3700次预训练找线性注意力非共识,MiniMax-01开发者讲述4年探索

“我们跑的是下半场,赌的就是未来的长文本需求。”
嘉宾丨钟怡然
整理丨刘倩 程曼祺
上期播客中,我们与清华的两位博士生,肖朝军和傅天予,聊了稀疏注意力机制的改进,也以注意力为线索,串起了大模型的优化史。
这篇聊关于注意力机制的另一大改进方向:线性注意力。
MiniMax 在今年 1 月发布了参数为 4560 亿的开源大模型 MiniMax-01,该模型就用到了他们开发的线性注意力机制 “Lightning Attention”。
我们邀请了这个项目的负责人,MiniMax 高级研究总监钟怡然,来与我们一起聊线性注意力的研发过程。钟怡然在 MiniMax 负责大模型网络架构设计,目前正开发多模态深度推理模型。
钟怡然曾担任上海人工智能实验室青年科学家,是新架构探索组的 PI(项目负责人);他在澳洲国立大学获得博士学位,师从李宏东教授和 Richard Hartley 院士。他和他的团队已在一些国际顶级学术会议和期刊上发表了 20 余篇关于模型新架构的论文,覆盖了当前多类非 Transformer 架构,如线性注意力机制(线性注意力)、长卷积(Long Convolution)和线性循环网络(Linear RNN)。
在 2021 年,线性注意力还是一个 “看起来很美好的泡泡”,怡然和团队就开始探索线性架构的实现。
当 2024 年年中,MiniMax 开始用大量算力资源训练线性架构的 4560 亿参数的新一代模型 01 时,线性架构能在大规模模型上 work 是非共识。但 MiniMax 创始人闫俊杰最后拍板,投了公司超过 80% 的研发资源。
训练模型不是戏剧性的豪赌。在训 MiniMax-01 前,MiniMax 团队通过 3700 次预训练测试,去预测这种新架构在更大参数的模型是否也有好的表现(这其中不少都是小规模实验)。
在效率上,从计算方法推导,当序列非常长,线性注意力在计算效率上的优势会越来越大于稀疏注意力。
但从效果上,也就是线性注意力架构的模型能否和 Transformer 模型一样聪明,甚至更聪明。现在还没有谁能给出有绝对说服力的答案。
这也是之后 MiniMax 的技术进展,可能会揭晓的悬念。
* 以下是本期播客实录,有文字精简。正文中的(注:……)为编者注。
“线性注意力在越大的模型上,优势越明显”
晚点:怡然,可以先和我们的听友简单介绍一下自己?
钟怡然:我目前是 MiniMax 的高级研究总监,主要负责模型结构设计和多模态理解大模型。我主导设计了 MiniMax-01 新一代的网络架构,此前曾担任上海人工智能实验室青年科学家,是新架构探索组的 PI(项目负责人),负责新一代非 Transformer 架构的研发及视听多模态融合。
我们同时也在新架构的工程上进行研究,相当于新架构的一些并行策略。针对国产集群通信系统效率不足的现状推出了异步优化器,在计算机视觉和自然语言处理上都验证了它的有效性。
晚点:其实不止你们,各公司都在优化注意力机制,这个大背景是什么?
钟怡然:因为 Transformer 有个大 bug:显存开销和计算是二次复杂度(注:二次复杂度就是平方增长——随着模型要处理的序列的增长,计算复杂度是平方增长)。FlashAttention 主要解决了显存占用的问题, 但计算复杂度问题依然存在。
学术界最早尝试用 “稀疏注意力” 减少计算量,但它不能完全解决二次复杂度的问题。不过有一段时间,算力的增加掩盖了二次复杂度的紧迫性:从 V100 到 A100 再到 H100(英伟达的三代高性能 GPU),算力提升非常大。所以现在很多的大模型仍然采用 Transformer 架构,它的序列长度也可以做到一定的扩增,比如说到 128K、256K。
我们就一直想解决计算的二次复杂度的问题,于是,在 2021 年,当线性注意力还处于研究初期时,我们开始尝试这个方向。线性注意力的机制其实十分简单,注意力的计算是 Q、K、V 相乘。
如果直接左乘,也就是先乘 Q、K 再乘 V 的话,它就是二次复杂度;如果先乘 K、V,再乘 Q 的话,它就是线性复杂度(即一次方复杂度)不会增长特别多。那线性注意力就是把左乘变成右乘的形式。
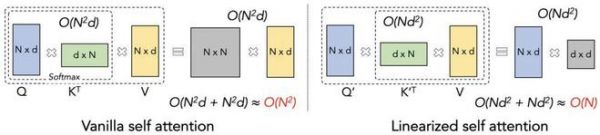
Transformer 原始注意力机制(Vanilla self attention)计算方式(左)和线性注意力(Linearized self attention)(右)的对比。
原始注意力是先 Q、K 相乘,再乘 V,而线性注意力是从左乘(先乘左边)转为右乘,最后计算复杂度从二次变为一次(从 N² 变为 N)。
图中符号的意义:
N:序列长度,在自然语言处理任务中,指句子中 Token 或词的数量。
d:特征维度,即每个元素(如单词的词向量)的维度。
O(N²d)、O(Nd²) :计算复杂度。大 O 描述了计算量随输入序列变长的增长速度,如 O(N²d) 表示计算量与 N² 和 d 成正比 。
Q(Query):“查询” 矩阵,用于在自注意力机制中向其他元素询问相关信息。
K(Key):“键” 矩阵,与查询向量配合,用于计算相关性。
V(Value):“值” 矩阵,是 Q 和 K 计算出的注意力权重,对 V 进行加权求和,会得到自注意力机制的最终输出。
Kᵀ:K 的转置矩阵,在矩阵运算中,为使矩阵维度匹配进行乘法运算,常需对矩阵进行转换操作。
Q′、K′:在线性化自注意力机制中,对 Q 和 K 进行某种变换后的矩阵。
晚点:你们当时有试过稀疏注意力的方向吗?
钟怡然:我们在 2021 年的时候试过,但它当时的效果和运行效率都不太行。其实跟线性注意力是同样的问题:那时稀疏的效果比不上 Softmax Attention,速度顶多快一丢丢。
而且我注意到稀疏注意力是有损逼近。因为 Attention Metrics(注意力值组成的矩阵)是一个完整的 N×N 的矩阵,而稀疏注意力仅在其中计算有限个 Attention Score(注意力值,即两个词之间的相关性)。所需算力自然会降低,但这是一个有损的逼近。我们认为这得不偿失。
晚点:那 NSA 和 MoBA,包括最近微软亚研院 SeerAttention 这些新的成果——它们都是属于稀疏注意力的大方向,你怎么看待它们的效果和效率表现?带来了什么新认知?
钟怡然:具体我们还在做进一步的实验。从我们现在的实验上来说的话,Lightning Attention(MiniMax-01 中使用的混合注意力机制)是我们当前测试的方案中,随着模型参数越大,增益越明显的一个优化的方向。
我们测试过 MLA(DeepSeek 提出的一种减少显存开销的注意力改进),也测试过 TPA(注:清华提出的一种减少显存开销的注意力改进)。我们发现那些方法随着模型的增大,优势就会变得比较小,也就是说,它的压缩方式对模型大小是有要求的。
而 Lightning Attention ,它是模型越大时,展现的优势越明显。现在放出来的 NSA、MoBA、SeerAttention,我们认为他还没有真正做工业级的 Scale Up(规模扩大)。
晚点:MoBA 不是也放了工程代码吗?在线上跑了一年了。
钟怡然:那需要开源让其他开发者能真正看一下,在几百 B 参数的模型上,它与 Transformer 比是否具备优势。目前,它们的性能对比最多在 7B 规模上得到了验证。而在 2023 年中期左右,我们对 Lightning Attention 的验证就差不多到了 7B。
晚点:稀疏注意力和线性注意力在不同大小模型上的效果差异,在几 B 参数的模型之后会有明显区别?
钟怡然:7B 以上基本就可以看到。而 MiniMax-01 是一个总参数 4560 亿,激活 459 亿的 MoE 模型。(注:MoE 是混合专家系统,其核心机制是通过动态路由在推理时仅激活部分子模型,即 “专家”,显著降低计算资源消耗。)
晚点:总体来说,现在学界或者工业界是稀疏注意力做的人多,还是线性注意力做的人多?
钟怡然:这两个方向其实尝试的人都比较多。2023 年以后,线性注意力是比较火的,因为 Mamba 那时候大火,带火了这个方向。
晚点:从对 Transformer 的 Full Attention 改动程度上说,是不是稀疏改得相对少一些,线性会改动多一些?
钟怡然:对,稀疏本质上还是一个 Transformer,它只是对 Attention Score 的计算方式做了一些改进。而线性注意力是改变了 QxKxV 相乘的计算方式。学术界对它的叫法很多,你可以把它叫作线性注意力,也可以把它叫作线性 Transformer。
晚点:线性注意力和 Transformer 以前的 RNN(循环神经网络) 有什么区别?
钟怡然:它本质上也是一种循环,不过以前的 RNN 最大的问题是它没法并行化,Linear RNN (线性循环网络)让它能够做大规模的并行化。
50% 的把握,投 80% 的资源
晚点:接下来我们可以从头聊一聊,你们从 2021 年开始做线性注意力,到今天,这样一步步,是个什么过程。
钟怡然:2021 年 7 月,我们启动了 cosFormer 项目,这也是我们首次接触线性注意力领域,相关研究成果发表在了 ICLR 上。cosFormer 如今在线性注意力上的知名度还可以。从那时起,我们发现这个方向大有可为。
当时想法很简单:一方面,做 Transform 的人已经很多了,即便在这个领域做到极致,也不过是跟在别人后面。但是,线性注意力作为一个新兴方向,关注者较少,与其追随他人,不如另辟蹊径。
其实线性注意力领域的一些论文出来得也很早,几乎与 Transformer 同时。但它的效果不好、速度又慢,所以导致大家觉得它是一个 “美好的泡泡”,看起来很好,但是实际用起来不行。
2021 年- 2022 年,我们密集产出,探索了很多方法,包括线性注意力机制、长卷积(Long Convolution)和线性循环网络(Linear RNN),我们探索了现有的几乎所有线性方案。到了 2022 年底,我们所研发的方法在语言建模方面,已经能够达到与 Transformer 近乎相同的效果 。
晚点:当时你们是去测哪些 benchmark,就是你们怎么去判断说当时的线性架构已经和 Transformer 差不多了?
钟怡然:当时测的都是学术上的数据集。例如会关注困惑度、建模精度等,同时也会在一些常见的大模型数据榜单上,基于相同数据对比线性和 Transformer 的结果,也测过 Long Range Arena(注:由 Yi Tay 等研究者在 2020 年提出的针对长序列场景的测试基准)这类长文本 benchmark。
在实验室阶段,我们第一步是解决线性注意力的建模精度问题,第二步是处理速度问题。线性注意力存在一个棘手的问题,它虽然理论复杂度是线性,但实际上跑起来很慢,这是因为右乘操作涉及一系列循环操作,而这对于 GPU 极不友好,这就导致实际运行效率远低于理论复杂度。为解决这一难题,我们在 2020 年推出了 TNL 和 Lightning Attention。Lightning Attention 就是让它的实际效率更接近它的理论计算复杂度。
所以这一段,在上海人工智能实验室期间,我们认为它已经达到了 Scale Up ready 的状态。我们自认为已经解决了精度问题,也解决了推理效率问题。
晚点:当时做到这个 Scale Up ready 状态,最大是在多大模型上做了测试?
钟怡然:最大是训到了 15B 的模型。
晚点:你们当时没有继续往下做更大规模的 Scaling Up 的测试,是因为在实验室里会有一些资源的限制吗?
钟怡然:当时对我来说,需要把它真正做到 Scale Up,我就面临一个找金主的过程。
那时我是比较着急的,因为我判断,最迟在 2024 年底,基于线性注意力的大模型必然会诞生,不是我们做出来,就是 Google、OpenAI 等其他机构。既然要诞生,为什么不在我们自己手里了?我们是当时最懂线性注意力的人。
晚点:最懂指中国,还是指全球?
钟怡然:基本上是全球。包括现在比较活跃的松林(杨松林)之前也是我们组员。所以当时其实就是有个想法,想找到人愿意投资这个方法,支持我们把它(线性架构) Scale Up。
晚点:你最后找到的 “金主” 就是 MiniMax?
钟怡然:这实际上是一个双向的过程。之前我在商汤工作时,就在俊杰手下。我记得在 2023 年底,俊杰恰好约我一起吃饭,正好聊到了线性注意力的问题。
晚点:你是不是也想过自己创业?
钟怡然:我考虑过,但这很难。基础架构创新需要的投资金额非常高,而我们仅在算法上具备优势。
大模型很复杂——首先架构要好,再者训练数据要好,最后训练方式也要对,三环是缺一不可;任何一个地方掉了链子,都会没法证明你想要证明的东西。首先我得保证这家公司能做一流的预训练,在这一点上已经砍掉很多公司了。
晚点:你当时见一些投资人,他们的反馈是什么?
钟怡然:他们比较喜欢聊,你的应用方向是什么?变现渠道是什么?将来怎么样去盈利?
晚点:公司方面,你当时看到的,能做一流预训练的公司都有哪些?
钟怡然:大小公司算上,我觉得第一个是字节跳动,第二个是 MiniMax。
晚点:Kimi (月之暗面)不是吗?
钟怡然:关于 Kimi,我得到的消息比较少,所以当时在我眼里,只有两个选择,要不然就是海外了。
晚点:你和字节聊,得到了什么反馈?
钟怡然:我感觉字节的兴致不是很高。作为一家大公司,虽然有数据也有人,但要让他们真正转型,去花那么大精力去做一个未知的方向,比较难。
晚点:回到 2023 年下半年,你和闫俊杰聊,他的反馈是什么?
钟怡然:早在 2021 年,我和俊杰已非常熟悉。经过交流,我们发现他是很愿意去尝试的,并且愿意调配公司绝大部分精力投入其中。
因为这个模型是一个主模,研发要耗费公司 80% - 90% 的资源,牵扯到数据团队、工程团队、算法团队等众多部门,需要大量人员齐心协力才能完成 。
晚点:闫俊杰比较认可你,是因为他们之前在线性注意力机制上也有一些探索?
钟怡然:之前他们在这块的工作不太多,当时正处于下一代模型技术选型阶段。俊杰或许认为我的工作比较扎实,他对这个工作比较信任。
当然,俊杰看这件事的视角与我不同,我认为有 99% 的成功率。而对他而言,可能觉得成功与失败的概率各 50%。对我们这些一直深入钻研的人来说,我们熟知其中关键要点,所以我们是很相信能够 Scale Up 的。
晚点:闫俊杰有 50% 把握,就敢上 80% 的资源,这个赌性是不是有点大?
钟怡然:这确实是要赌的。但我们有 Scaling Laws 的测试去一步一步验证,他不是一开始就 all in 全部弄起来。我们是先在成本可控的范围里做小的模型,再做大的模型。
3700 次预训练验证非共识:从 “美好的泡泡” 到 4560 亿参数的 MiniMax-01
晚点:在你们一步步去验证这个想法的过程中,你们又看到了什么?
钟怡然:2023 年底,我们用的还是一个纯线性的方案,训练出了一版 15B 规模的模型,从效果来看与 Transformer 相差无几。
但是,后续当我们扩大模型规模后却发现,无论是 Lightning Attention,还是其他线性方法,都存在一个最大的问题——在 Retrieval(召回)上存在缺陷。
所以我们不得不选择了一个比较折中的方案,通过混合架构——每 7 层线性注意力加入 1 层 Softmax 注意力进行优化。
晚点:可以给我们的听友也解释一下,Retrieval 是个什么样的能力?以及注意力机制改进都会去测的、检验 Retrieval 能力的 “大海捞针” 的任务是个什么任务?
钟怡然:Retrieval 指的是召回或检索能力。以 “大海捞针” 任务为例,给定一篇长文,其中存在一段话或一句话与其他内容格格不入,此时就需要用定点召回能力找出来。“大海捞针” 是测试,在很长的长文中,模型能不能找到这根格格不入的针,这是一项基础能力 。
线性注意力在执行这项任务时先天不足,这也很正常。因为线性注意力的 KV 缓存是一个固定值,无论输入文本多长,都会被压缩至一个固定大小的存储中。这个过程会导致它检索能力较差。
晚点:你当时会压力山大吗?因为已经要上规模了,出现这种情况。
钟怡然:我们是有保底方案的,就是混合。但我们当时觉得这个方案确实不好看、不够优雅。
晚点:所以你们最后去改善纯线性注意力召回 能力比较差的方式,就是你们现在在技术报告里写的—— 7 层线性注意力混合 1 层 Softmax 注意力?
钟怡然:对,我们也试了每隔十四层、十六层混合一个 Softmax Attention ——测试了不同的混合比例。从最终结果来看,受影响最大的是检索能力,而在语言建模方面,不同混合比例下的能力差异不是很大。
晚点:在做的过程中间,具体以什么比例混合?有任何理论指引或解释吗?能帮助提前判断一下效果的?
钟怡然:这个没有,我们是自己试出来的。我们甚至试过最极端的情况——仅采用一层 Softmax Attention(注:指大几十层的模型中,只有一层是 Softmax,其他都是线性注意力),效果也还算不错。
我们最终选了现在这个方案,主要是因为已经比较激进地改了架构,我们担心最终效果会受损,所以选了一个相对保守的 1:7 的比例。比如之前 Jamba 的混合层数,也是 1:8 、1:7 这种。
(注:Jamba 是由 AI21 Labs 于 2024 年推出的首个 SSM(状态空间模型)-Transformer 混合架构大模型,支持 256K 上下文窗口。)
晚点:那最开始,是怎么想到要用混合这种方式的?
钟怡然:这其实是非常符合直觉的一种尝试。
晚点:在有了这个混合的方案后,你们的 Scaling Laws 实验的过程是怎样的?
钟怡然:做 Scaling Laws 实验的首要目的,是验证这个技术方向是否存在问题,混合方案的实验和做 Scaling Law 测试是同时展开的。
我们对多种线性方案进行了测试。除了 Lightning Attention,还涵盖了 HGRN2、Mamba。
晚点:这么多实验,要花多少资源?
钟怡然:我们大概训了 3700 个模型才跑出来一篇文章。因为决定 Scaling Up 是一项重大决策,毕竟,没人愿意投几千万资金去训练一个大模型,最后却以失败告终。
尤其是这种开拓性工作,必须把基础工作做得极扎实。我们要仔细斟酌参数和注意力结构的选择,不同方案都需要对它们测一系列 benchmark,最终在速度和效果间找到平衡。所以一套完整且严格的对比实验是必须的。如果拍脑袋,确实可以省下这部分实验成本,但无疑会增加后续项目失败的概率 。
晚点:训了 3700 个模型,是全部从头训练,3700 次预训练的意思吗?
钟怡然:全部都是从头训的,不同的大小、不同的参数。所以跑 Scaling Law 是一个成本很高的一个实验。
晚点:你们一开始预估的就是要训这么多次吗?总共花了多少资源?
钟怡然:我们最早就有预估,就是 3700 次。我们把需要的卡数、资源数和要训的模型数做了个 excel 表,我们根据这些表去训出来就行了。
晚点:最后你们这个混合的线性注意力结构,带来的实际效率提升是怎样的?
钟怡然:就是你的序列长度是 1M(100 万) 的情况下,它比 Full Attention 的整体处理速度要快 2700 倍。
“探索新架构让我们跟进深度推理没这么快,但我们跑的是下半场”
晚点:这是速度上,效果上,线性注意力怎么保障效果?比如,在 MiniMax-01、Kimi-k1.5 以及 DeepSeek-R1 发布之后,我在朋友的电脑上看了实际测试情况,场景是我们输入了一篇约 2 万字的英文文章,详细讲述了海外社交媒体的使用方式,其中涉及很多功能,我们希望模型回答一个具体问题——人们如何使用社交媒体上的短视频功能。结果 MiniMax-01、DeepSeek-R1 表现都不及 Kimi-k1.5,会回答一些别的东西,这是什么原因导致了差异呢?
钟怡然:其实你所提及的这种能力,与训练数据严格相关。我们只能确保模型具备展现该能力的潜力,但要让模型切实拥有这种能力,训练数据起着至关重要的作用。你提出的这个问题,正是我们下一代模型需要解决的问题。
晚点:目前 MiniMax-01 不是一个推理模型,像 R1 还有 1.5 它是推理模型。那你们现在这个架构去做推理,就是去结合强化学习,它的潜力、方法是怎样的?
钟怡然:我 “盗用” 一下另一家国内大模型公司的结论,他们认为 Linear 架构在推理上会更强一点,他们也在线性架构模型上开展过深度推理的相关实验,结果显示线性模型表现更为出色。
晚点:那你们自己看到的是什么?
钟怡然:我们正在做,现在还不能说得更详细。因为最开始我们并没有选择去马上跟 o1(这个方向),当时国内有一大批追随者,但我们的想法是先扎实提升自身技术能力。我们认为单纯强调推理能力,可能仅会在某些特定方面增强模型性能。然而,R1 发布后,我们发现融入这些推理能力,模型的外推能力显著提升 ,泛化能力更好。
晚点:你们当时研判要把技术基础先做扎实,这些指的是什么?
钟怡然:我们希望这个模型能在内部榜单上跟 4o 差不多,或者跟世界顶尖模型差不多。当时的话 4o 是最先进的模型。
晚点:你们会比较去追求多模态吗?4o 就是一个混合模态的模型。
钟怡然:后来我也接手了多模态理解大模型相关工作。当时在构建多模态模型方面,存在两条可行路径:一是原生多模态,二是基于 adapter(适配器)形式的多模态。经过考量,我判断我们当时应采用 adapter 形式。因为在那时,原生多模态的实现路径尚未完全打通,比如 Gemini-2.0 还未发布。
这个方案优势明显。其一,我们能够快速验证数据是否存在问题;其二,效果能够迅速显现。只需投入较小成本,就能获得性能较好的模型。从我们发布的 VL01 来看,benchmark 结果还是不错的。
晚点:所以可以这么理解,MiniMax-01 在 MiniMax 主线模型中算得上是一次重大转型或升级,此前 MiniMax 的 ABAB 系列,采用的是 Transformer 架构,现在的 MiniMax-01 是线性架构 ——你们语言的、多模态的和未来的模型进展都会在这个新架构上。
钟怡然:对,其实这段的模型更迭很快。
晚点:为什么 MiniMax 愿意去投入做这个改动比较大的、比较激进的方案?
钟怡然:首先,我们想展现自身的技术实力,我们是一家勇于创新的公司,敢押注新技术。并且我们已经将序列长度提升到了 4M(400 万),如果我们愿意的话,我们把它提升到 10M (1000 万)也是能够承受的序列长度。
不过(如果要做 10 M)当下需要考虑的是如何构建 10M 的数据,以及在实现 10M 序列长度后,到底能干什么。目前我们还是打算先将 1M 以内的相关工作做到极致,然后再把它往外推。
晚点:推理之后你们想探索什么?我指从 o1 之后,强化学习被全面引入 Transformer 的整个流程当中,下一个变化可能是什么?
钟怡然:现在行业还是在做深度推理,这波其实刚刚起来,我们也还处于跟进阶段。但我们认为长文本处理在未来仍是一个趋势。我们比较高兴看到像 kimi、DeepSeek,都推出了各自针对长文本优化的模型架构,这意味着大家都踏入了长文本这条赛道。
在我看来,俊杰其实也比较清楚:我们打的是一个长线,短期在效果上一定会落后,因为我们做了新架构,相同的算力和资源的情况下,我们是没有太多人力去做深度推理的,这会导致我们跟随深度推理的脚步慢一点。
但好处就是,当我们去做深度推理时——我们赶上的步伐会很快。所以在这场跑步当中,我们跑的是下半场。我们赌的就是未来长文本的需求。当线性注意力 Scale Up 到一定程度时,在长文赛道上很难碰到对手。
做技术的 “道心” 之争
晚点:你怎么看 DeepSeek、Kimi 等公司对稀疏注意力的改进,效率、效果上取得了不错的效果?
钟怡然:他们的主要创新之处在于,通过极致工程优化,改善了稀疏注意力以前速度过慢的问题。但它(稀疏注意力)的上限是低的,我并不认为 DeepSeek 会继续走这条道路。因为当模型变得更大,线性注意力相比稀疏注意力的优势会更明显,他们想要 Scale Up,在做实验的过程中也会看到这一点。
晚点:线性注意力上限高,而且实际上它可以 work,你觉得这在行业里是一个共识,还是非共识?
钟怡然:这是非共识,包括现在大家还是对线性注意力有担忧,哪怕 MiniMax-01 这样的成果已经发布了,一些人还是觉得线性注意力可能规模上去后会不太行。
晚点:为什么有这种担忧?
钟怡然:可能是 MiniMax-01 的宣传力度不够,导致许多人没关注到。目前很多人的共识是,认为线性注意力属于有损的优化。毕竟从原理上看,用一次计算去逼近二次计算,好像是有损的。但有没有可能这种二次计算复杂度本身就是冗余的呢?而我们认为,它就是一个无损架构、一个无损优化,特别是变成混合架构以后,它的效果甚至还有增强。
这个就属于学术方面的 “道心之争”——技术判断和你的相信是什么。
晚点:据你所知,OpenAI、Anthropic 等国外 AI 公司,他们有在尝试线性架构吗?
钟怡然:他们的架构很可能是基于 Sliding Window Attention(滑动窗口),这也是一种稀疏注意力。他们(Google 等)采用的方法大概率是滑动窗口 +Full Attention。
晚点:所以你们对线性的相信,也并不来自全球顶尖公司做了什么或没做什么?
钟怡然:对,并且我们是真正把论文转化成产品的,现在 MiniMax 的产品就在用这套架构,这证明我们的技术是比较先进的。论文是在 24 年初,产品(用上这个架构)是在 24 年底。
晚点:你刚才讲到,认可线性注意力上限大且能 work,在业界是一个非共识。你现在介意讲这个非共识吗?
钟怡然:不介意,我们希望能传播,希望更多人也来做线性注意力,也希望更多人一起开发长文本应用。其实我们开源 MiniMax-01,就是选择知名度。
晚点:那么你们对 MiniMax-01 这次开源的反馈和影响力满意吗?
钟怡然:有朋友说这个报告写得很好,工作比较 Solid,但是不知道为什么没有很多人知道?我觉得这个现状其实就是要加强传播。同时我们下一代模型也会做得更好。
晚点:为什么在开源 MiniMax-01 时,你们只放了最大参数的版本,没有放不同尺寸?因为一些小尺寸的模型,可能对学界、个人开发者、小机构是更友好的,这才让更多人能参与进来。
钟怡然:我们是有小尺寸的,但俊杰觉得要更重视效果,希望开源的是效果很好的,然后再考虑小模型开源。另外开源不同模型,就要维护不同的模型,其实需要的人力也更多。
晚点:DeepSeek 春节大出圈之后,你们的内部氛围有什么变化吗?
钟怡然:DeepSeek 没让我们过年(笑)。我们在加快推理模型的节奏。而且我们要做出比 R1 更好、甚至要达到 o1 或 o3 相近水准的推理模型。
我们又选了一个比较激进的方案:它会是一个深度推理的原生多模态模型,这里面最难的点就在于,怎么去平衡文本能力和视觉理解能力,让两个能力都很强。目前实验结论还可以。
晚点:这次你有多大把握可以 work?
钟怡然:大概七八成。
晚点:什么时候会推出这个模型?
钟怡然:4 月到 5 月。现在所有的精力都是在提高模型上限上面,我们现在认为模型上限,比去维护产品更加重要。
晚点:你如何看待 DeepSeek 其实没有一个好用的产品,但它的影响力特别爆炸?
钟怡然:我个人认为,当然模型效果确实出色,这是它能出圈的基础。但另一方面,它的火爆也与许多其他因素相关。
我们无法去想这类偶发事件,而是想,如果我们有一项新技术,希望让更多人了解,该怎么做呢?最好的方法就是将其转化为产品。
晚点:所以你仍然认为,一个正常的技术公司,只靠技术本身,没有办法长时间有正向反馈和壁垒。
钟怡然:对。我们 2023 年时想做线性注意力,确实也用了一些 Lab(上海人工智能实验室)的资源去宣传。但我发现当时我跟所有人聊,都很难说服他们。他们会认为这个新架构模型只在小规模上验证过。
当时我就想,我怎么办?我只能去找一个愿意相信这个架构的人,把它放到产品里——证明一个新技术有说服力的最好方式就是把它放到产品里。
晚点:你自己在 AI 上的追求是什么?
钟怡然:我希望构建一种能真正自我学习、自我进化的模型。把人类看到、听到的所有信息作为输入后,它能自主学习不同模态之间的关系以及像文本处理这类技能,其实文本处理能力也是通过自监督学出来的。
如果要实现我的设想,首先需要构建文本模型,其次是多模态模型,第三步是探索如何让模型自主学习不同模态之间的关系。这个过程和人类学习的方式类似,人类从婴儿时期起也是这么学习的。
附:文中提到的主要工作的 GitHub 或 arxiv 链接:
MiniMax-01:
https://github.com/MiniMax-AI/MiniMax-01
Lightning Attention:
https://github.com/OpenNLPLab/lightning-attention
cosFormer:
https://github.com/OpenNLPLab/cosFormer
Mamba:
https://github.com/state-spaces/mamba
Jamba:
https://github.com/kyegomez/Jamba
题图来源:《电影美丽心灵》
相关推荐
3700次预训练找线性注意力非共识,MiniMax-01开发者讲述4年探索
输入长度是GPT-4o的32倍,国产开源大模型突破瓶颈,迎接智能体时代
MiniMax开年甩出一张王炸
大模型注意力简史:与两位AI研究者从DeepSeek、Kimi最新改进聊起
耶鲁团队揭示多头自注意力结构的上下文学习机制,证明梯度流算法的收敛性
晚点对话 MiniMax 闫俊杰:创业没有天选之子
如何训练你焦头烂额的大脑,重新找回注意力?
PE追求共识,VC追求非共识
对话晨兴资本程宇:寻找非共识的火箭
大模型时代下的技术变革:训练、负载、部署、效率、安全……都遇到了新挑战?
网址: 3700次预训练找线性注意力非共识,MiniMax-01开发者讲述4年探索 http://m.xishuta.com/newsview133545.html