DeepSeek V3到V3.1,走向国产算力自由
从V3到V3.1,DeepSeek正在探索出一条“算力自由”之路。
从魔改PTX到使用UE8M0 FP8 Scale的参数精度,DeepSeek先榨取英伟达GPU算力,再适配国产芯片,可能会在软硬件协同方面带来新的突破,进一步提高训练效率,最多可以减少75%的内存使用,从而在实际应用中减少对进口先进GPU芯片的依赖。
DeepSeek正在与下一代国产GPU芯片厂商一起,向算力自主又迈进一步。正是这样一种令人激动的前景,激活了科技色彩愈发浓厚的中国资本市场。
V3.1,迈向Agent时代
DeepSeek发布了V3.1,而不是广受期待的V4或者R2,连R1也消失了。DeepSeek变成了一个混合推理架构,即一个模型同时支持思考模式和非思考模式。这是一个趋势,在V3.1发布一周之前,GPT-5发布了,这是一个”统一的系统”,包括一个对话模型,一个思考模型,和一个实时路由,用来决定如何结合对话与思考。
这次升级提高了DeepSeek的思考效率,即答对同样的问题,可以消耗更少的token,花费更短的时间。这既出于经济上的考虑,也出于产品和用户体验方面的考虑,避免过度思考,让回答更简洁一些。
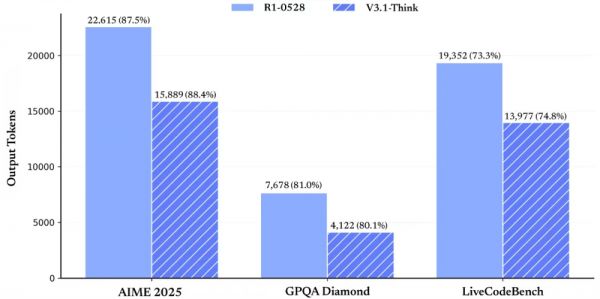
V3.1展示出更强的Agent能力,通过后训练的优化,新模型在工具使用与智能体任务中的表现有较大提升。
V3.1的基础模型在V3的基础上重新做了外扩训练,增加训练了840 B token。它的上下文长度、思考模式和非思考模式均达到了128k。性能提升,价格下降,再次秀出它所擅长的性价比创新。
这次升级让DeepSeek在最近中国AI企业的开源热潮中夺回领先优势,但不仅仅是想用来做科研和展示,而是要在企业服务能力上向国际前沿AI企业看齐。
DeepSeek的API Beta接口支持了strict模式的Function Calling,以确保输出的Function满足schema定义。这其实是大模型API在工程化能力上的一个重要升级。OpenAI、Anthropic、Mistral等都在逐步推出strict function calling,向企业级生产环境对齐。Strict模式提升了V3.1的工程可靠性和企业易用性,使其更容易在企业服务中替代GPT/Claude。
同样的思路,DeepSeek也增加了对Anthropic API格式的支持,“让大家可以轻松地将DeepSeek-V3.1的能力接入Claude Code框架。”目的是让使用Claude Code的用户更便捷地切换到DeepSeek。这样可以直接渗透Anthropic已经打开的企业市场。最近,Anthropic的企业服务收入已经超过了OpenAI。
这次升级对于DeepSeek具有里程碑式的意义,是其迈向Agent时代的第一步。对中国的AI芯片生态也同样如此。
深度求索的深水炸弹
DeepSeek在中文官微刻意强调,而在其英文X账号上没有提及的是,V3.1使用了UE8M0 FP8 Scale的参数精度。它还在留言处置顶:
这年头,越是低调、话少、让人有点看不懂,信息量越大。
在Hugginface的模型卡中,DeepSeek又放出了一点信息:DeepSeek-V3.1使用UE8M0 FP8缩放数据格式进行训练,以确保与微缩放数据格式兼容。
简单解释下,FP8=8-bit floating point(8位浮点数)是一种超低精度表示方式。可以显著减少显存/带宽需求,大幅提升推理和训练效率,但需要精心设计缩放(scaling)来避免数值不稳定。
UE8M0是FP8的一种数字表示格式。U表示没有符号,E8表示8位指数,M0表示没有尾数。相比之下,英伟达在H100、Blackwell GPU上提供硬件级FP8支持,主推E4M3/E5M2格式,大多数模型采取的是英伟达官方的FP8格式。
所谓“微缩放数据格式”(Microscaling data format),即业界的Microscaling FP8(MXFP8)标准。英伟达Blackwell GPU支持MXFP8。而V3.1训练所用的数值体系与MXFP8兼容,模型在推理/部署时,可以直接在任何支持MXFP8+UE8M0的硬件(包括英伟达Blackwell、未来的国产GPU)上跑,不需要额外转换,这能降低内存流量、提升矩阵乘法吞吐。
对比一下E4M3/E5M2,UE8M0是一个变体,全指数,无尾数,能覆盖极宽的动态范围,是一种低算力环境下的工程优化。单就UE8M0而言,其没有尾数,也没有精度,只用来存scale。高精度在内部计算中的使用过程是这样的:输入FP8,存储时用scale调整,计算时自动转换FP16/BF16/FP32,做乘加运算,输出时再量化回FP8存储,这就保证了训练、推理的稳定性。
V3.1在训练中使用UE8M0 FP8,并且兼容MXFP8,通过软件定义与更多芯片适配,能让超低精度训练/推理在中国自研芯片上更容易实现。
目前和即将采用FP8精度的国产GPU芯片,有寒武纪、沐曦、燧原、昇腾等,还有更多主动适配DeepSeek的芯片厂商。
英伟达的低精度之路
值得一提的是,英伟达多年来一直用低精度数字表示法提升推理和训练效率。例如在所谓的“黄氏定律”中,过去十年里,GPU实现的千倍效能提升,新的数字格式起到了最重要的作用。
英伟达的首席科学家戴利(Bill Dally)曾经把数字表示概括为GPU算力”黄氏定律“的精髓。
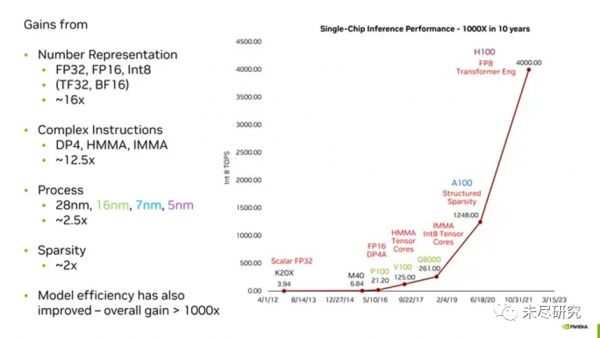
在P100之前,英伟达的GPU使用单精度浮点数表示这些权重。根据IEEE 754标准,这些数字长度为32位,其中23是尾数位,8是指数位,还有一位是符号位。
但是,机器学习研究人员很快就发现,在许多计算中,其数字可以不必有那么高的精度,而神经网络仍然可以给出准确的答案。
这样做的明显优势在于,可以更快、更小、更高效地执行机器学习的关键计算(乘法和累加)逻辑。如果需要,就处理更少的位数(如戴利所解释的,乘法所需的能量与位数的平方成正比)。因此,使用FP16,英伟达将该数字减少了一半。
Google甚至推出了自己的版本,名为Bfloat16。(两者的区别在于分数位的相对数量,这影响精度;以及指数位的相对数量,这影响范围。Bfloat16与FP32具有相同数量的范围位,因此更容易在这两种格式之间切换。)
到了H100这一代,其已经可以使用8位数字执行大规模transformer神经网络的某些部分,例如ChatGPT和其他大型语言模型。然而,英伟达发现,这并不是一种适合所有情况的解决方案。
例如,英伟达的Hopper GPU架构实际上使用了两种不同的FP8格式进行计算,一种具有更高的精度,另一种具有更大的范围。英伟达的窍门在于知道何时使用哪种格式。
英伟达对超低精度的一项研究
加州理工教授、英伟达前研究员Anima Anandkumar指出,V3.1在训练中使用的UE8M0 FP8 scale数据格式,实际上是一种对数数值系统(LNS),来自她当年参与的一个研究项目。
英伟达和加州理工的研究人员在2021年时曾经发表过一篇论文《LNS-Madam:在对数数值系统中采用乘法式权重更新的低精度训练》(LNS-Madam:Low-Precision Training in Logarithmic Number System using Multiplicative Weight Update),探讨如何以低精度表示深度神经网络(DNN),实现高效加速,并减少内存占用。
如果直接用低精度权重进行训练,低精度数值系统与学习算法之间的复杂交互会使得精度下降。为了解决这一问题,研究人员设计了对数数值系统(Logarithmic Number System,LNS)和乘法式权重更新算法(Madam)。
他们证明了LNS-Madam在权重更新过程中能保持较低的量化误差,即使在精度受限的情况下也能获得稳定性能。
他们还进一步提出了一种LNS-Madam的硬件设计,解决了实现高效LNS计算数据通路中的实际挑战,这有效降低了LNS-整数转换和部分和累加(partial sum acculmlation)带来的能耗开销。
实验结果表明,在计算机视觉和自然语言等主流任务中,LNS-Madam仅使用8位精度就能实现与全精度相当的准确率。与FP32和FP8相比,LNS-Madam能分别降低超过90%和55%的能耗。
DeepSeek的超低精度创新
UE8M0实际上等价于LNS的一个极简实现,因此,可以说UE8M0是LNS的一种特化(只保留log值的整数部分,没有小数精度),所以Anandkumar教授才会把UE8M0缩放数据格式称作一种LNS。
如果说LNS-Madam是一种学术探索,是重新设计数学体系+算法,是硬件和算法一体化的设计思路,UE8M0+FP8则是一种在现有浮点体系上结合缩放的工程技巧。二者低精度训练的目标一致,但路线完全不同。
UE8M0并不是用来直接存权重,而是用来存缩放因子(scale factor),帮助其他FP8(E4M3/E5M2)稳定表示数据,让FP8能够覆盖更广的数据分布,从而在硬件上更高效。
追求算力自由
回顾一下DeepSeek在两个阶段的突破点。
首先是先榨干现有硬件的潜力。DeepSeek V3直接修改了英伟达GPU的虚拟机指令集架构PTX,绕过英伟达编译器的保守策略,手工调度寄存器、warp、访存和Tensor Core指令。把GPU算力利用率提升到极限,降低硬件受限下的训练/推理成本。在DeepSeek手中,A100/A800等英伟达GPU上的现有算力都得到了最大化利用。
第二阶段是降低算力的物理需求。DeepSeek V3.1引入UE8M0 FP8格式,让中国国产AI芯片(带宽/算力较弱)也能高效运行大模型。采用更紧凑的低精度浮点格式,大幅压缩内存/带宽占用,减少计算负担,可以期待下一代国产GPU芯片能进行前沿大模型训练推理。
DeepSeek在工程实践中走出了一条算力自主之路:先榨取英伟达,再适配国产芯片,最终走向算力自主。长期来看,DeepSeek将沿着软硬件协同优化的路线,构建一个“算力无关”的模型生态。
中国还需要H20/B30吗
由于技术与安全等原因,已经传出英伟达停止生产H20的消息。目前依然存在悬念的,是黄仁勋是否向中国提供B30。
回顾一下,英伟达定制H20/B30给中国市场,因为美国出口管制禁止向中国出售H100/H200/B100/B200等高端GPU。黄仁勋的策略是推出缩水版芯片,为中国定制了H20(基于Hopper)和B30(基于Blackwell),在算力、互联、带宽上降低配置,但仍保持CUDA生态兼容,以保住中国市场,避免中国厂商快速完全转向国产芯片,同时遵守美国出口管制。
即使DeepSeek魔改PTX,一时造成了英伟达股价暴跌,也并没有影响黄仁勋的策略,老黄反而一直想见梁文锋。因为他在心里明白,也公开表达过,以中国的人才储备,尤其是软件人才储备,实现AI芯片与模型生态的自主闭环只是时间问题。
没想到的是,UE8M0+超低精度的冲击会以如此低调的方式释放。它意味着中国厂商对于H20/B30的需求,正在发生微妙的变化。如果国产下一代GPU芯片近期推出,而且支持UE8M0+FP8跑通大模型,英伟达的缩水卡在中国市场上的竞争力下降。一旦国产芯片生态完善,CUDA生态的锁定效应会逐渐削弱。
中国市场还需不需要B30?有一种业内观点认为,短期依然需要,因为国产GPU的产能、软件生态还在追赶。大部分企业,尤其是互联网大厂和科研机构等,仍依赖CUDA工具链和现成框架。H20/B30在推理与训练上仍然比国产芯片更稳健。也许B30本身的相对先进性,即弱于最先进的GPU、但仍强于国产GPU,才能决定它能否得到中美两国有关部门的接受。
随着国产芯片+超低精度训练将逐渐跑通并规模化部署,中长期来看对于B30们的需求会明显下降。国产AI软件栈(昇腾CANN、寒武纪Neuware、壁仞BIRENSUPA)逐步成熟,逐渐减少对CUDA的依赖。成本敏感的中国企业会更倾向国产方案,同时避免美国找麻烦。
英伟达的优势何在
UE8M0+FP8,好像是DeepSeek接过了英伟达近十年来的低精度数字表示技术的大旗,结合中国的实际进行工程创新,它将加快中国下一代芯片的推出,加快以国产芯片解决中国大规模训练和推理的需求,从而形成中国AI芯片与模型的技术路线。
使用UE8M0 FP8 Scale的参数精度,适配国产下一代芯片,兼容MXFP8,并不意味着英伟达失去了优势主导地位,因为G200不只是FP8,还带来了更大带宽、更强互联(NVLink 5)、更大显存。软件生态(CUDA、PyTorch插件)也牢牢绑定FP8,迁移到UE8M0需要额外工程适配。
大部分国际大厂(OpenAI、Anthropic、Meta)还是会首选G200来追求极致性能。“黄氏定律”已经推进至FP4精度,英伟达还曾亲自下场发布了优化版的DeepSeek-R1-FP4,内存需求大幅降低,基准测试成绩几乎不变。
如果UE8M0+FP8在社区和国产硬件上普及,低成本训练路径会弱化英伟达的必选性。这对中国厂商尤其重要,即使没有G200,也能在国产GPU上稳定训练大模型,形成去英伟达化的路线。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究
相关推荐
DeepSeek V3.1 发布,更令人好奇的是UE8M0 FP8
DeepSeek的545%利润率,是对算力的核弹吗?
DeepSeek上线两天后再回看:一次“小更新”,一场架构“豪赌”
DeepSeek“小版本更新”背后,V3和R1正融合成一个模型
DeepSeek推动AI平权,国产算力迎来价值重估
DeepSeek昨天悄悄扔的炸弹,今天爆了
AI工厂炸场!摩尔线程提速150%,国产算力硬刚英伟达
DeepSeek引爆国产AI芯片:寒武纪、华胜天成、和而泰三大龙头热度爆棚,5000亿“寒王”市值超五粮液
DeepSeek一句话让国产芯片集体暴涨,背后的UE8M0 FP8到底是个啥
DeepSeek算力需求暴降,为什么全球算力竞赛反而更疯狂了?
网址: DeepSeek V3到V3.1,走向国产算力自由 http://m.xishuta.com/newsview140912.html