DeepSeek开源的FlashMLA有什么优势?
2025年2月21日,DeepSeek宣布启动“Open Source Week”,计划在一周内开源5个代码库。本周一(2月24日)首次开源的代码库是 FlashMLA。
FlashMLA是什么?要理解它,我先跟你讲过故事:
从前,有个小镇,镇上有个神奇的算命先生。他能解答任何问题,但有个问题——他算得很慢。每次有人问问题,他都要花很长时间翻书、计算,让人等得心焦。
有一天,镇上来了个聪明的小伙子。
他看到算命先生的困境,就想了个办法:他把算命先生的书分成很多小块,还设计了一套快速查找的方法。这样一来,算命先生再也不用一页一页翻书了,回答问题的速度快了好多。
这个小伙子的发明,就像FlashMLA。
FlashMLA给AI模型设计了一套“快速查找系统”,让AI在回答问题时,不再像以前那样慢吞吞,所以,FlashMLA的出现,给AI装上了一双“风火轮”。
如果按照官方的说法:FlashMLA是一个专门为高性能GPU优化的“加速器”。
具体来说,FlashMLA是为NVIDIA最新的Hopper架构GPU(比如H800)量身定制的。它通过一系列优化技术,让AI模型在推理时,能够更高效地利用GPU的计算能力,从而大幅缩短响应时间。
那么,这个“加速器”到底有多厉害呢?三个重点:
第一,性能提升是实实在在的。
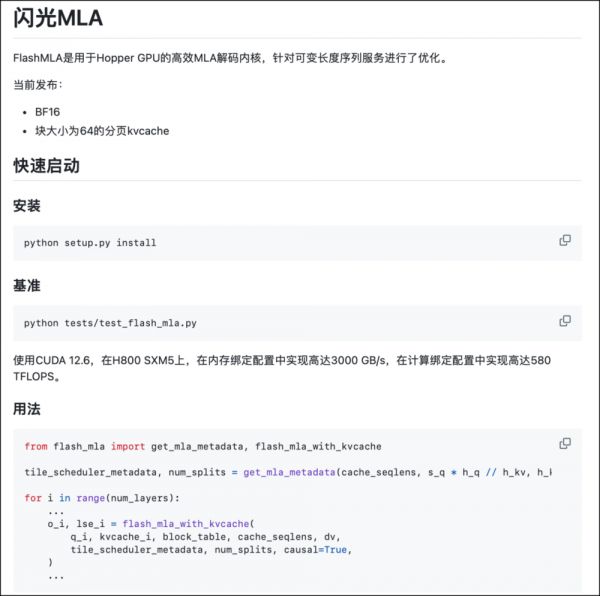
它能够将GPU的内存带宽提升到3000 GB/s,计算性能达到580 TFLOPS。这些数字,想必看起来很抽象,你可以理解成,它让原本就很强大的GPU变得更加“恐怖”。
如同一辆跑车,原本就已经很快了,但FlashMLA给它装上了更强劲的发动机,让它在赛道上瞬间就能把对手甩在身后。换句话说,它让AI模型的反应速度从“很快”变成了“瞬间”。
第二点是,它特别“省力”。
如何省力呢?要知道,传统AI模型在处理问题时,像一个新手司机,总喜欢把油门踩到底,不管用不用得上。
FlashMLA则像一个经验丰富的老司机,它知道什么时候该踩油门,什么时候该松一松。它通过一种聪明的“动态处理方式”,只在真正需要的时候才投入计算资源。
官方是这么说的:
FlashMLA采用了分页KV缓存(Paged KV Cache)技术,将缓存数据分成一个个小块(块大小为64),这样可以更精细地管理内存,减少显存碎片化。
同时,它还支持 BF16精度,这种精度格式在保证计算精度的同时,进一步提升了内存带宽的利用率。
所以,这种优化方式就像在交通拥堵时,只让真正需要通行的车辆上路,避免了不必要的资源浪费。说白了,就好比夏天来了,你只在要时打开空调,而不是一直让它开着。
第三个优点是:工业级实战设计。
什么是工业级实战设计?简单讲,不是理论技术,是已经在真实场景中经过严格测试和验证的成熟解决方案。
既然是成熟方案,就一定具备以下特点:首先,高可靠。FlashMLA能在高强度的业务场景中稳定运行,不会因为突发情况而崩溃。
其次,高性能。FlashMLA不仅跑得快,还能跑得久;易于部署和维护,像U盘一样,企业能快速将其接入现有系统,即插即用。
最后,它能适应各种复杂的业务场景,而且,在处理海量数据时,FlashMLA不会泄露任何敏感信息,所以,工业级实战设计意味着它不仅技术先进,而是减少试错成本的“真家伙”。
那么,这个FlashMLA灵感来自哪呢?
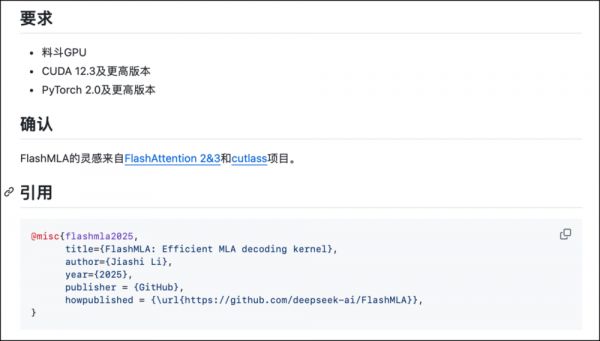
GitHub上提到两个项目,分别是:FlashAttention 2&3 和 Cutlass。我查了下,FlashAttention 是一个专注于高效实现注意力机制的项目,它通过优化内存访问和计算流程,显著提升Transformer模型的性能。
你可以把FlashAttention想象成一个超级高效的“指挥官”。它能指挥计算机里的各种资源,让它们协同工作,更快地完成复杂的任务。
就好比在一个工厂里,指挥官安排工人高效地完成每一个环节,从而提高整个工厂的生产效率。
而Cutlass项目是NVIDIA开发的一个高性能矩阵运算库,专注于优化CUDA上的矩阵乘法(GEMM)和相关计算。
你可以把它想象成一个“数学天才”,像在学校里,有些同学特别擅长心算,能够快速得出答案,Cutlass通过优化算法,让计算机能够更快地完成复杂的数学运算。
所以,FlashMLA在设计时,借鉴了这两个项目的优点。
它从FlashAttention那学到了如何高效地指挥资源,从Cutlass那,学到如何快速完成复杂的数学运算,二者一结合,它既懂指挥,又懂计算。
我认为,FlashMLA的开源,对企业和开发者很重要。
为什么?
一方面,商业领域,时间就是金钱。对于依赖AI技术的企业来说,更快的推理速度意味着更低的运营成本、更高的客户满意度,以及更强的市场竞争力。
另一方面,FlashMLA的开源,能让更多的企业和开发者能够免费使用这种先进的技术,从而推动整个行业的发展。
写到这,问题来了,如何使用呢?
硬件要求:FlashMLA需要NVIDIA Hopper架构的GPU(比如H800)才能使用;软件要求:需要CUDA(版本12.3及以上)和PyTorch(版本2.0及以上)。
然后,三步走:
1. 获取代码,GitHub地址是:https://github.com/deepseek-ai/FlashMLA。
2. 进入代码文件夹后,运行以下命令:python setup.py install;这一步像给FlashMLA装上必要的零件,让它能够正常工作。
最后,你可以通过运行一个简单的测试来检查FlashMLA是否安装成功。在代码文件夹中,运行以下命令:python tests/test_flash_mla.py
如果一切正常,你会看到测试结果,告诉你FlashMLA的性能表现如何。
总之,如果你是AI开发者,或者产品需要提升AI性能,FlashMLA绝对值得一试,它是一个难得的商业机会。我不是独立开发者,还在学习中。但第一时间把相关信息分享给你,希望能对你有帮助。
本文来自微信公众号:王智远,作者:王智远
相关推荐
DeepSeek开源的FlashMLA有什么优势?
DeepSeek什么来头,何以震动全球AI圈?
DeepSeek登顶140国榜首,免费开源的真相究竟是什么?
银行人有了新“上班搭子”,DeepSeek会给银行带来什么?
DeepSeek大模型专家交流
中国创新药离“DeepSeek时刻”有多远
大家对DeepSeek神话了
DeepSeek到底横扫了什么?比“争创新”更重要的,是“讲逻辑”
DeepSeek的崛起,其实并不意外
方舟健客全面接入deepseek开源大模型,引领互联网医疗新变革
网址: DeepSeek开源的FlashMLA有什么优势? http://m.xishuta.com/newsview133055.html
