见,模型规模、采样步数、硬件效率,以及OpenAI在AI社交短视频上的野心,将是决定Sora 2整体算力需求最关键的变量与杠杆。
整体而言,扩散模型仍然满足扩展定律。年初,对标初代Sora的Step-Video-T2V参数规模达到了300亿,也许Sora 2的参数规模也有小幅增长。业界也在探索通过算法改进推动采样步数的下降。此外,从Hopper架构到Blackwell架构算力性能的提升,以及针对性地推出定制芯片,都在提升算力效率。
不妨先让我们假定,Sora 2的参数规模增长2.5倍至500亿参数;它主要在GB200的FB8精度下推理,约较H100的FP16精度提升了5倍;其他变量此消彼长,整体不变。再让我们假定,Sora 2继续向TikTok与Youtube输出相同体量的内容,且OpenAI最新的独立应用Sora,将成为短视频平台的有力竞争者,即每天生成的AI视频总时长,等同于对外输出的体量。
换言之,Sora 2的峰值算力需求仍高达约72万张GPU,只是硬件代际从H100更换为GB200。
这当然只是一个静态的、片面的估算。随着AI视频生成性能的提升,其应用将从社交分享扩展到影视制作等专业领域;社交和短视频平台也将卷入这场新的军备竞赛,把算力竞争推向新的量级。
难怪奥特曼的目标,是今年底百万张卡。
相关推荐
假期被玩坏了的奥特曼,正在玩弄全世界的算力
玩坏了人体的温度感,分分钟“生死难料”
“助力链”真的被玩坏了
OpenAI走向“算力帝国”
奥特曼自曝全新GPT5细节:性能跃升超想象,算力可达AGI!
AI算力光速革命
假期的游戏陪玩市场,有人挣钱有人被骗
奥特曼最新访谈:AGI即将出现,未来最重要的资源是能源和算力
算力,AI时代最确定的赛道
苹果头显,快被中国人玩坏了
网址: 假期被玩坏了的奥特曼,正在玩弄全世界的算力 http://m.xishuta.com/newsview142856.html