18万引大牛Sergey Levine:不是视频模型“学习”慢,而是LLM走捷径
为什么语言模型能从预测下一个词中学到很多,而视频模型却从预测下一帧中学到很少?
这是UC伯克利大学计算机副教授Sergey Levine最新提出的灵魂一问。
他同时是Google Brain的研究员,参与了Google知名机器人大模型PALM-E、RT1和RT2等项目。
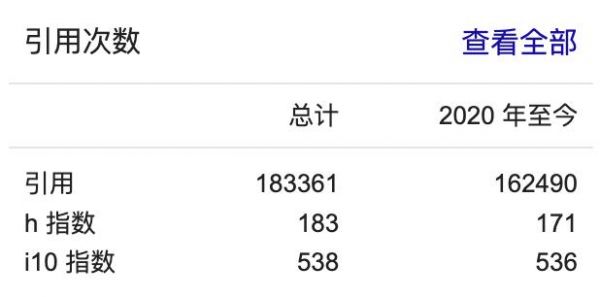
Sergey Levine在谷歌学术的被引用次数高达18万次。
“柏拉图洞穴”是一个很古老的哲学比喻,通常被用来说明人们对世界认知的局限性。

Sergey Levine的这篇文章以《柏拉图洞穴中的语言模型》为题,又想要揭示AI的哪些缺陷呢?

在文章的开头,作者提到人工智能就是在研究能够反映人类智能的灵活性和适应性的假想智能。
一些研究者推测,人类心智的复杂性和灵活性源自于大脑中应用的一个单一算法,通过这个算法可以实现所有多样化的能力。
也就是说,AI如果能复现这个终极算法,人工智能就能通过经验自主获取多元能力,达到人类智能的高度。
在这个探索过程中,语言模型取得了非常成功的突破。
甚至,LLMs实现能力跃升背后的算法(下一词预测+强化学习微调),也非常简单。

单一终极算法假设似乎就是AI模型的答案……
然而,这个假设对视频模型并不适用。
语言模型与视频模型的对比
早在基于Transformer的语言模型出现之前,AI研究人员就已经忙着研究一个看似非常相似的问题:
就像LLM通过预测来自网络文本数据的下一个词来学习一样,视频模型也可能通过预测视频数据的下一个帧来学习。
甚至从数据上来说,视频数据比文本数据包含的信息更丰富,那么预测下一帧得到的认知会远比预测下一词得到的认知更全面。
比如,一个飞往宇宙探索的机器人,在那里没有人能提供文本,但是它仍然能获取丰富的视频数据。
基于这些证据,我们可以认为能够“观察”到更多物理世界的视频模型应该比语言模型更加强大。
然而,事情并没有按研究人员所期望的那样发展。

尽管视频预测模型可以生成逼真的视频,但在解决复杂问题、进行复杂推理方面,语言模型仍然是主要且唯一的选择。
这与LLMs对物理世界的“观察”更少,却获得了更复杂的认知能力形成了鲜明对比。
就像文章中举出的例子:我们并不能用Veo 3估算夏威夷群岛的岩石体积是否比珠穆朗玛峰更大,但ChatGPT却可以回答这个问题。
这是因为LLMs只需要调用人类总结的地理知识(文本中已有相关数据或推理路径)。
简单来说,视频数据是物理世界的直接映射,而非人类认知的加工产物。
视频模型需自主归纳物理规律,而LLMs却可以 “抄近路” 模仿人类已有的推理结果。
LLMs 仅接触文本 “影子”(人类认知的投影),却比直接观察物理世界的视频模型更具推理能力。
作者认为,这是LLMs只会对人类进行“脑部扫描”,而非真正学会了像人类一样推理问题。
就像是AI系统存在于「柏拉图洞穴」中。

AI系统的“柏拉图洞穴”
“柏拉图洞穴”原本的故事是指一群人被绑在洞穴里,只能看到墙壁上的影子,不能看到洞穴外的阳光。
这个故事通常被用来说明人们对世界认知的局限性。
在文章中,作者将互联网比作洞穴,将真实世界比做洞穴外的阳光,用“柏拉图洞穴”来类比AI的现状。
AI通过语言模型学习人类的知识和思维方式,但这些知识就像洞穴墙壁上的影子,是人类智慧的间接反映。
它们并没有真正理解世界,其能力是对人类认知的 “逆向工程”,而不是自主探索。
而视频模型目前连影子都无法认知……
AI该如何走出洞穴?
作者认为既然LLMs已经了实现人类认知的部分模拟(如推理、生成),那么就可以将它可 “心智原型”,为通用AI提供起点。
而长期目标则是突破“影子依赖”,不再依赖人类中介(类似文本数据),让AI通过传感器直接与物理世界交互,自主探索。
对此,有评论者提出:视觉、语言、行动系统就像独立的洞穴,如果能够通过共享结构建立桥梁,可能就不需要逃离“洞穴”,跨模态连接就成了探索过程中的挑战,需要找到一个连接这些模态的统一的方法。

对于AI的“洞穴困境”,你有怎样的看法呢?
参考链接:
[1]https://x.com/svlevine/status/1931796654233194534
[2]https://sergeylevine.substack.com/p/language-models-in-platos-cave
本文来自微信公众号“量子位”,作者:闻乐,36氪经授权发布。
相关推荐
斯坦福、伯克利大神教授创业给机器人造大脑,OpenAI红杉抢着投5亿
他们给机器人造大脑,OpenAI红杉抢着投5亿
谷歌大牛回国出任首席科学家 智元机器人推进具身智能落地
强化学习,正在引领AI跨越LLM之谷
Karpathy观点惹争议:RLHF不是真正的强化学习,谷歌、Meta下场反对
AI大语言模型LLM,为啥老被翻译成“法学硕士”?
大模型走捷径“刷榜”?
通用机器人,是AI时代的新“iPhone”吗?
LLM是初级程序员的外挂,却让高级工程师无感?解析LLM的影响曲线!
最新!智元机器人出手,挖来前谷歌90后具身智能大佬!
网址: 18万引大牛Sergey Levine:不是视频模型“学习”慢,而是LLM走捷径 http://m.xishuta.com/newsview137201.html