音画同步,AI视频也能有完美“原声音”,可灵AI刚上线的
本文来自微信公众号:机器之心 (ID:almosthuman2014),编辑:泽南,作者:关注AI的,原文标题:《音画同步,AI视频也能有完美「原声音」,可灵AI刚上线的!》
AI生成的「最后一道关卡」已经突破?
因为生成式AI,火遍全球的Labubu有了超萌专属BGM:
视频来自可灵AI创意圈用户。
复杂的自然环境也可以获得相应的背景音。
视频来自X。
现在还可以生成各种ASMR,比如切开炸弹的外壳:
视频来自可灵AI创意圈用户。
最近,人们都在谈论一种给AI生成视频加音效的大模型。
它主打一个「全能」:不论输入的是文本还是静音的视频,它都会给你生成配套的音效或音乐,节奏踩点准确,细节到位合理。更有趣的是,它还能配合视频场景里面的环境,呈现出立体声。
相比之前的一些音效生成AI,格局一下打开。
这个新突破来自可灵AI,他们提出的多模态视频生音效模型名叫Kling-Foley,能够通过大模型自动生成与视频内容同步的高质量立体声音频。
输入的是视频和文字,输出的是音效和BGM。
简单来说,Kling-Foley支持基于视频内容与可选文本提示自动生成与视频画面语义相关、时间同步的高质量立体声音频,涵盖音效、背景音乐等多种类型声音内容。它支持生成任意时长的音频内容,还具备立体声渲染的能力,支持空间定向的声源建模和渲染。
不少海外网友已经用上了,并在社交平台上大加称赞。
可灵AI已经发布了Kling-Foley的技术报告,有关它背后的技术我们可以一探究竟。
论文:https://www.arxiv.org/pdf/2506.19774
项目主页:https://klingfoley.github.io/Kling-Foley/
GitHub链接:https://github.com/klingfoley/Kling-Foley
Benchmark:https://huggingface.co/datasets/klingfoley/Kling-Audio-Eval
看视频就能「脑补」背景音
可灵AI用了什么方法?
音视频的同步输出,可谓是生成式AI的下一个关键节点。
生成式AI正在全球范围内持续爆发,仅视频生成领域里,技术可以说是日新月异。就说可灵AI自己,最近更新的2.1系列模型,生成的人物运动和细节让人叹为观止。
不过AI生成视频已经出现了两年,大多数生成的内容还是缺乏同步音效的,如果人工加配音、BGM的话,效率会被直线拉低,毕竟大多数人无法像专业配音师一样掌握复杂的工具。
如何能让大模型更好地给视频配音呢?
这方面的研究其实早已出现,但传统的AI文本生成音频(Text-to-Audio,T2A)方法在实际应用的过程中面临着不少挑战,比如它仅限于文本输入,难以精确地「理解」视频,经常出现生成的音效和视频内容不同步的情况。
相比之下,视频生成音频(Video-to-Audio,V2A)方法可以更加直接地结合视频和文本,提升音效生成的相关性和准确度。这就要求训练AI模型的数据集既包括视频,也包括配套标记好的音频和文本,从数据规模和多模态标注质量上来看都是一个艰巨的任务。
在Kling-Foley模型身上,我们能看到一系列创新。它的整体结构如下:
具体来说,Kling-Foley是一个多模态控制的流匹配模型。在音频生成的流程中,文本、视频和时间提取的视频帧作为条件输入;随后这些多模态特征会通过多模态联合条件模块进行融合,并输入到MMDit模块进行处理;该模块预测VAE潜在特征,随后由预训练的梅尔解码器将其重建为单声道梅尔声谱图;然后,渲染为立体声梅尔声谱图;最后,通过声码器生成输出波形。
为了解决视频、音频和文本三种模态间的交互建模问题,Kling-Foley架构中很大程度上借鉴了Stable Diffusion 3的MM-DiT块设计,实现了在文本、视频和音频任意两种模态组合下的灵活输入。
而让AI生成的声音在时间点上与视频对齐是重中之重。为此,模型框架中还引入了视觉语义表示模块和音视频同步模块,能在帧级别上对齐视频条件与音频潜层元素,从而提升视频语义对齐与音视频同步的效果。这些模块与文本条件共同作用,以精准控制生成与视频内容相匹配的拟音。为了支持可变长度的视音频生成并增强时间控制,Kling-Foley还引入了离散时长嵌入作为全局条件机制的一部分。
另外,在音频Latent表征层面,Kling-Foley也应用了一种通用潜层音频编解码器(universal latent audio codec),能够在音效、语音、歌声和音乐等多样化场景下实现高质量建模。
潜在音频编解码器的主体是一个Mel-VAE,它联合训练了一个Mel编码器、一个Mel解码器和一个鉴别器。VAE结构使模型能够学习到连续且完整的潜在空间分布,从而显著增强了音频表征能力。
实验结果表明,采用流匹配目标(stream matching objective)进行训练的Kling-Foley,在音频质量、语义对齐和音视频同步方面,于现有公开模型中取得了全新的SOTA(业内最佳)性能。
从无到有,打造多模态数据集
可灵打造Kling-Foley做的另一件重要的事就是从无到有构建数据集。其自建的多模态数据集样本总数高达1亿+,每个样本都包含一个原始视频片段、对应的单声道音频片段,以及关于音频的结构化文本描述。它们来源于真实的在线视频内容,且三种模态紧密对齐。
在如此体量的数据处理过程中,可灵使用了一套自建的多模态大模型自动化数据处理系统,辅以严格的人工标注流程。
其中,音频和视频数据经过质量筛选,以获得高质量的单事件音频和视频片段。随后,系统通过数据增强生成多事件音频样本,同时利用上更多短数据,并使用多模态大模型为音频和视频生成详尽描述。最后,使用大模型将各种描述信息结合起来,生成最终的结构化描述。
把训练集中高层级声音类别的分布可视化一下,可以看到它覆盖了真实世界中大量的声学场景,包括自然环境、人类活动、动物声音、机械操作、交通工具等,这就为学习多样的生成模式,提升合成音频的真实感和可控性提供了扎实的基础。
可灵还构建了一个名为Kling-Audio-Eval基准数据集并将其开源。其中同时包含视频、视频描述、音频、音频描述和声音事件多级标签。它包含20935个精细标注的样本,覆盖了交通声、人声、动物声等九大类主要的声音事件场景。它是业界首个包含音视频双模态描述以及音频标签的音效生成基准,其涵盖不同维度的多项评估指标,能支持对模型性能进行全面和多角度的评估。
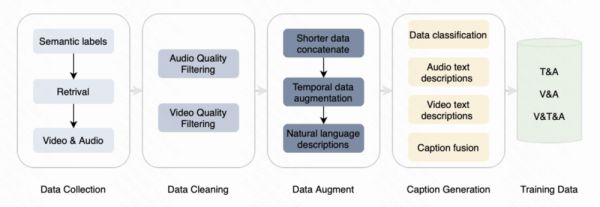
最后,可灵在一些公开基准上对Kling-Foley与一些业界主流方法进行了对比,可见其在语义对齐、时间对齐和音质方面水平领先。
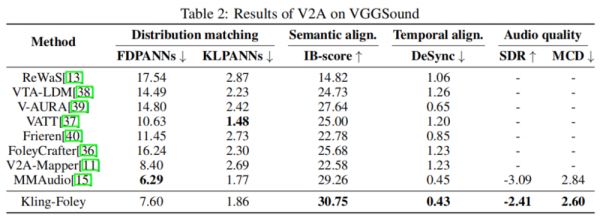
如果比较音效、音乐、语音和歌唱四种场景的编解码能力,Kling-Foley也在大部分指标上拿到了最优成绩。
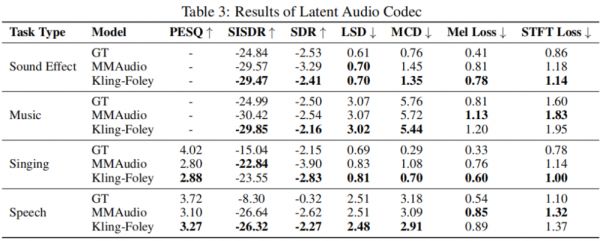
看起来,可灵AI提出的这个新技术不仅生成的音频在频谱上准确无误,而且在感知上也更接近真实的原始音效。
可灵AI的音效生成能力,逐渐实用化
今年3月,可灵AI平台上线了「文生音效」能力,其中新增了「音效生成」入口,支持用户通过输入文本生成相应音效,并可以基于可灵生成的视频内容进行理解,自动生成匹配的音效内容。
到了这个月初,可灵在推出2.1版视频生成模型时,添加了「视频音效」的开关,大家在生成视频的同时,系统也会自动生成与视频匹配的音效,增强了整体视听体验。
从现在开始,「视频音效」功能将全面扩展至可灵平台所有版本的视频模型,覆盖了文生视频、图生视频、多图参考生成视频、视频续写、多模态编辑,基本做到了有视频,就能配音。
与此同时,「音效生成」也进行了一番升级,现在用户可以直接上传本地视频或选择可灵生成的视频,一键生成与视频内容语义贴合、时间同步的音效内容。
可灵AI的音效生成界面。
通过可灵的新模型,平台能够自动对视频语义与音频片段实现帧级对齐,「所见即所听」,大幅降低了人们的的音频后期制作成本。AI生成的音效还是立体声的,能够适配动作、自然环境等多种场景,给足了沉浸感。
当然最重要的是,足够方便简单。
看起来,AI视频生成的最后一个坎,已经被可灵跨过去了。
相关推荐
音画同步,AI视频也能有完美“原声音”,可灵AI刚上线的
真碾压Sora了,谷歌Veo 3首次实现音画同步
独家|快手上线“可灵AI”APP,抖音“即梦AI”最大对手来了?
有点料·上手|可灵 AI App 试用:另请高明
快手押注可灵AI:一场由组织改写的技术跃迁
AI 视频新王全球爆火,威尔·斯密斯终于可以好好吃面(附大量实测演示)
晚点独家丨快手提高可灵 AI 的优先级,组建一级部门
快手可灵大模型再进化,发布全新图生视频及视频续写功能
快手可灵AI宣布全面开放内测,模型效果再升级
不得志的职场人,深夜烧钱做AI视频
网址: 音画同步,AI视频也能有完美“原声音”,可灵AI刚上线的 http://m.xishuta.com/newsview138102.html