对AI的质疑,是“自欺欺人”?
本文来自:华尔街见闻,作者:龙玥,原文标题:《AI专家:对AI的质疑是对“指数级增长趋势”的“自欺欺人”》,头图来自:AI生成
一位来自AI研究前沿的专家坚定反驳了当前普遍存在的“AI泡沫论”。
AI明星公司Anthropic的研究员Julian Schrittwieser在其个人博客中撰文警告,当前对AI“泡沫”或“平台期”的普遍质疑,是对技术指数级增长趋势的严重误读,这种心态与新冠疫情初期对指数级传播的忽视如出一辙。
当前围绕AI进步和所谓“泡沫”的讨论,让我想起了新冠疫情的最初几周。当指数趋势已经清晰预示了全球大流行的到来及其规模时,政客、记者和大多数公众评论员却仍将其视为一种遥远的可能性或局部现象。
他指出,尽管AI在执行编程或网站设计等任务时仍会犯错,但人们因此断言其无法达到人类水平或影响甚微是“一种奇怪的现象”,正如几年前人们还认为AI编程是“科幻小说”。
人们注意到,虽然AI现在可以编写程序、设计网站等,但它仍然经常犯错或走向错误的方向,然后他们不知何故就得出结论,认为AI永远无法在人类水平上完成这些任务,或者只会产生微小的影响。
Schrittwieser的核心论点基于两项关键研究:METR和OpenAI的GDPval。数据显示,AI模型自主完成复杂任务的时长正以指数级速度翻倍,最新的模型已能处理超过两小时的软件工程任务。更重要的是,在覆盖44个职业的GDPval评估中,顶尖AI的表现已“惊人地接近”人类水平,甚至开始挑战行业专家的能力。
在这篇题为《再次未能理解指数级》的博客文章中,Schrittwieser将当前对AI的怀疑论调比作“自欺欺人”,认为人们因关注当下的不完美而低估了即将到来的变革规模。

软件任务能力:每7个月翻一番
为反驳AI“平台期”论调,Schrittwieser首先引用了独立评估机构METR发布的《衡量AI完成长任务的能力》研究。该研究衡量AI模型能自主执行软件工程任务的长度,结果显示出“清晰的指数级趋势”。
根据该研究,7个月前的模型Sonnet 3.7已能以50%的成功率完成长达一小时的任务。而METR网站上的最新图表则进一步证实了这一趋势的延续性。
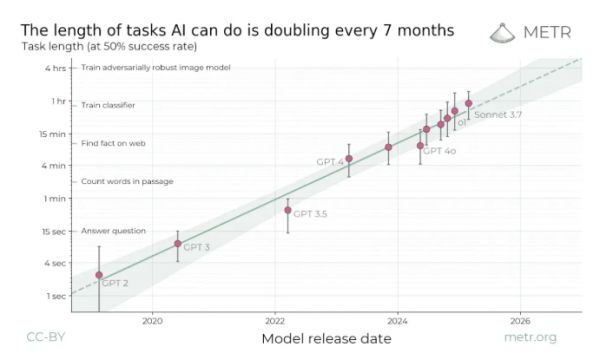
Schrittwieser指出,包括Grok 4、Opus 4.1和GPT-5在内的新模型不仅延续了趋势,“这些最新模型实际上略高于趋势,现在能执行超过2小时的任务!”
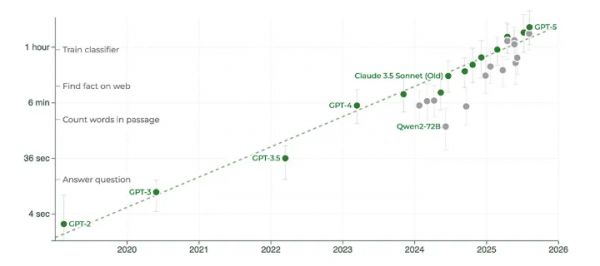
跨越代码:在44个职业中追赶人类专家
针对“AI仅在软件工程领域表现出色”的质疑,Schrittwieser引用了OpenAI发布的另一项名为GDPval的评估。该研究旨在衡量模型在更广泛经济活动中的表现,涵盖了9个行业的44个职业,任务由平均拥有14年经验的行业专家提供。
结果再次呈现相似趋势。Schrittwieser写道,最新的GPT-5已“惊人地接近人类表现”。
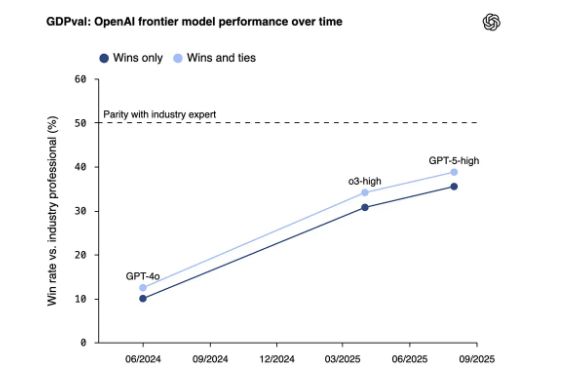
更有说服力的是,早于GPT-5发布的Claude Opus 4.1在该项评估中表现更佳,其性能“几乎与行业专家的表现相匹配”。Schrittwieser特别对此评论:“我在这里要特别赞扬OpenAI发布了一项评估,显示了另一家实验室的模型超越了他们自己的模型——这是诚信和关心有益AI成果的好迹象!”
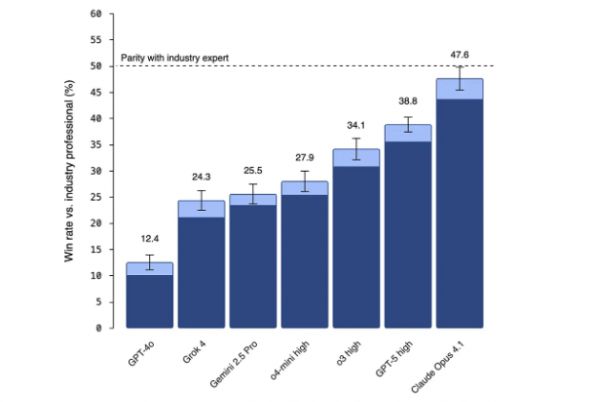
展望2026:AI经济整合的“关键一年”
基于上述跨越多年和多个行业的指数级增长数据,Schrittwieser认为,若这些改进突然停止将是“极其令人惊讶的”。他给出了一个基于趋势外推的清晰预测:
到2026年中,模型将能够自主工作一整个工作日(8小时)。
到2026年底,至少有一个模型将在许多行业中达到人类专家的表现水平。
到2027年底,模型在许多任务上将频繁超越专家。
他总结道,未来的模型可能会比专家更好。
这听起来可能过于简单,但通过推断图表上的直线进行预测可能会给你一个比大多数“专家”更好的未来模型——甚至比大多数实际领域专家更好!
相关推荐
对AI的质疑,是“自欺欺人”?
人民日报:瑞幸咖啡的自欺欺人是在折损中国企业声誉
中国芯片产业要发展,大家首先别自嗨,别自欺欺人
AI对新闻业最大的意义,是生产边角料
关于MIT博士论文造假:相信并加大质疑AI声称的最美好的东西
今日之AI,能否回应“中文屋”的质疑?
以功耗质疑5G是个无知的笑话
苹果AI新功能体验平淡 外媒质疑换皮Siri
患者用DeepSeek“质疑”医生,真能“不信医生信AI”?
业界对AI态度不一?科技CEO称从业者和投资人对AI是两种心态:从业者是渐进的,投资人是乐观的
网址: 对AI的质疑,是“自欺欺人”? http://m.xishuta.com/newsview142544.html
