你的验证码又升级了:虐完人类不过瘾,现在要收拾AI 了
本文来自微信公众号:APPSO (ID:appsolution),作者:发现明日产品的,原文标题:《你的验证码又升级了:虐完人类不过瘾,现在要收拾 AI 了》
没人喜欢被白嫖,整个互联网都一样。
就在昨天,互联网基础设施巨头Cloudflare宣布了一项新举措:默认拦截所有未经许可的AI网络爬虫(crawler)对网站内容的抓取。换言之,AI公司想要抓取网页数据训练模型,必须先征得网站所有者的同意,否则将被挡在门外。
这一系列举措无疑在业界引起震动——对于需要全网搜刮数据的大模型开发厂商来说,免费任吃、数据不要钱的好日子,或许没几天能过了。
从7月初开始,每一个新接入Cloudflare的站点都会被询问是否允许AI爬虫访问,其默认设置为拒绝,这等于给网站赋予了一键封禁AI抓取的权力。同时,Cloudflare还推出了「按次付费爬取」的新模式,网站出版商可以选择向AI爬虫收取抓取内容的费用。
版权的战争打了这么久,凭什么这家公司一出声,就变得大件事了?
因为这是Cloudfare,这是真正的互联网「保安」。
验证码变形记:Cloudflare如何拦住AI爬虫
要理解Cloudflare此举的意义,先得弄清它究竟在做什么。
传统的验证码(CAPTCHA)相信大家都不陌生:比如让用户选出图片中所有的红绿灯,或输入扭曲的字符,以此区分「你是人还是机器人」。
一度,验证码演化到了一种复杂死人的程度,别说机器人,正常人也要花上好几分钟才能解完:
2022年,Cloudflare推出了Turnstile新一代的「无感验证」方案。
当你打开某些网站时,可能会看到一句「正在验证浏览器,请稍候」,几秒后自动放行——这背后就是Turnstile在检查你的浏览器环境、鼠标移动轨迹、页面操作等数据,以确定访问者是活生生的人类,而非脚本程序。
Cloudflare强调,这种验证对真人几乎是隐形的:没有烦人的拼图对齐和「找不同」大战,甚至连多余的点击都不需要。2023年时他们还宣布要彻底淘汰视觉谜题式验证码,承诺「不再以任何理由给任何人看乱七八糟的拼图」。
的确,新一代的Turnstile验证既保障了安全,又让用户几乎无感知通过,可谓一个隐形的守门人,在真人用户和自动程序之间筑起一道分界线。
以往,验证码主要用来防范批量注册、刷票、薅优惠券这种脚本行为。但在AI大模型时代,验证码扮演的角色更加吃重,因为无处不在的AI爬虫正试图把整个互联网当作自助餐。
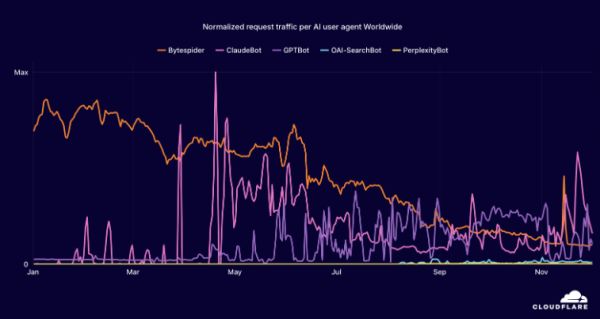
各个AI爬虫爬取的数据量.图片来自:Cloudfare
Cloudflare的验证系统,因此针对性地进行了升级:它结合行为分析、浏览器指纹和机器学习模型,来识别访问者是正常用户、良性爬虫,还是伪装的AI抓取工具。
例如,真人浏览网页往往有自然的滚动和点击节奏,而批量爬虫可能在毫秒间疯狂翻页;又比如正常浏览器会暴露一些标准特征,而某些爬虫为了隐藏身份可能伪造UA或关闭脚本——这些细节都难逃Cloudflare的检测算法。
一旦判定某次访问属于未经授权的自动抓取,Cloudflare要么让其陷入无限验证环节,要么干脆直接阻断。
技术拦不住,法庭再相见
Cloudfare为什么这个时候出来选边站?
作为全球领先的CDN和网络安全服务商,Cloudflare在2023年的报告中估计,它每天要应对万亿级别的网络请求,直接处理了全世界约16%的互联网流量,占据着全球约五分之一的网络流量。
2024年通过IPv4互联网流向Cloudflare的流量聚合情况
当这样一个守门员开始对AI说「不」,其影响可想而知——而眼下,AI厂商在版权战争中占取上风,接二连三地赢下诉讼。
Anthropic在使用了数百万本书籍训练模型后,被告上法庭。最近出炉的裁决认为,他们的行为符合「合理使用」的原则——这项法律原则允许在某些情况下,无需获得所有者许可即可免费使用受版权保护的内容。
Meta也打了胜仗。在应对作家们的集体诉讼中,加州联邦法庭裁定Meta胜诉。不过,这个胜利来得比较侥幸,能胜主要是因为原告的「诉讼点」提得不够好,在法律层面不够有力,因此法官也表示「这项裁决并不代表Meta使用受版权保护的材料训练其语言模型是合法的。」
找个好律师真是很重要啊。
在AI模型对网页内容的胃口与日俱增的背景下,验证码系统俨然成为抵御「大数据采集狂魔」的一道防线。如果没有这层把关,AI爬虫们恣意爬网的行为不仅可能把网站服务器搞得不堪重负(它们的高频抓取甚至被比作DDoS攻击),内容创作者的成果,更加是在不知情间就被拿去「喂AI」。
如今有了Cloudflare的拦截机制,网站主至少有了一套可以用来自我保护的武器。
互联网格局如何改变
对于普通网民来说,这场关于AI爬虫的风波听上去很「大」,但日常上网时的体验并不会有明显变化。
Cloudflare的Turnstile验证本就以「隐身」著称,不会像旧式验证码那样频繁跳出来考你识别交通灯和楼梯。因此,即便现在把AI爬虫视作众矢之的,也不代表我们上网时要遭更多复杂考验——Cloudflare不会开倒车。
倒是那些试图冒充人类的AI爬虫们,恐怕要开始头疼如何通过这道检验了——换句话说,验证码系统的功能重心已经悄然转变。
以前,网站加验证码主要是为把关「脚本」和恶意机器人,而现在Cloudflare明显是在有意识别并阻挡特定的AI爬虫。
有数据显示,Cloudflare的自动化识别技术可以准确地区分真人流量和AI爬虫流量,这表明其验证码背后的目标已从一般性防护升级为专门针对AI数据抓取。可以说,原本验证人机的「小考」,如今背后多了一层「筛查AI」的使命。
在我们看来页面秒开、一片风平浪静时,Cloudflare早已在背景里盘查过:「这是正常人类,通过」;「那是GPT的爬虫,拦下来」。这种场景,如今每一分每一秒都在互联网的底层跑道上真实上演。
这样高调封杀未授权AI爬虫,表面理由是为内容创作者讨回公道——毕竟AI公司过去一直在大吃特吃「霸王餐」,侵占内容却不给创作者流量和报酬,即便后者闹到法庭上,也不见得能求得公道。
不过,与此同时,Cloudflare顺势推出了让AI公司付费爬取内容的功能和平台,实行按次付费爬取(Pay Per Crawl)的方式。这项新功能允许特定出版商和创作者向AI公司收取访问其内容的费用。参与者可以为单个爬虫程序设定价格,从而完全控制其作品如何以及是否用于AI模型训练。
这意味着Cloudflare正在将自己的安全防护网,升级为AI时代的「收费关卡」。以前AI爬虫横行时,内容网站几乎无从谈判,AI公司想抓就抓,顶多背负一些道德谴责。而现在,Cloudflare替网站堵上了大门,让AI公司不得不停下来说:能不能让我进来抓点数据?价格好商量。
这种转变无疑改变了网络内容的利益分配格局,为出版社、媒体、创作者等网站主提供了筹码。而Cloudflare则居中扮演了至关重要的「基础设施」角色。
正如Cloudflare CEO所说,他们希望建立的是多方共赢的新模式,帮助创作者决定是否允许所有AI爬虫、允许特定的爬虫或设置自己的访问费用,将以前未货币化的内容使用转变为新的收入来源。
当然,在这个模式里,Cloudflare自己也扮演了角色:一边替内容提供方把门,一边替AI公司带路,中间这一来一回,就可以收点服务费手续费之类了。
可以预见,随着这一机制推广开来,AI公司要想抓取海量网络内容训练模型,恐怕得先准备好「买路钱」。毕竟,手握着全球五分之一网络流量「安检闸口」,Cloudflare无疑已经为这笔潜在的生意打好了基础。
眼下可以确定的是,Cloudflare已经把「我不是机器人」升级成了AI爬虫面前的一道高门槛。这道门槛背后,既有守护互联网内容生态的用心,也不乏精明的商业算计。
下一次你轻松通过自动验证时,栅栏抬起的另一侧,某个AI爬虫可能正在被拦下来——想过,先去交个过路钱吧。
相关推荐
AI:我又又又打败了人类冠军!小学生:叫爸爸!
验证码越来越奇葩,我都无法证明自己是人类了
iOS 16的这项新功能,让你不用再与验证码斗智斗勇
Nature封面:人类又输给了AI,这次是玩《GT赛车》游戏
产品观察 | 和 AI 打王者荣耀,第三局就被虐哭了
玩桥牌,8位人类世界冠军,都输给了AI
人类开始模仿AI了
专访齐俊元:被阿里收购半年后,我们有一场「过瘾的升级」
谷歌想让你少看“验证码”,为什么有人公开反对?
为什么AI各种完爆人类,但仍听不懂你在说什么?
网址: 你的验证码又升级了:虐完人类不过瘾,现在要收拾AI 了 http://m.xishuta.com/newsview138399.html
