Mini-Omni-Reasoner:实时推理,定义下一代端到端对话模型
(来源:机器之心)

本文第一作者谢之非,共同第一作者马子阳皆是来自于南洋理工大学的博士生。通讯作者为新加坡国立大学特聘教授颜水成和南洋理工大学数据与科学系校长讲席教授苗春燕。共同作者为腾讯AI首席专家叶德珩和新加坡国立大学博士后研究员廖越。
两千多年前,孔子说过「三思而后行」。这句古老箴言,其实点出了人类面对复杂问题的核心智慧:一步步推理,层层拆解,最终做出可靠的决策。
现在,已有诸多模型在复杂推理方面展现出显著进展,如 DeepSeek-R1 和 OpenAI o1,部分多模态系统甚至能够处理跨领域的复杂任务,展现出解决复杂现实问题的潜力。然而,在端到端对话模型中,推理能力尚未解锁。
原因并不复杂。深度思考意味着模型往往需要在输出前生成完整推理链,而这直接带来延迟。对于语音对话系统而言,速度与质量同样关键。一旦停顿过长,哪怕答案再精妙,也会破坏交互的自然感。
设想一个场景:你问语音助手「这份研究报告的结论可靠吗?」。如果模型沉默十秒才给出语音的回复,则完全失去对话的体验;若它立刻回答,但推理缺乏深度,又容易显得表面化。问题在于:要么得到一个「强大但反应迟钝」的助手,要么得到一个「迅速但思维简单」的助手。鱼与熊掌,似乎不可兼得。
基于这一挑战,我们提出了 Mini-Omni-Reasoner——一种专为对话场景打造的实时推理新范式。它通过「Thinking-in-Speaking」实现边思考边表达,既能实时反馈、输出自然流畅的语音内容,又能保持高质量且可解释的推理过程。

论文标题:MINI-OMNI-REASONER: TOKEN-LEVEL THINKING-IN-SPEAKING IN LARGE SPEECH MODELS
论文链接:https://arxiv.org/pdf/2508.15827
项目主页:https://github.com/xzf-thu/Mini-Omni-Reasoner
Mini-Omni-Reasoner:
边思考,边表达
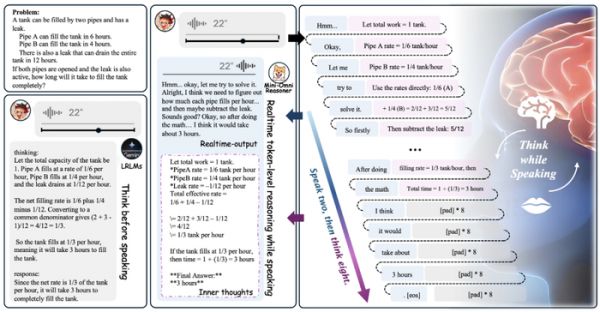
让我们暂时把视角放回人类自己。当一个人面对复杂问题时,往往不是「想完再说」,而是「边说边想」。当被问到「如何理解人工智能的未来」时,大多数人不会先默默推理数分钟再完整输出结论,而是会边思考边组织语言:「这个问题挺复杂的……我觉得可以从技术和社会两个层面来看……」
Mini-Omni-Reasoner 正是受到这一启发,探索「边思考,边表达」的新范式。它允许模型在生成回答的同时进行内部推理,实现 token 级别的思维流与输出流交替生成。这样既能保留逻辑深度与可解释性,又能提供自然、低延迟的交互体验。
「一心二用」——如何在大模型中实现?
「Thinking-in-Speaking」推理范式:传统推理模型遵循「thinking-before-speaking」路线:先完整生成推理链,再一次性给出答案。逻辑虽完整,但交互性差,用户必须等待较长时间。尤其在语音交互场景下,这种长时间的停顿极大削弱了使用体验。
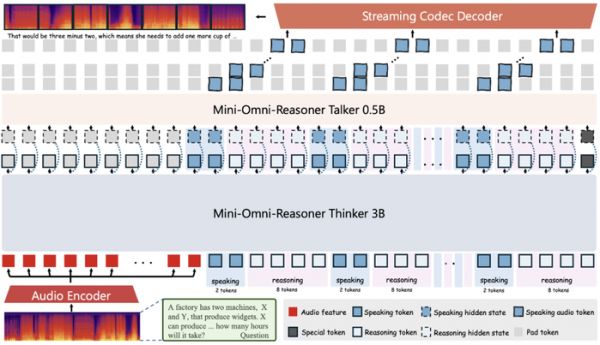
Mini-Omni-Reasoner 提出的则是「thinking-in-speaking」范式。模型在生成过程中同时维护两条流:回答流(response stream)和推理流(reasoning stream)。二者像两支交错前进的队伍,一边输出用户可听到的回答,一边在后台继续进行逻辑演算。
通俗理解为:模型循环输出 p 个回答 token + q 个推理 token,直到完成任务。用户感受到的是自然、几乎无停顿的对话,而模型在内部始终维持严谨的推理链。整个推理过程如下。
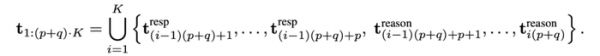
这种机制突破了「要么快,要么准」的二元困境,让「会想、会说」真正成为可能。
模型架构:Mini-Omni-Reasoner 采用了 Thinker-Talker 架构,像一对分工明确的搭档:
Thinker:大脑担当,负责语音理解和逻辑推理,交替产出回答 token 和推理 token。内部结构是「音频编码器 + 大模型」。
Talker:嘴巴担当,只负责把回答 token 变成语音,而对推理 token 保持沉默,确保输出始终简洁、自然。
这种解耦方式的好处很直观:Thinker 全力搞逻辑,Talker 专心搞对话,谁也不分心。
2:8 Token 交替设计:我们最终选择了 2:8 的回答–推理 token 比例,背后有几层考量:
推理比例更高 → 思维更完整,但可能反应太慢,实时性差。
回答比例更高 → 说得快,但容易「说过头」,逻辑没跟上,甚至产生幻觉。
Chunk 过长 → 不管是全推理还是全回答,都会带来延迟或质量问题。
结合实验结果,我们发现推理链长度大约是回答的 2~3 倍,因此 2:8 是一个平衡点:既保证推理深度,又能保持实时语音合成的流畅性。比如,当模型每秒生成 50 token,就能给用户带来 10 个回答 token——对实时对话来说已经非常充裕。
「点石成金」——四阶段数据合成管线
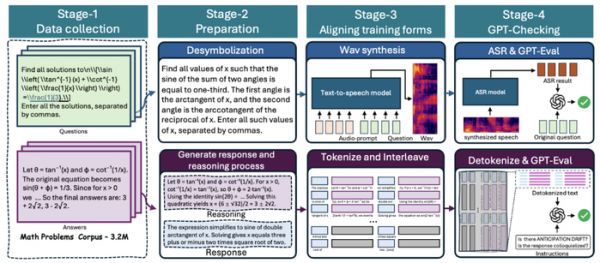
仅有架构还不够,要真正掌握「边思考边表达」,还需要精心设计的数据与训练流程。为此,我们构建了 Spoken-Math-Problems-3M 数据集,并设计了严谨的数据管线。
在数据构建中,我们面临一个核心挑战——解决**「逻辑错位」(Anticipation Drift)**问题。即如何防止模型在回答时「抢跑」,说出推理流中尚未得出的结论。我们为此设计了两大核心策略:
异步推理机制:我们在数据层面「教会」模型一种新的说话艺术。在回答流中,先说一些「铺垫语境」的话,为后续的推理争取时间;而在推理流中,则要求模型「开门见山」,直奔主题,不讲废话。
反序列化验证:我们像一位严格的考官,将所有交错的 token 重新组合成自然语言文本,然后利用强大的 GPT 模型进行语义和时间一致性检查,剔除所有逻辑不连贯或存在「超越」现象的不合格样本。
通过上图中的四阶段数据管线,我们为 Mini-Omni-Reasoner 提供了超过百万份高质量的训练数据。
「百炼成钢」——五阶段训练方法
训练 Mini-Omni-Reasoner 需要一个精心设计的五阶段管线,因为模型不仅引入了定制化架构,还采用了全新的输出形式。为了确保稳定收敛并有效将文本推理能力迁移到语音,我们将训练过程分解为五个逐步递进的阶段,总体思路为先在文本模态中保持或增强推理能力,再将其与语音模态对齐。
对齐训练:我们从 Qwen2.5-Omni-3B 初始化模型,解决架构不兼容问题,并先只微调音频适配器,使用语音问答和对话数据桥接语音编码器与 LLM 主干的接口,然后解冻除音频编码器外的所有模块,适应新加入的特殊 token,确保模型在定制化 token 格式下无缝工作。
混合数学预训练:在模型对齐后,我们增强其数学推理能力,使用标准的「先推理再说话」数据集(包括文本和语音形式)进行预训练,确保在引入 token 级交错生成之前具备扎实的推理能力和数据对齐。
文本 thinking-in-speaking 训练:在文本模态中训练模型交替生成推理 token 和回应 token,仅更新语言模型参数,专注于掌握交错推理-回应结构,不涉及语音变化。
语音 thinking-in-speaking 训练:将输入替换为语音,仅微调音频编码器,保持 LLM 固定,使模型能够在语音条件下保持推理增强的生成方式,实现推理范式在模态间的迁移。
Talker 训练:最终阶段训练说话模块,实现流畅自然的语音生成,整个 Thinker 组件冻结,仅训练 Talker 以将交错输出转换为语音,同时保留前面阶段建立的逻辑基础和推理能力。
「真金火炼」——实验数据与案例分析
为了验证 Mini-Omni-Reasoner 的有效性,我们在 Spoken-MQA 数据集上测试了模型与多种不同类型方法的对比,模型相比于基座模型 Qwen2.5-Omni-3B 有明显的性能提升。
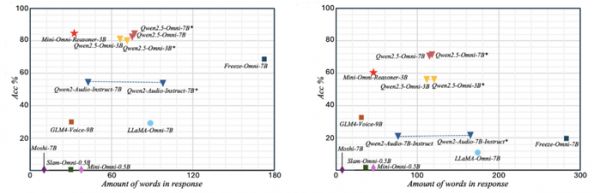
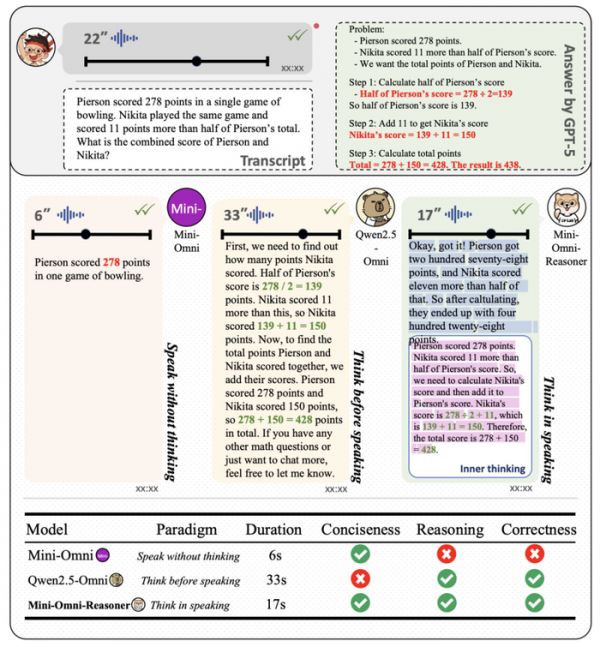
为了进一步展现 Mini-Omni-Reasoner 与传统的对话模型和基础模型 Qwen2.5-Omni 模型的区别,我们分析了针对同样问题不同模型的回答结果:实验证明「Thinking-in-Speaking」方法可以有效地在保持回复内容自然简洁的情况下保持高质量的推理过程。
结语
当下,大模型的推理能力已逐渐成为解决复杂问题的核心驱动力。但遗憾的是,这一能力在对话系统中仍未被真正释放。为此,我们提出了 Mini-Omni-Reasoner——一次早期的尝试。诚然,它距离成熟应用还有很长的路要走,但「thinking-in-speaking」的实时推理机制,我们相信正是对话模型迈向复杂问题解决的必经之路。
展望未来,我们认为至少有几个值得深入探索的方向:
如何科学地评测模型在通用问题上的推理增益,如「人生的意义是什么」;
如何让对话模型自主决定何时需要「思考」;
如何突破固定比例生成,探索更灵活多样的思维范式。
总的来说,Mini-Omni-Reasoner 并非终点,而是一个起点。我们更希望它能成为抛砖引玉,引发学界和产业界对「对话中的推理能力」的持续关注与探索。
相关推荐
Mini-Omni-Reasoner:实时推理,定义下一代端到端对话模型
OpenAI发布端对端语音模型GPT-Realtime,助力开发者构建语音智能体
独家对话Soul App CTO:看好多模态端到端大模型落地社交,新能力预计年底上线
苹果AI“百亿补贴”来了:免费开放端侧模型
让AI像人一样开车,端到端模型如何解码自动驾驶?
手机端生成模型爆发在即,芯片迎来巨变?
端侧大模型,手机厂商的下一次入口级机会
下注端到端:一场具身智能的谨慎豪赌
端到端精度暴涨19.61%!华科&小米汽车打造自动驾驶框架ORION
某新势力端到端负责人“休假”,智驾三大高管已走俩!
网址: Mini-Omni-Reasoner:实时推理,定义下一代端到端对话模型 http://m.xishuta.com/newsview142105.html