自主agent路线错了,华人学者提出LLM-HAS:从“自主能力”转向“协作智能”
构建无所不能、无需人类、完全自主行动的 AI agent,是当前大模型行业的热门研究方向。
主流观点认为,更高的自主性代表了更好的系统——减少人类介入本身就具有内在价值,而完全的独立性则应成为最终目标。
然而,华人学者 Philip S. Yu(伊利诺伊大学芝加哥分校杰出教授、ACM Fellow、IEEE Fellow)、李东远(东京大学助理教授)团队却有着不一样的看法:
应当将进步的评判标准从“自主智能”转向“协作智能”,即发展以人机合作为核心的 LLM-HAS(基于 LLM 的人-agent 系统)。
在这种范式下,AI 不再是孤立运作的“操作员”,而是人类的积极协作伙伴;在增强人类能力的同时,也保留了关键的人类判断与监管职责。
相关研究论文以“A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy”为题,已发表在预印本网站 arXiv 上。

论文链接:https://arxiv.org/pdf/2506.09420
在他们看来,AI 的进步不应以系统独立程度来衡量,而应以它们与人类协作的有效性来评判;AI 最值得期待的未来,不在于取代人类角色的系统,而在于通过有意义的合作来提升人类能力的系统。
他们呼吁,业界和学界应从当前对完全自主 agent 的追逐,根本性地转向以人机协作为核心的 LLM-HAS。
为什么完全自主agent“不行”?
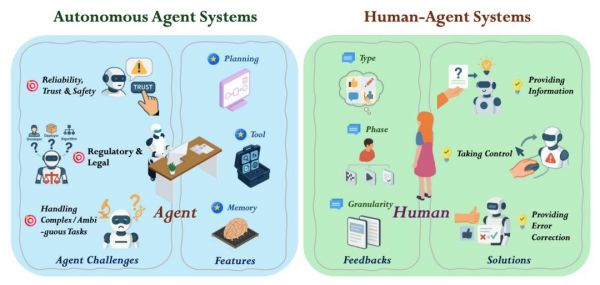
基于 LLM 的自主 agent 是一种能够在开放、真实世界环境中独立运行的系统,通过“感知-推理-行动”的循环完成任务,且无需人为干预。
与 Human-in-the-loop 系统不同,基于 LLM 的自主 agent 能够独立地解析目标、规划行为、调用工具,并通过基于语言的推理和记忆进行适应。
例如,在软件工程领域,GitHub Copilot 可以自主生成、测试并重构代码,几乎不需要开发者干预,加速了常规开发流程;在客户支持领域,AutoGLM、Manus 和 Genspark 等系统能够在无需人工干预的情况下,完成复杂的行程规划、自动预订以及解决服务问题,在动态环境中展现出优秀的感知-动作循环能力。
然而,当前基于 LLM 的自主 agent 在真实世界的部署仍面临以下三方面挑战:
缺乏可靠性、信任与安全
LLM 容易生成看似可信但实则虚假的“幻觉”内容。幻觉问题的普遍存在,直接削弱了人们对完全自主系统的信任。如果系统无法持续且可靠地提供准确的信息,它在高风险场景下(如医疗诊断、金融决策或关键基础设施控制)将极为危险。
处理复杂与模糊任务的能力不足
这类 agent 在需要深度推理的任务中表现不佳,尤其当目标本身含糊不清时更是如此。人类的指令往往并不明确;缺乏常识背景的 LLM 可能会误解任务,进而采取错误行为。因此,在如科学研究等目标开放、动态调整的复杂领域,它们并不可靠。
法规与法律责任问题
尽管这类系统具备“行动能力”,但在现有法律体系下,它们并不具备正式的法律责任主体资格。这就导致了责任与透明度之间存在巨大鸿沟:当系统造成伤害或做出错误决策时,很难厘清责任应由谁承担——是开发者、部署者,还是算法本身?随着 agent 能力的增强,这种“能力”与“责任”之间的法律鸿沟只会愈加严重。
LLM-HAS:以人机合作为核心的
与基于 LLM 的完全自主 agent 不同,LLM-HAS 是一种协作框架,其中人类与由 LLM 驱动的 agent 协同工作,共同完成任务。
LLM-HAS 在运行过程中始终保持人类参与,以提供关键信息和澄清说明,通过评估输出结果并指导调整来提供反馈,并在高风险或敏感场景中接管控制权。这种人类参与,确保了 LLM-HAS 在性能、可靠性、安全性和明确的责任归属方面的提升,尤其是在人类判断仍不可或缺的领域。
推动 LLM-HAS 的根本动因,在于它具备解决自主 agent 系统所面临关键局限和风险的潜力。
增强的信任与可靠性
LLM-HAS 的交互性特征,使人类能够实时提供反馈、纠正潜在幻觉输出、验证信息,并引导 agent 产生更准确、可靠的结果。这种协同验证机制是建立信任的关键,尤其在高错误代价场景下至关重要。
更好地处理复杂性与模糊性
相较于在面对模糊指令时容易迷失方向的自主 agent,LLM-HAS 借助人类持续的澄清能力而表现出色。人类提供关键的上下文、领域知识,并能逐步细化目标——这是处理复杂任务所不可或缺的能力。当目标表达不明确时,系统可以请求澄清,而不是在错误假设下继续操作。特别适用于目标动态演变的开放式研究或创造性工作。
更明确的责任归属
由于人在决策流程中持续参与,特别是在监督或干预环节,更容易建立明确的责任边界。在这种模式下,通常可以明确指定某个人类操作员或监督者为责任主体,从而在法律与监管上更具可解释性,远比一个完全自主的系统在出错后追责要清晰得多。
研究团队表示,LLM-HAS 的迭代式沟通机制有助于 agent 行为更好地对齐人类意图,从而实现比传统的基于规则或端到端系统更灵活、透明且高效的协作,从而广泛地应用于高度依赖人类输入、情境推理与实时互动的各类场景,涉及具身智能、自动驾驶、软件开发、对话系统以及游戏、金融、医疗等。
在上述领域中,LLM-HAS 将人类与 AI 的交互重新定义为基于语言的协作过程,该过程受反馈塑造并由适应性推理驱动。
五大挑战与潜在解决方案
尽管 LLM-HAS 展现出广阔的应用前景,但要成功落地,还必须在开发全周期中审慎应对其固有挑战。主要涉及初始设置、人类数据、模型工程、后期部署和评估。
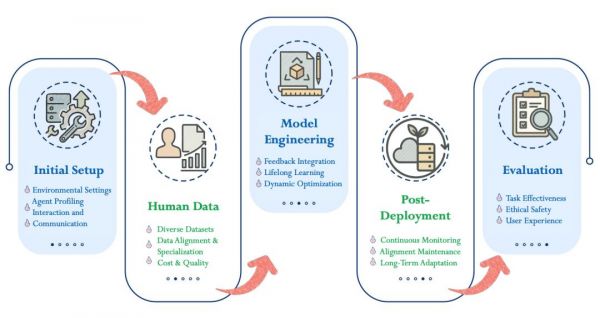
初始设置:仍聚焦于 agent 本身
目前关于 LLM-HAS 的大部分研究采用以 agent 为中心的视角,其中人类主要评估 agent 的输出并提供纠正反馈,这种单向交互主导了现有范式,重新塑造这种动态关系存在巨大潜力。
若使 agent 能够主动监控人类表现、识别低效环节并及时提供建议,将使 agent 的智能得到有效利用并减轻人类工作负荷。当 agent 转变为指导性角色,提出替代策略、指出潜在风险并实时强化最佳实践时,人类与 agent 的性能均会提升。研究团队认为,转向更以人为本或更平衡的 LLM-HAS 设计,是实现真正人-agent 协作的关键。
人类数据:人类反馈的差异性
人类在 LLM-HAS 中的反馈在角色、时机和表达方式上差异巨大。由于人类具有主观性,受个性等因素影响,同一系统在不同人手中可能产生完全不同的结果。
另外,很多实验中使用 LLM 模拟“伪人类”反馈。这类模拟数据往往无法真实反映人类行为差异,从而造成性能失真,削弱比较的有效性。
高质量人类数据的获取、处理与使用,是构建对齐良好、协作高效的 LLM-HAS 的基础。人类生成数据能够帮助 agent 获得更细致的理解,提升其协作能力,并确保其行为符合人类的偏好与价值观。
模型工程:缺乏适应性与持续学习能力
在 LLM-HAS 的开发中,打造真正“适应性强、可持续学习”的 AI 合作者仍是核心难题。
目前主流方法将 LLM 视为静态的预训练工具,导致“未能有效吸收人类洞见”、“缺乏持续学习与知识保持能力”和“缺乏实时优化机制”等问题,
要充分释放 LLM-HAS 的潜力,必须通过“人类反馈融合、终身学习机制和动态优化策略”的整合方式,突破上述瓶颈。
后期部署:尚未解决的安全脆弱性
部署后的 LLM-HAS 仍在安全性、鲁棒性和责任归属方面面临挑战。目前业界往往更关注性能指标,然而在人机交互中的可靠性、隐私与安全等问题尚未得到充分研究。确保可靠的人机协作需要持续监控、严格监督以及整合负责任的人工智能实践。
评估:评估方法不充分
当前针对 LLM-HAS 的评估体系存在根本缺陷。它们通常偏重 agent 的准确性与静态测试,往往完全忽略人类协作者所承担的真实负担。
因此,我们迫切需要一套新的评估体系,从(1)任务效果与效率、(2)人机交互质量、(3)信任、透明度与可解释性、(4)伦理对齐与安全性、(5)用户体验与认知负荷,多维度综合量化人类与 agent 在协作中的“贡献”与“成本”,从而真正实现高效、可靠且负责任的人-agent 协作。
本文来自微信公众号 “学术头条”(ID:SciTouTiao),作者:学术头条,36氪经授权发布。
相关推荐
异构智能体自主协作,大模型扮演了什么角色?
自主CPU会从什么路线突破?
为什么AI团队越做越累,Agent系统却越跑越差?
万字长文,聊聊下一代AI Agent的新范式
押注 Agent,钉钉想做 AI 创业平台
微软AI Agent支持A2A、MCP协议!智能体协同生态大爆发
百度智能云升级千帆:云平台战场转向体系能力比拼
可联网自主完成任务,OpenAI发布智能体Operator,给AI Agent又添了把火
人工智能需要自主学习
法本信息AI Agent技术赋能垂直行业智能化
网址: 自主agent路线错了,华人学者提出LLM-HAS:从“自主能力”转向“协作智能” http://m.xishuta.com/newsview137385.html