BigGAN被干了,DeepMind发布LOGAN:FID提升32%,华人一作领衔
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者:鱼羊 ,36氪经授权发布。
上看,下看,左看,右看。从各个角度看美食,真是让人越看越饿。

而有个不知道是好消息还是坏消息的事实是:这些食物从未真实存在过。
不错,这是DeepMind最新推出的LOGAN生成的“伪美食图鉴”。
这只GAN初登场就击败了“史上最强”的BigGAN,成为新的state-of-the-art,还把FID和IS分别提高了32%和17%。
什么概念?简而言之,就是LOGAN可以生成更高质量和更多样化的伪照片。
左边是BigGAN(FID/IS:5.04/126.8),右边是LOGAN(FID/IS:5.09/217)。
同样的低FID条件下,LOGAN可比BigGAN靠谱多了。

△左边是BigGAN,右边是LOGAN
而不考虑FID,在相似的高IS条件下,虽然生成的食物都一样真实,且热量爆炸,但显然LOGAN的姿势水平会更加丰富。

并且,DeepMind表示:无需引入任何架构变化或其他参数。
潜在优化
DeepMind采用的方法,是引入了一种受CSGAN启发的潜在优化(latent optimisation)。
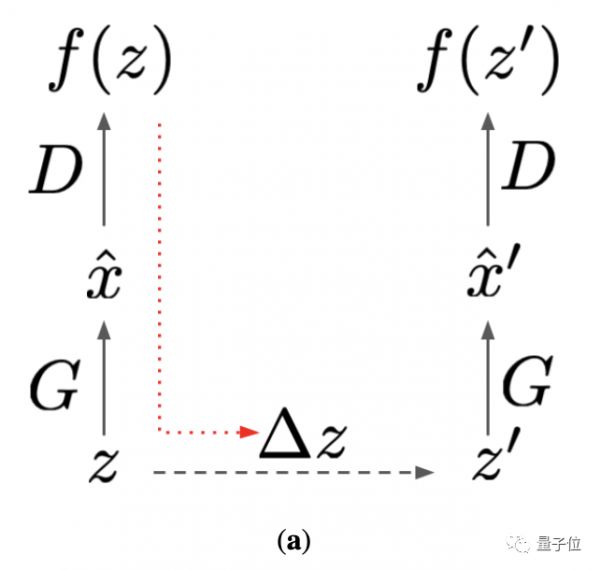
首先,让潜在变量z,通过生成器和判别器进行前向传播。
然后,用生成器损失(红色虚线箭头)的梯度来计算改进的z’。
在第二次前向传播中,使用优化后的z’。其后,引入潜在优化计算判别器的梯度。
最后,用这些梯度来更新模型。

这一方法的核心,其实是加强判别器和生成器之间的交互来改善对抗性。
GAN中基于梯度的优化存在的一个重要问题是,判别器和生成器的损失产生的矢量场不是梯度矢量场。因此,不能保证梯度下降会找到局部最优解且可循环,这就会减慢收敛速度,或导致模式崩溃、模式跳跃现象。
辛梯度调节算法(SGA)可以在普通博弈中寻找稳定不动点,能改善对抗中基于梯度的方法的动态性。不过,因为需要计算所有参数的二阶导数,SGA的扩展成本很高。

潜在优化可以只分别针对潜在变量z和和判别器、生成器参数,使用二阶导数,来达到近似SGA的效果。
如此,就不必使用计算代价高昂的涉及判别器和生成器参数的二阶项。
简而言之,潜在优化最有效地耦合了判别器和生成器的梯度,且更具可扩展性。
并且,LOGAN受益于强大的优化器。研究人员使用自然梯度下降(NGD)进行潜在优化时发现,这种近似二阶优化方法比精确二阶方法表现更好。
虽然NGD在高维参数空间中同样代价高昂,但即使在非常大的模型中,它对于潜在优化也是有效的。
从实验结果来看,潜在优化明显改善了GAN的训练效果。
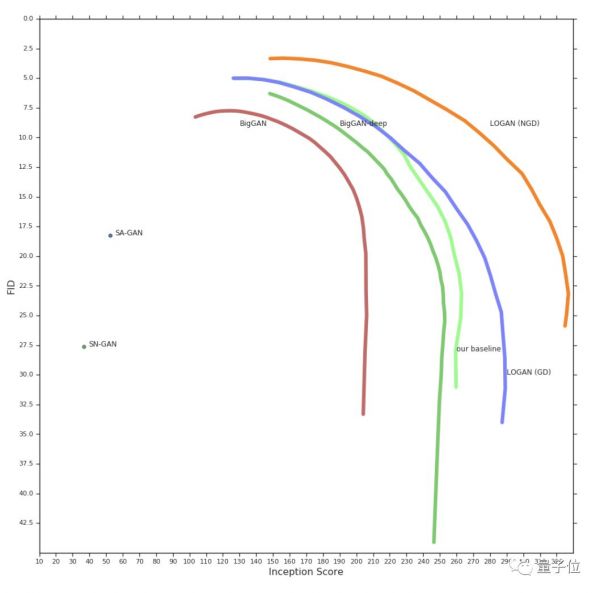
采用和BigGAN-deep基线相同的架构和参数数量,LOGAN在FID和IS上都有更好的表现。

不过,在训练期间,因为额外的前向和后向传播,LOGAN每一步的速度比BigGAN慢2到3倍。
华人一作领衔
论文一作,是DeepMind的研究科学家Yan Wu。
他于2019获剑桥大学计算神经科学博士学位,16年进入DeepMind工作。

论文的其他几位作者,分别是毕业于UC伯克利的Jeff Donahue博士。
毕业于芝加哥大学数学专业的David Balduzzi博士。
Vision Factory创始人Karen Simonyan。
以及伦敦学院大学客座教授、毕业于皇后大学的系统神经科学博士Timothy Lillicrap。
传送门:
论文地址:https://arxiv.org/abs/1912.00953
相关论文:
SGA:https://arxiv.org/abs/1802.05642CSGAN:https://arxiv.org/abs/1901.03554
封面图来自pexels
相关推荐
BigGAN被干了,DeepMind发布LOGAN:FID提升32%,华人一作领衔
DeepMind爆出无监督表示学习模型BigBiGAN,GAN之父点赞
NeurIPS 2019放榜:华人作者贡献42%,谷歌170篇屠榜;国内清华第一,腾讯领衔产业界
人均年薪400万、公司年亏40亿,正在盖大楼的DeepMind最新财务数据曝光
突发,一年烧掉40亿元后,DeepMind联合创始人“被休假”
ICLR 2020 全析解读:华人作者贡献60%,谷歌、卡内基梅隆和清华大学领跑前三
人类对大脑多巴胺机制理解错了,顶级版AlphaGo背后技术启发脑科学,DeepMind最新成果登上Nature
谁在让字节“跳动”?张一鸣领衔14大将,106位高管架构首次曝光
谷歌DeepMind联合创始人被架空,目前仍在休长假
诺诚健华通过港交所聆讯,施一公领衔基金大佬加持,核心产品已在华申报上市
网址: BigGAN被干了,DeepMind发布LOGAN:FID提升32%,华人一作领衔 http://m.xishuta.com/newsview14184.html