首创双NPU架构一鸣惊人,联发科天玑9500重磅加码主动式AI体验
本文来自微信公众号:量子位 (ID:QbitAI),作者:关注前沿科技,原文标题:《首创双NPU架构一鸣惊人!联发科天玑9500重磅加码主动式AI体验》
一个问题,在当前的智能手机中,如果AI需要成为具有自主意识、会主动实现功能的“常驻能力”,而不只是一个需要频繁被动焕新的“功能模块”,什么样的芯片架构才能真正跟得上这样的改变?
联发科给出的答案是:以更犀利的算力和更友好的能效表现,创造超性能+超能效双NPU架构,始终让“AI Always on”。
这是一次从技术形态到使用方式的转变:目的是让AI不再依赖被动唤醒,而是作为系统能力始终在线、随时响应,融入用户的每一次操作。
这一趋势正在形成共识。
随着大模型下沉,端侧AI的使用频率越来越高,从输入法里的预测补全,到拍照时的构图建议,从锁屏摘要到图像生成,AI正在从“调用一次”变为“时刻可用”。
为此,SoC不仅要能跑得快,更要让AI跑得久、跑得稳,甚至在用户毫无察觉的情况下完成实时响应。
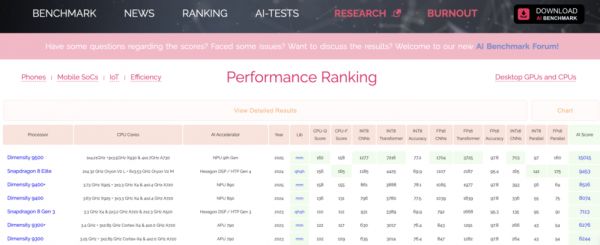
天玑9500围绕这一目标重构芯片底座:首发双NPU架构,结合存算一体、硬件压缩等多项关键技术,在ETHZ苏黎世移动SoC AI榜单中蝉联榜首,相比上一代跑分翻倍。
显然,联发科不仅追求生成速度的提升,更意在构建AI在终端常驻运行所需的基础条件。
AI能力Always on
天玑9500正在让手机的AI变得更快、更聪明,也更贴近你的使用节奏。
写文案、整理想法、扩写内容、总结语音笔记……这类需要组织语言、梳理思路的任务,现在可以更快完成。
3B大模型在天玑9500上的输出性能相比上一代提升100%,内容生成更快、更流畅,连续输出时思路更连贯。
当输入变长,它也能高效处理。
天玑9500支持128K上下文窗口,是上代的4倍,能一次性读入相当于10小时录音的数万字文本。
对于会议记录、采访稿、对话内容等长文材料,它可以根据要求快速提取重点,显著减少整理所需时间。
在文生图任务中,天玑9500支持的DiT模型推理性能提升100%,首次实现端侧4K超高画质生图,仅需10秒即可完成生成。
你可以根据一句文字描述,快速获得高质量图片,不依赖云端、不限网络环境,适合随时创作、分享或作为创意素材打底。
你可以用已有图片为基础,自定义输出风格,例如将照片转为手绘、插画、水彩风,或套用特定艺术滤镜。在表达创意的同时,也提升了图像内容的独特性和辨识度。
为了让这些能力真正服务于日常场景,联发科与手机厂商也在深入合作,共同推动端侧AI落地。
vivo与联发科基于天玑9500联合打造了蓝心AI录音机、分钟级训练的定制美颜,以及全场景的蓝心大模型端侧推理与训练能力;

OPPO则在小布识屏与AI意图搜索上,与天玑9500进行异构计算和内存优化协同,还有更多品牌正与联发科围绕天玑9500展开端侧AI能力部署探索。
不只是生成和理解,天玑9500也具备了一种全新的AI运行方式,让AI能力在手机中保持持续在线。
这意味着,部分AI功能可以常驻系统后台,无需反复唤醒,也不会影响你的使用节奏。比如在拍照时,它会自动运行,实现帧帧追焦,即使你不停移动,焦点也能始终准确锁定,画质清晰稳定,达到单反级水准。
“AI Always on”不是某一项功能,而是一种新的运作方式,让AI真正融入日常使用,在不打扰你的情况下,持续提供帮助。
超性能+超能效,首创双NPU架构
要让端侧AI真正进入日常应用,实现“Always on”的常驻智能体验,必须从硬件架构开始重构运行基础。
天玑9500围绕这一目标,首次提出“双NPU”设计,通过超性能核与超能效NPU协同工作,构建了一套真正面向AI常驻场景的系统方案。

超性能NPU990面向高强度推理任务,搭载全新深层次AI引擎2.0,核心算法调度与执行结构全面重构,支持大模型在本地高效运行。
在ETHZv6.0.3测试中,其得分达到15015,相比天玑9400提升超过一倍,展现出极强的通用算力与生成能力,继续实现AI性能的霸榜。
这一性能奠定了AI助手在本地完成摘要、翻译、命名等复杂任务的能力基础,也为后续常驻化提供了算力保障。
超能效NPU则专注于AI功能的低功耗常驻场景,是支撑“Always on”体验的关键组件。
其首次采用存算一体架构,将传统架构中分离的计算单元与缓存单元进行物理融合,避免高频数据搬移带来的冗余能耗。得益于此,天玑9500可显著改善常驻AI任务下的发热与续航问题。
为了量化能效表现,联发科引入“能效曲线竞争力”分析体系,实际测得该架构在3~4W功耗区间内,推理效率相比天玑9400提升56%。
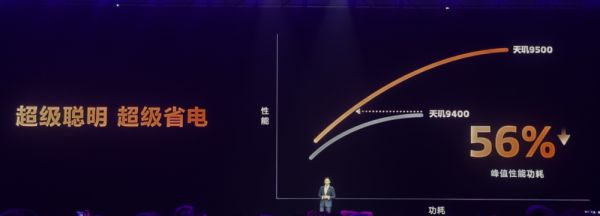
相比传统只能在峰值性能中“跑分”的设计,这一架构重心明确落在真实使用条件下的性能释放,真正支撑起AI的持续在线与多轮交互。
与硬件架构革新同步,天玑9500还在系统层面对端侧AI落地面临的三大关键问题给出了解决路径。
模型加载速度慢,AI助手启动时延迟高,用户体验割裂;
模型驻留内存时功耗高,设备易发热,续航难以保障;
端侧模型训练内存占用过大,定制化和个性化能力难以部署;
针对这些挑战,天玑9500引入三项系统级技术方案——
在加载阶段,首发四通道UFS 4.1,打破传统带宽瓶颈,模型加载速度提升40%;
在内存调度上,结合硬件级压缩,4B大模型在1.6GB内即可运行,即使在DRAM资源有限的场景中也能稳定部署;
在推理阶段,1.58bit量化、专用Transformer电路与Eagle推理加速算法三项技术协同发力,生成速度比天玑9400提升2倍以上,保障多轮交互响应的连贯性与即时性;
在训练端,天玑9500配合vivo自研算法对端侧训练链路进行压缩与结构优化,将内存需求降至2GB,首次实现在终端侧完成个性化美颜等训练任务,让模型能够随着用户使用不断进化。
多项技术叠加之后,围绕加载慢、功耗高、训练难这三大典型挑战,天玑9500已经从硬件到底层算法形成了一套系统级应对方案,打通了从模型唤醒、持续运行到个性化优化的完整链路。
但架构革新与系统整合的意义远不止于此。
这些技术不仅是对痛点的响应,更是为AI从“可调用”走向“默认在线”的状态提供支撑。
在天玑9500上,AI能力不再是某个应用场景中的附加项,而是贯穿图像、语音、文字、传感器等多模态输入的系统能力,随时响应、主动协同。
也正因此,天玑9500的双NPU设计不是一次单纯的性能演进,而是一场围绕端侧AI运行机制的深层次重建。
AI能力融入原生操作流程
为什么移动AI的演进方向指向“Always on”的端侧形态?这并不是一个“端”与“云”的路线抉择,而是源于用户行为习惯与AI使用方式的同步演变。
在AI进入移动设备早期,它的存在往往是显式的、阶段性的——用户有具体操作,AI才启动响应,交互模式以“工具使用”为核心。
但今天,这种交互逻辑正在改变。
越来越多的AI能力开始融入用户的原生操作流程,成为交互的一部分。
这种转变带来一个核心前提:响应需要是即时的,不可依赖被动加载或临时唤醒。
换句话说,AI如果想要发挥“主动服务”的价值,就需要常驻于系统之中,成为设备资源调度的一部分,而非外挂式工具。
在这个意义上,Always on不仅是硬件运行状态,更是面向交互体验的一种基础能力。
只有AI能力常在,系统才能实现及时响应,才能支撑从人发出指令到AI感知意图之间的过渡阶段。
而这种即时性,正是推动“无感交互”成为可能的关键条件。
当用户不再需要明确表达请求,系统便已给出恰当响应,AI也就从“辅助功能”逐渐变为“使用默认”。
这也意味着,端侧AI将不再局限于某类特定任务,而是开始在系统各层持续参与,推动人机交互朝着更自然、更流畅的方向演进。在这一背景下,联发科提供了一套具有现实落地能力的技术组合。
通过超性能+超能效的双NPU架构覆盖高性能与高能效场景,通过系统级整合解决加载、推理、训练等关键瓶颈,天玑9500为AI从“尝鲜”走向“好用”提供了坚实支撑。
AI真正融入日常,不仅取决于模型本身有多强,还取决于底层系统是否准备好为它持续供能。
这一代的天玑9500,正在让这种准备成为现实。
相关推荐
联发科天玑9500现身基准测试:采用“1+3+4”CPU架构,频率达4.21GHz
联发科AI超给力,天玑9400迈向新高度
联发科天玑9500早期规格曝光,CPU或继续升级
联发科天玑9500将采用台积电2nm制程
天玑9500再次被确认:CPU架构更换,且配备全新CSS技术!
联发科打响手机芯片“卷AI”的第一枪
性价比优势突出,传联发科天玑9400已热销到“缺货”
深挖天玑9400潜力!联发科联手vivo打造旗舰标杆
天玑9400再曝:联发科参与黑鹰架构设计!性能、能效全面升级
联发科COMPUTEX展出先进AI技术,打造顶尖智能座舱体验
网址: 首创双NPU架构一鸣惊人,联发科天玑9500重磅加码主动式AI体验 http://m.xishuta.com/newsview142164.html