刚刚,大模型棋王诞生,40轮血战,OpenAI o3豪夺第一,人类大师地位不保?
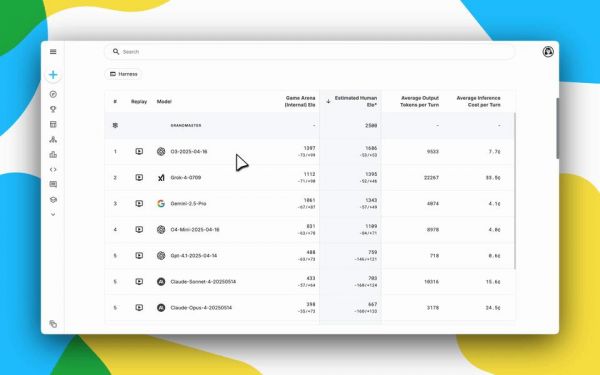
继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
别再拿淘汰赛说事了!
这次是真刀真枪的「积分赛」,Elo榜单才是硬实力。
40轮血战,国际象棋AI仅文本输入结果出炉了。
仅使用文本输入、无工具、无验证器,各大AI模型进行对决。
每组配对进行超过40场比赛,构建了类似围棋等运动项目的Elo排名。

OpenAI o3独占鳌头,Grok、Gemini位列榜眼。
第一名:o3 ,估计人类Elo为1685分,而人类大师水平为2200分!
第二名:Grok 4,估计人类Elo为1395分,表现不错。
第三名: Gemini 2.5 Pro,估计人类Elo为1343分,稍逊一筹。
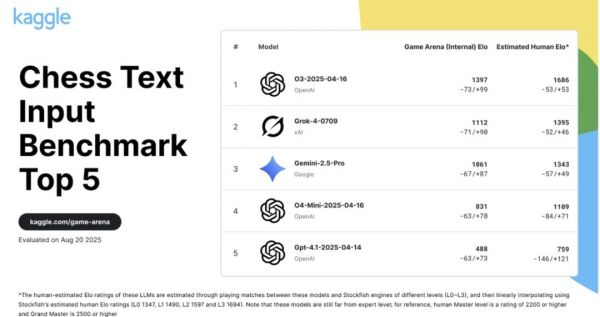
另外,值得一提的是DeepSeek-R1-0528和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
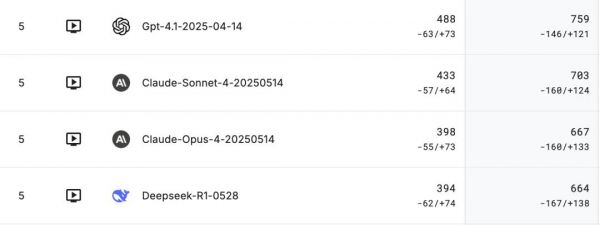
GameArena的首次AI国际象棋比赛, o3最后夺冠,这次这次证明实力。
Game Arena首次积分赛排行榜
之前,Kaggle举办了首届AI国际象棋表演赛,展示了o3、Grok 4、Gemini 2.5、DeepSeek R1等通用模型在国际象棋方面的表现。

这些模型进步明显,大家从中获得了不少乐趣,比如发现大语言模型特别喜欢西西里防御开局。
但四局三胜的淘汰赛偶然性太大,并不能严格衡量模型的真实水平。
因此,今天谷歌旗下的Kaggle正式发布了Game Arena平台上的国际象棋文本排行榜。

排行榜链接:https://www.kaggle.com/benchmarks/kaggle/chess-text/leaderboard
国际象棋文本排行榜是一个严格的AI基准测试平台。前沿大语言模型在此竞技,全面考验它们的战略推理、规划、适应和协作能力。
平台通过透明的测试设计、丰富的游戏数据和不断更新的多游戏排行榜,为评估 AI 的真实认知能力提供了动态且可复现的标准。
国际象棋文本排行榜
该排行榜基于所有参赛模型之间的循环赛结果,每对模型进行20场白棋和20场黑棋的对决,总共40场比赛。
这次还扩大了参赛模型范围,不仅包括上周表演赛的8个模型,还增加了更多模型,以提供更全面、更可靠的评估结果。
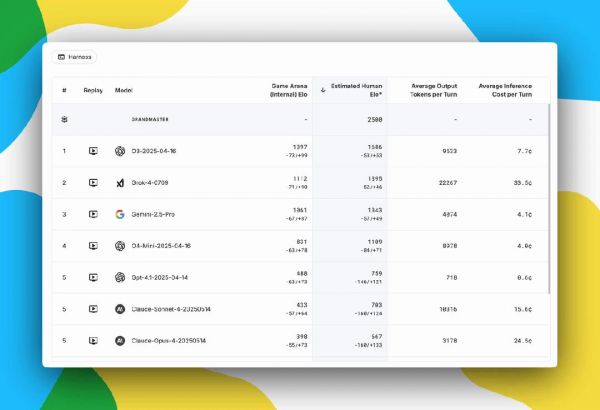
Game Arena的Elo分数采用标准的Bradley-Terry算法,基于模型之间的对战结果计算。
为了估算这些模型的人类等效Elo评分,它们与L0到L3不同等级的国际象棋Stockfish引擎对弈。
通过线性插值法,根据Stockfish各等级对应的人类Elo评分,计算出大模型的人类等效Elo分。具体来说:L0对应1320分,L1对应1468分,L2对应1608分,L3对应1742分。
需要注意的是,这些模型距离顶级人类棋手仍有较大差距:
人类「大师」级棋手的评分为2200或更高,
「特级大师」为2500或更高,
而最强版本的Stockfish引擎估计的人类Elo评分高达3644。
Stockfish是一款免费且开源的国际象棋引擎。

自2020年以来,Stockfish赢得了顶级国际象棋引擎锦标赛(TCEC)和Chess.com计算机国际象棋锦标赛(CCC)的所有主要赛事,并且截至2025年8月,它是世界上最强的CPU国际象棋引擎,估计的Elo等级为3644,
置信区间则通过500次重采样比赛结果,并分别计算Game Arena Elo和人类Elo分得出。
除了Elo分数,这次还增加了「平均每回合Token数」和「平均每回合成本」等指标,以反映模型在性能和效率之间的权衡。
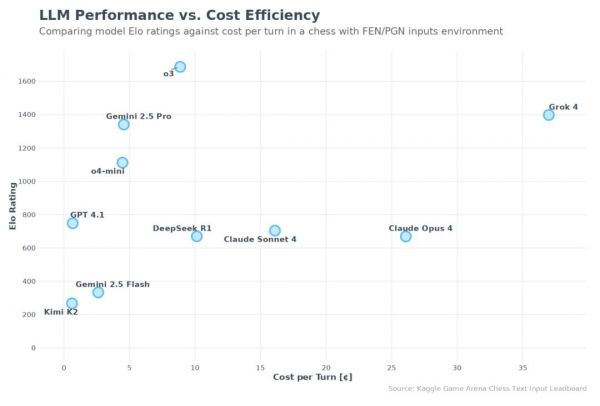
自然,这个排行榜也有一些限制和缺陷:
(1)仅限于国际象棋:没有任何单一游戏可以捕捉智能的全部范围。Kaggle将努力通过随着时间的推移引入更多游戏来缓解这一问题。
(2)超时限制:施加严格的每步棋时间限制可能会惩罚那些需要更长时间才能得出结论、进行更深入思考的模型,从而偏向于那些速度更快但可能更肤浅的策略。
(3)抽样随机性:使用了模型提供商设置的默认抽样参数。这些参数可能具有非确定性。
全新测试基准,还能查看游戏回放
你可以在Kaggle的YouTube 播放列表中观看带解说的表演赛,但排行榜上提供了更多的对局回放。只需点击模型旁边的回放图标,选择想要观看的对局即可。
此外,这次还发布了一个包含可移植棋谱(PGN)和模型公开推理过程的数据集:国际象棋文本输入基准测试「Chess Text Gameplay」。
数据集链接:https://www.kaggle.com/datasets/kaggle/chess-text-gameplay
国际象棋文本输入基准测试旨在评估和比较当今通用语言模型的战略推理能力。
这是Kaggle公开基准测试平台Game Arena的首个项目,该平台让AI模型在复杂的战略游戏中竞技,将严谨的科学方法与观赏性的竞赛体验相结合。
为什么这很重要?Kaggle介绍了三大理由:
超越数据污染问题: 静态测试无法区分模型的真实推理能力和记忆答案的能力。而在国际象棋文本输入测试中,每一步决策都源自模型的内部逻辑,确保评估的是真实的思考过程。
高压环境下的表现: 模型必须随机应变、从错误中恢复,并抓住不断变化的机会,如同人类国际象棋大师一样应对复杂局面。
通用人工智能(AGI)的洞察: 在此领域取得成功,意味着模型在多步骤战略问题解决方面达到了重要的里程碑,为通用人工智能的发展提供了有价值的参考。
超越数据污染,这才是AI的「高考」!
每一步棋,都考验着大模型真·战略推理、规划和应变能力。
他们也指出了该数据集的一些局限性,包括:
推理:推理输出是模型思考过程的生成性摘要。它不是内部计算的字面追踪,因为模型通常会隐藏其内部思考过程。
测试框架:模型的性能与用于此基准测试的特定测试框架(更多细节)内在相关。
时间快照:该数据集代表了这些特定模型版本在收集时点的性能。
数据结构 「PGNs_with_reasoning」(包含推理的PGN)数据集包含表示大型语言模型所下国际象棋游戏的便携式游戏记谱法(PGN)文件。每个PGN文件由国际象棋记谱和大型语言模型在每一
Kaggle计划定期将新模型加入国际象棋文本排行榜及其他Game Arena排行榜,以跟踪AI模型在战略规划、推理和其他认知能力方面的进步。
未来,Game Arena将推出更多游戏的排行榜,为AI模型的能力评估提供更全面的基准。
今天的国际象棋文本排行榜只是第一步。
参考资料:
https://x.com/kaggle/status/1958546786081030206
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
相关推荐
OpenAI发布o3系列模型“剑指”AGI 北大毕业生打造
OpenAI o3是AGI吗?
不听人类指挥,OpenAI模型拒绝关闭
Anthropic CEO最新预言:90%程序员的饭碗年内不保!
OpenAI o3被曝智商高达157,比肩爱因斯坦,但却没法证明比人类聪明
AI大牛解析o3技术路线,大模型下一步技术路线已现端倪?
OpenAI最强推理模型来了!o3和o4-mini解锁“图像思考”新技能
周鸿祎谈o3大模型:关于AGI 的定义,可能得改改了
不听指挥?OpenAI模型被曝拒绝执行人类指令
刚刚,GPT-5正式发布,奥特曼:这是全球最好的模型
网址: 刚刚,大模型棋王诞生,40轮血战,OpenAI o3豪夺第一,人类大师地位不保? http://m.xishuta.com/newsview140857.html