Kimi K2不仅抢了开源第一,还抢了自家论文署名:我“夸”我自己
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《Kimi K2 不仅抢了开源第一,还抢了自家论文署名:我「夸」我自己》
上周,月之暗面发布了全新版本的大模型,Kimi K2。
这是目前世界上第一个参数量达到万亿级别的开源模型,发布后迅速引爆了圈内讨论。
它不仅在各种评估基准上表现亮眼,也收获了国内外开发者社区的普遍好评。
在LMSYS的开源模型排行榜(LMArena)上,Kimi K2直接跃升至第一名。
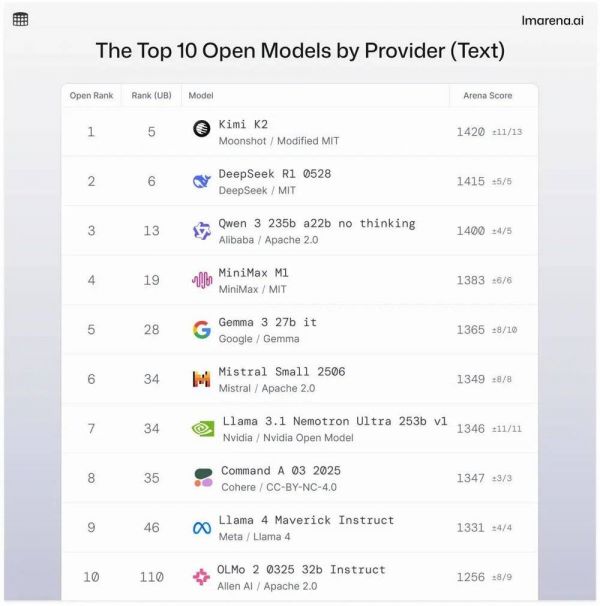
第一列是开源模型内的排名,前四都是国产开源模型,Kimi K2排在第一名;第二列是所有(开源和闭源)模型中的排名。图片来源:https://lmarena.ai/leaderboard/text
但也有不少人质疑Kimi K2是在「抄袭」DeepSeek。
Kimi团队则大方回应:确实是在DeepSeek V3的基础上做了改进。
甚至有网友直接对比了两者的架构,指出了细节差异:
就在大家还在讨论这些差异、参数规模、以及模型路线时,Kimi今天又放出了一份干货:Kimi K2的技术报告正式发布。
我第一时间打开来看,快速扫了一遍,关键词大概是:万亿参数的混合专家模型、让训练更稳定的MuonClip优化器、不断被强调的Agentic智能,还有自我批评式的通用强化学习……
直到我翻到附录,发现一张有点意思的作者列表,除了看到月之暗面创始人杨植麟的名字,竟然!
Kimi K2技术报告作者页面
Kimi K2……自己也是作者之一?
我突然有点恍惚,把你「造」出来,你还参与了如何「造出你」的论文撰写?
那我还研究什么,既然它都上作者署名了,直接问他就好了!
我就把这份技术报告交给Kimi K2来分析一下,看看它能不能讲明白,Kimi K2到底做了什么。
于是,这篇文章就变成了:我,把技术报告丢给了Kimi K2,让它「揭秘」它自己。
Kimi K2:为「智能体时代」奠基的万亿级开源大模型
——《Kimi K2 Technical Report》深度解读
从「会聊天」到「能干活」:为什么需要新一代大模型
过去两年,大模型的竞赛焦点集中在「谁能把考试题刷得更高」,但真实世界的需求正在迅速转向「谁能像人一样干活」。
从自动修复代码漏洞、跨工具协同办公,到自主完成科研实验,业界把这种「感知-规划-执行-反思」的闭环能力称为Agentic Intelligence(智能体智能)。
Kimi K2正是这种范式切换下的第一个系统性成果:它不仅要会做题,更要能在复杂、动态、多工具环境中像「实习生」一样自我进化。
速看省流版:
技术层面:MuonClip优化器、稀疏MoE架构、改写数据策略,共同给出了「高质量数据稀缺」时代的超大规模训练新范式;
数据层面:合成+真实混合环境的十万个工具轨迹为社区提供了可复现、可扩展的智能体数据生产线;
开源层面:1 T参数的base+instruct权重全部放出,相当于把一辆F1赛车开源给了所有工程师。
模型一览:万亿总参数、320亿激活的「稀疏巨人」
规模:总参数1.04 T,激活参数32 B,MoE(混合专家)架构,稀疏度48(每token只激活8/384位专家);DeepSeek V3的参数总量是6710亿,其中激活参数量为370亿。
训练数据:15.5 T token,涵盖网页、代码、数学、知识四大领域,全部经过质量清洗与「改写法(数据增强技术,增加数据多样性)」扩增。
训练稳定:首次在大规模模型训练过程中,损失函数没有发生任何大的波动或异常,归功于新优化器MuonClip。
上下文窗口:128K token,满足长文档、多轮工具调用的需求。
MuonClip:大规模模型超高效训练方法
Muon优化器以训练效率高著称,但在参数规模较大时,可能会出现注意力权重爆炸的问题,即logits值过大,导致训练不稳定。
作者提出QK-Clip机制融合到Muon优化器中。QK-Clip能够在logit过大时,自动进行调节;同时,不会改变网络结构,对模型干预极小,但作用极大。
注意力权重爆炸问题大多出现在超大规模的大模型训练中,这也是此次Kimi K2万亿参数能够成功训练的重要突破之一。
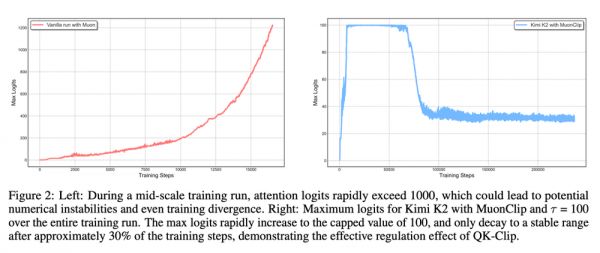
没有使用QK-Clip的Muon优化器在训练时,会无法控制logits数值,从而导致大模型训练的不稳定;而Kimi K2的MuonClip在整个训练过程中都可以很好的控制logits。
实验显示,MuonClip在中等规模,90亿激活参数时,就可抑制logits超过1000,在K2全量训练中全程没有不稳定和优化问题出现,始终确保了训练的稳定性。
文本数据:合成数据+真实数据双buff
高质量数据越来越稀缺,而在训练中简单多轮重复读取容易导致模型的过拟合。Kimi K2提出两套改写策略:
知识文本:用LLM以不同风格、视角重写维基百科,同时保持语义一致性自动校验,例如把「光合作用」改写成「植物如何制造养分的侦探故事」;
数学文本:按「学习笔记」风格重写并多语种翻译,把奥数竞赛题都改写成「费曼式讲解」。
数据改写流程,将输入拆分为保留上下文的小块,按顺序重写,然后拼接成完整的重写段落。
Kimi K2也在多个实验进行了测试,结果显示一次改写+单轮训练的准确率(28.94%)优于原始文本反复读取十轮(23.76%)。
智能体数据:2万工具、10万轨迹
要让模型会调用工具,最难的是「可扩展的真实环境」。作者搭建了混合管线:
工具库:3000+真实MCP工具,2万+LLM合成工具,覆盖金融、城市物联网、软件开发等20余领域;
「任务-智能体-评估」三元组自动生成智能体训练样本:每条生成的轨迹(即模型的输入、输出、决策过程、以及所采取的每一步行动)由LLM Judge打分,通过率<10%时,采用拒绝采样方法;确保只选择符合要求的样本进行进一步的训练或评估;
真实智能体任务数据补充:例如代码类任务直接扔给开源的容器编排平台,执行任务并测试,保证反馈真实。
工具库使用的数据合成流程,工具来自真实世界的工具和LLMs;智能和任务从工具库中生成。
最终产出超过10万的高质量轨迹,用于监督微调与强化学习。
强化学习框架:可验证奖励+自我批评
可验证奖励的强化学习:对于数学、代码、逻辑题等任务,直接跑单元测试或数值验证,客观评估模型表现;
自我批评奖励:而对于非客观任务(比如写诗等),模型用30多条标准(清晰、客观、对话流畅、安全等指标)给Kimi K2的回答打分,实现无参考答案的对齐;
预算控制:拒绝「废话连篇」,强制用最少token解决问题(节省推理费)。
成绩汇报:开源第一,逼近闭源
所有对比均为「非思考」模式,不考虑测试时计算资源的差异。
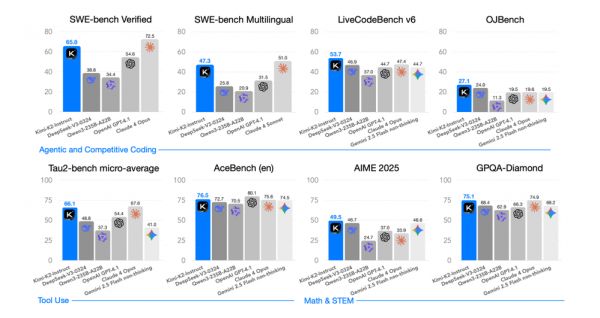
Kimi K2在代码、数学、工具使用和长文本四项关键能力上均取得或逼近当前开源模型的最优成绩,并在多项任务上超越闭源标杆。
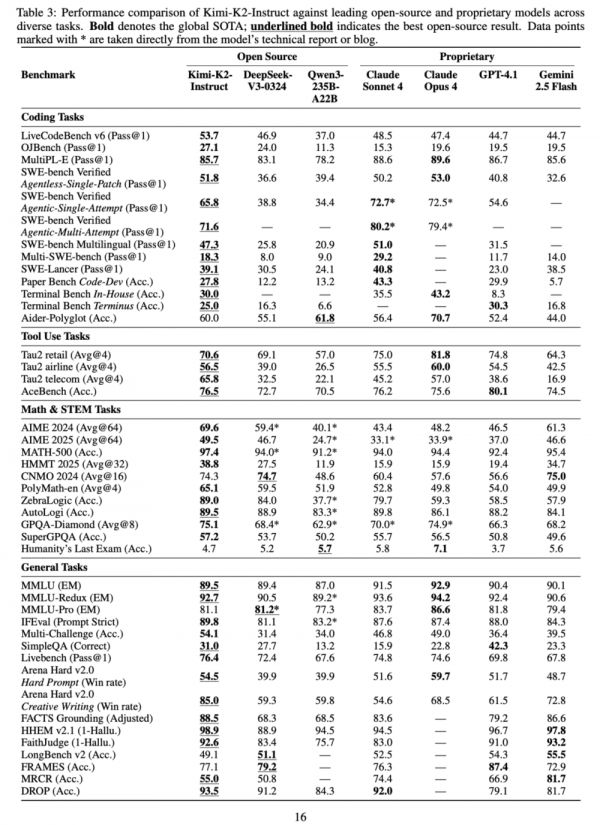
详细结果图,从上至下依次是代码、工具、理工科以及通用任务。
局限与展望
多步复杂推理场景下输出过长,可能被截断;
在多轮任务中,如果触发了错误工具,或者工具调用失败,会拉低表现;
Kimi K2,是「Agentic-aware」模型(接受过agent任务训练),但还不是一个「完整Agent框架」系统。在长流程开发任务中的一次成功率,Kimi K2仍然低于那些完整Agent框架驱动下的系统。
Kimi K2后续将围绕推理效率、工具自我评估、长过程推理规划继续迭代。
Kimi K2的意义不止于又刷新了几个benchmark。可以预料,随着开源社区在此基础上继续改进,2025下半年将出现一批「比K2更会干活」的垂直智能体,真正把大模型从「聊天框」带进「生产线」。
WAIC 2025 APPSO在现场,欢迎加入社群一起畅聊AI产品,获取#AI有用功,解锁更多AI新知
相关推荐
Kimi K2不仅抢了开源第一,还抢了自家论文署名:我“夸”我自己
DeepSeek终于丢了开源第一王座,但继任者依然来自中国
我一年发了180篇论文,我不是“人”
B站抢了微信的活儿
无耻,直接上手抢了!
一群人把苹果店砸了,然后把iPhone都抢了 !
今年你抢了多少红包......封面?
联想抢了高通首发,小米12怎么办?
谁抢了我的火车票?
超越DeepSeek,中国又一款大模型登顶!
网址: Kimi K2不仅抢了开源第一,还抢了自家论文署名:我“夸”我自己 http://m.xishuta.com/newsview139221.html