特想聊聊快手这次的变化
前几日刷朋友圈,看到消息说快手已经把 AI 大模型驱动的推荐系统全量上线到产品中。而这套基于大模型的生成式推荐系统,是行业里第一个工业级的推荐解决方案。放眼全球,目前还没有其他大公司能做到这个程度。
快手的技术这几年确实有点东西。比如他们的视频生成模型可灵,现在也是全球顶级水准。
以前我更多把快手当成一家短视频公司,现在回头看,他们在底层技术上的积累,其实比我想象中要深得多。这也让我越来越好奇这家公司的运作方式。我总觉得,公司的创新背后,其实是它气质和风格的延伸。
说回到推荐系统。其实我们对推荐系统并不陌生,它当属移动互联网时代最大的技术创新之一。包括快手、抖音、拼多多、美团、小红书等耳熟能详的国民级产品,他们的模式均建立在推荐系统之上。推荐系统的本质是完成人和信息的匹配,目前来看,大致有两种信息分发方式:
一类是基于用户的协同过滤,推荐系统根据用户的自然属性(年龄、性别、学历等信息)和浏览兴趣来计算用户相似度,进而给相似用户推荐内容。另一类是基于内容的协同过滤。推荐系统提取内容的特征,然后计算不同内容之间的相似性之后,给用户推荐与过去喜欢内容相似的内容。
当然还有一类是给用户直接推荐系统的高热内容,这部分没有难度,不过多展开。
无论是基于用户还是内容的协同过滤,大致都是一套“多阶段流水线”架构。平台先用一个召回模型,从海量内容池里筛出一批可能相关的视频。然后,粗排和精排模型再逐步“打分”,把更可能吸引用户的内容一层层挑出来。最后,重排阶段会针对内容多样性、新内容扶持等策略再做一轮调整。
这种结构看上去很科学,但其实这些年也积累了不少问题。
因为每一层模型只管自己那摊事,很难从整体出发考虑用户的真实兴趣。比如召回阶段可能直接把用户真正喜欢的内容筛掉,后面的精排模型再智能也救不回来。
更麻烦的是,各层的目标经常互相掣肘:一边要拉高点击率,一边还要兼顾冷门和多样性,这种拉扯长期下来,系统的一致性和效率会持续恶化,最终也会影响到推荐的准确度。
更深层的问题在于,算力浪费。多阶段流水线虽然让流程分工明确,但每一层模型通常各自独立运行,分开消耗硬件资源,整体的 GPU 利用率非常低。
以快手为例,即使是推荐系统里最复杂、算力消耗最大的精排模型(SIM),在旗舰级 GPU 上训练和推理的算力利用率也只有 4.6% 和 11.2%。而大语言模型在顶级芯片 H100 上的算力利用率普遍能达到 40% 以上。
在大模型技术没有正式爆发之前,上面提到的两个问题,都没有明确的解法。2022 年年底,ChatGPT 在小圈子内走红之后,我一个在大厂专做推荐系统的朋友告诉我说,他可能隐约看到了新一代推荐系统的影子。后来,大模型彻底爆发后,朋友就离职自己创业去了,没再把精力投入到推荐系统方向。
这两年,我出去和行业的人交流,也会问到大家为什么没把大模型的技术用到推荐系统中。
几乎所有人的第一反应都是,端到端大模型在推荐系统里,真的太难了。不是没想过用,但一上业务就会发现,模型庞大,特征复杂,整个链路极其脆弱,线上环境很容易出幺蛾子。训练、推理、数据流全部得重构,哪怕有工程团队敢试水,最后也多半因为效率和成本问题被劝退。
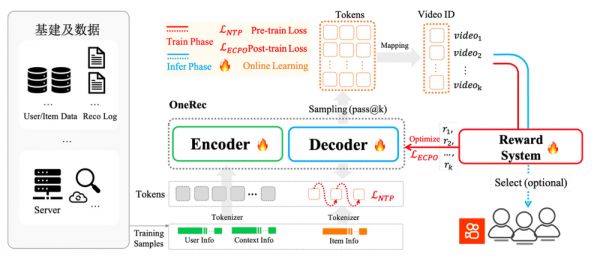
所以,这次看到快手真的把这样一套端到端大模型的推荐系统 OneRec 全量上线,说实话,还是非常激动。
OneRec 本质上是把推荐问题从多阶段、分层筛选,彻底切换成了端到端的大模型生成。过去,推荐系统像装配线,一层层地筛选内容;现在,OneRec 通过大模型,直接生成出一串用户最可能感兴趣的视频内容列表。这是一次范式的变化。
具体来看,OneRec 主要做了三件事:
1、用户建模(Encoder):系统会把用户长期的全部行为,比如观看、点赞、评论等数据,进行深度编码,形成一组多维度的兴趣向量。
2、推荐生成(Decoder):基于兴趣向量,由大模型的 MoE 解码器一步步生成推荐内容,实现内容匹配和排序。
3、奖励机制:引入强化学习(RL),对用户反馈做动态优化,确保推荐结果能够不断贴合用户真实兴趣。
接下来,我分别解释下这几个环节中的卡点。当然,只是我的理解。
推荐系统要想真正做到个性化,最根本的前提还是对内容本身有足够深入的理解。尤其是短视频这种极度丰富、多样的内容形式,如果系统只能看懂表层标签,实际上很难捕捉到用户的真实兴趣点。
正因为如此,OneRec 在内容理解上做了一步重要尝试,就是引入多模态语义分词器。它不再只看视频的标签、标题或者简单的视觉特征,而是把每个视频拆解成更细致的信息片段——比如画面内容、文字、配音、音乐,甚至用户的互动。
系统会把这些不同的细节单独分离出来,像拼图一样组合成对内容的整体理解,让模型看到更多元的内容层面。
举个例子:比如一条美食短视频,分词器不仅会捕捉画面里的食材、烹饪动作、厨房环境,还能分析配音里的生活化语气,用户评论和弹幕,比如“太治愈了”或者“学会了这道菜”,都会变成内容理解的一部分。音轨里如果有轻快的 BGM、环境音或者笑声,系统同样会识别出来,把这些都融合到对内容的整体表达里。
这种多模态分词的方式,相比以往只看标签的做法,能把内容拆得更细致、理解得更立体。
以前的推荐系统像是用粗网捕鱼,只能抓到大鱼,很多微妙的兴趣点都漏掉了。现在有了分词器,模型能更精准地捕捉到用户可能喜欢的那些内容细节,理解能力也更接近人类实际的内容感知。
理解内容只是第一步,系统还需要理解每个用户的兴趣变化,这样推荐才能真正精准。
传统推荐系统往往高度依赖用户最近的行为,比如用户这几天刷了什么、点了什么,模型就会重点推类似内容。这样虽然短期效果还不错,但一旦用户的兴趣发生变化,或者本身兴趣比较多元,系统很容易误判真实偏好。
比如用户其实喜欢历史、健身、美食,但最近几天只是偶尔关注了几条旅游短视频,传统推荐很可能就疯狂推荐旅行内容,久而久之会让用户觉得内容越来越单调,真正的兴趣被忽略。
OneRec 在这方面的创新,是用大模型把用户的静态特征、短期行为和长期行为全都串联起来,统一建模。它不再只看最近的动作,而是把长期的浏览、互动、偏好变成一条完整的“兴趣序列”。不管是阶段性兴趣变化,还是本身爱好多样,模型都能捕捉到不同时间段的兴趣转折,及时调整推荐策略。
比如,某个用户半年前很喜欢科幻片,最近转向美食、生活内容,系统会自动平衡这些变化,既不会死盯着最近一两天的点击,也不会完全忽略历史上的偏好。
和传统那种主要靠人工设定特征和预定义兴趣分类的做法不同,OneRec 的用户建模用的是深度神经网络结构,能直接从大规模数据中自动学习复杂兴趣变化。这让模型能动态适应用户的多变需求,让推荐更接近真实兴趣轨迹。
是不是有点烧脑?
我们继续,前面分别讲了快手的新一代推荐系统 OneRec 是怎么理解用户和视频内容的。接下来最关键的一步,就是怎么做二者之间的匹配。
OneRec 在这里采用了新的生成架构:不再按部就班筛选内容,而是把用户兴趣、内容特征一同输入大模型,由系统一步步生成完整的内容推荐序列。
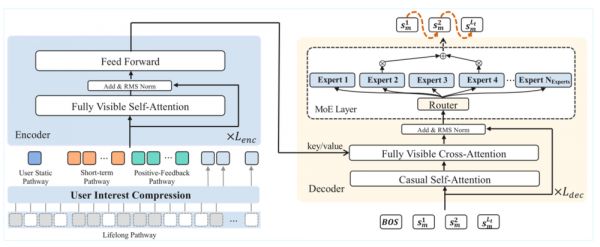
具体来说,OneRec 采用的是编码器-解码器结构。编码器负责将用户的兴趣轨迹压缩成兴趣向量(刚才提到的),解码器则像自动“写清单”一样,逐步生成一串用户可能感兴趣的内容。
在解码阶段,快手引入了 MoE 架构,这种专家混合机制能显著提升模型容量和表达能力,同时让推理效率大幅提升。
举个例子:某位用户在半年时间里,兴趣从科幻变成了美食和生活,OneRec 在生成推荐序列时,会自动综合各个兴趣点的最新权重,让推荐列表里既有用户最近最常互动的内容,也能适当穿插历史偏好甚至冷门兴趣,避免内容变得单一。
MoE 架构的优势在于,每一步推荐内容的生成,都会动态激活一组最合适的专家网络参与协作决策。这样不仅提升了模型对复杂兴趣分布的刻画能力,也保证了算力资源的高效利用。最终,系统既能实现高度个性化的推荐,也能兼顾内容多样性和新鲜感。
再进一步,快手还引入了基于奖励机制的偏好对齐方法,用强化学习系统性增强了推荐的效果。
传统推荐领域,强化学习其实早就被提出,但在多阶段流水线体系下,往往水土不服——反馈信号稀疏、链路割裂,业务线上难以全链路闭环,模型很难捕捉到用户真实而细致的偏好,优化也很有限。
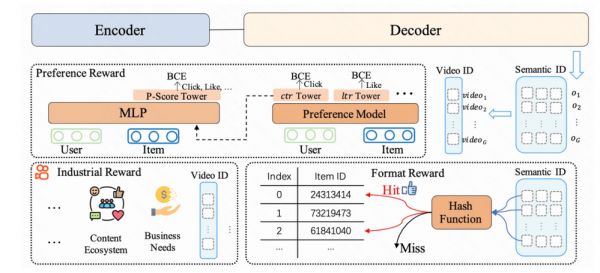
OneRec 的端到端生成式架构,让强化学习首次真正贯穿内容理解、用户建模、推荐生成全链路。具体做法,是构建了一套综合性的奖励系统,把不同业务目标直接内嵌进模型训练。最重要的有三类:
第一类是偏好奖励,目的是让模型学会分辨用户到底喜欢什么。比如有的人喜欢剧情反转,有的人爱看宠物卖萌,这一类奖励会帮模型自动给每种内容打个性化分数,推得越对味,分越高。
第二类是格式奖励。传统强化学习在推荐系统里有个老大难问题,模型容易只推一种内容,造成内容同质化,也就是所谓的挤压效应。OneRec 专门设计了一套格式奖励,确保每次推荐出来的内容都合法有效,既有主流,也有冷门内容,内容分布更加均衡。
第三类是工业场景奖励,主要是为了适配实际业务的复杂场景,比如适度抑制营销号、给新视频和长尾内容一定的曝光机会。模型会结合这些业务规则,动态平衡不同类型内容的分发,避免平台只剩下爆款内容或刷屏套路。
这些奖励信号贯穿在模型训练和优化的全过程,模型每做出更优的推荐决策都会得到正向激励,反之则被及时修正。最终,OneRec 让强化学习真正落地在工业级推荐系统中,实现了业务目标与用户体验的双重提升,也让推荐结果变得更加多元和动态。
据快手官方披露,OneRec 在灰度阶段的数据表现其实挺值得关注的。在主站和极速版的短视频推荐主场景,快手做了一周 5% 流量的 AB 测试。
结果是,仅靠生成式模型加 RL 对齐用户偏好,就已经能跑到和原有复杂系统类似的效果。如果再叠加奖励模型选择策略,用户停留时长分别提升了 0.54% 和 1.24%,7 日用户生命周期也有 0.05% 和 0.08% 的增长。
别小看这些数字,在快手这种日活用户体量下,0.1% 的停留时长提升就已经有统计意义了。更重要的是,不光是停留时长,点赞、关注、评论等一系列交互指标也都在往好的方向走。目前,OneRec 已经承接了快手短视频推荐主场景 25% 的请求。
除了短视频推荐外,OneRec 在本地生活场景的表现同样不差。AB 实验数据显示,GMV 提升了 21%,订单量、购买用户、新客获取效率也都是两位数的增长。现在本地生活业务线已经实现了 100% 流量切换,并且上线后核心指标比灰度阶段还进一步扩大,说明 OneRec 的泛化能力确实比较强。
当然,OneRec 并不是终极答案,眼下它依然有不少工程和算法难题要解决。比如推理速度、训练资源消耗、冷启动内容的分发策略,以及奖励机制的进一步优化,都是团队后续需要持续攻坚的地方。包括用户兴趣的极端多样性和时效性,如何在模型架构和采样机制上继续提升灵活性,未来也有不少空间。
但有一点已经很明显:OneRec 把推荐系统推进到了一个全新的阶段。以前推荐系统总是慢半拍,最新的 Scaling Law、强化学习、硬件能力提升,业界能用到的都非常有限。现在这种大模型驱动的端到端生成推荐,等于是把推荐和 AI 最新进展重新拉回同一起跑线。
新一代的推荐系统,也来了。2025 年,真有意思。
本文来自微信公众号:MacTalk,作者:池建强
相关推荐
聊聊快手的差异化叙事
快手折叠下的「棒!少年」与「杀马特」
华为之后,这次我们去阿里“未来酒店”聊聊技术落地
快手进入巴西,这次走在了抖音前面
全新Mac、跨平台体验,苹果想跟游戏开发商聊聊
重新审视快手的商业价值
18岁辍学,如今身价400亿,李想的人生很理想
除夕放假,大厂这次想明白了
3亿美元,腾讯第三次领投行业AI独角兽明略,这次还有淡马锡领投,快手跟投
对话快手宿华:最底层的原则是利他
网址: 特想聊聊快手这次的变化 http://m.xishuta.com/newsview138006.html
