AI芯片,再一次开战
本文来自微信公众号:电子工程世界 (ID:EEworldbbs),作者:付斌
IBM:在片上集成DPU,提升IO处理能力
Hot Chips上,IBM宣布推出针对AI时代的下一代企业计算产品,包括全新Telum II处理器和Spyre AI加速器,预计这两款芯片都将于2025年上市。
首先,是Telum II处理器。早在2021年,IBM就推出了第一代的Telum处理器,当时就采用了全新的核心构架,并针对AI加速优化,采用三星7nm制程技术,核心面积530mm²,225亿个晶体管,8核心16线程,主频超过5GHz。
这次推出的第二代的Telum,采用更先进的三星5nm HPP制程技术制造,核心面积为600mm²,430亿个晶体管,虽然像其前身一样是一个八核芯片,但在新芯片中,它们以更高的5.5GHz时钟速度运行。有10个36 MB的2级缓存,L3和L4分别增长到360 MB和2.88 GB,这意味着缓存大小增加了40%;内部集成全新I/O加速单元DPU,接在L2Cache上,而不是放在PCIe总线后面,提高了50%的I/O密度来优化数据处理。
在阿姆达尔定律和登纳德缩放比例定律双双失效的如今,处理器一直徘徊在5GHz,也成了一个分水岭。而这款产品则达到了5.5GHz,性能有了大幅度提升。
其次,是Spyre AI加速器,它采用基于三星5nm LPE制程技术,核心面积330mm²,260亿个晶体管,拥有32个计算核心,与Telum II整合的AI内核拥有类似构架,整体算力超过300TOPS,适用于低延迟和高吞吐量AI应用。每个计算核心拥有2MB缓存,拥有超过55%的有效TOPS利用率。内存方面,支持LPDDR5。
微软:也想逆天改命
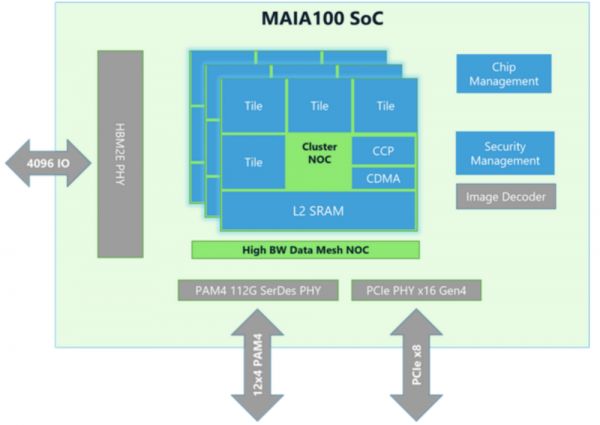
在Hot Chips上,Microsoft分享了Maia 100的规范,Maia 100是Microsoft第一代自定义AI加速器,专为Azure中部署的大规模AI工作负载而设计。Maia 100系统垂直集成以优化性能和降低成本,包括一个平台架构,该架构具有带有定制机架的定制服务器板和一个软件堆栈,旨在提高Azure OpenAI服务等服务上高级AI功能的性能和成本效率。
Maia 100加速器专为各种基于云的AI工作负载而构建。该芯片的尺寸为~820mm2,采用台积电的N5工艺和COWOS-S中介层技术。Maia 100的标线大小的SoC裸片配备大型片上SRAM,结合四个HBM2E裸片,可提供每秒1.8 TB的总带宽和64 GB的容量,以满足AI级数据处理要求。
Maia 100旨在支持高达700W的TDP,但配置为500W,可以提供高性能,同时根据其目标工作负载高效管理电源。
不难猜想,主要应该是应用于OpenAI的推理业务,软件方面做得很不错,能够用一行代码对Maia执行PyTorch模型,高密部署、标准以太网融合ScaleUP、ScaleOut都不错,但用RoCE就需要配备额外的Tile控制器,和Intel Gaudi3要一个中断管理器一样的缺点。
FuriosaAI:低调宣布全新AI芯片
Hot Chips上,FuriosaAI推出全新的AI加速器RNGD,专为数据中心的高性能、高效大型语言模型(LLM)和多模态模型推理而设计。
RNGD具有150W的TDP、新颖的芯片架构和HBM3等高级内存技术,针对要求苛刻的LLM和多模态模型的推理进行了优化。
Furiosa在收到台积电代工的第一颗芯片三周后,提交了第一个MLPerf基准测试结果。然后,使用编译器增强功能,在6个月后的下一次MLPerf提交中实现了113%的性能提升。总之,就是榨干了芯片每一滴性能。
在运行GPT-J 6B模型时,单个RNGD每秒生成大约12个查询,随着未来几周和几个月内改进软件堆栈,预计这个数字会增加。
从目前的性能来看,可以在很低的TDP下实现不错的性能,还是很强大的。不过,到目前为止,Furiosa一直刻意保持低调,因为他们知道该行业不需要对尚不存在的事物进行更多的炒作和大胆承诺。
英伟达:Blackwell确实有良率问题
月初,关于Blackwell可能因设计挑战而推迟发布的传闻,一度在业界引起轩然大波。而在最近,英伟达承认其即将推出的基于Blackwell的产品良率低,这要求该公司重新设计B200处理器的某些层以提高良率。英伟达表示将在2024年第四季度提高Blackwell的产量,并将在今年最后一个季度出货价值数十亿美元的Blackwell GPU。“我们对Blackwell GPU掩码进行了更改以提高生产良率。”英伟达的一份声明中写道。
Hot Chips期间,英伟达也展示了Blackwell的更多细节。B200 GPU芯片采用台积电定制的4nm工艺制造,集成2080亿个晶体管;NVLink-C2C技术被用于Blackwell架构中的芯片级整合;为实现GPU间无缝通信,NVIDIA推出NVSwitch,使得服务器内的每一个GPU都能以1.8 TB/sec的速度与其他GPU进行通信,使得Blackwell平台能够支持更大规模的语言模型,如GPT-MoE-1.8T等,满足实时推理和训练的需求;使用NVIDIA高带宽接口(NV-HBI)在两个GPU芯片之间提供高达10TB/s的双向带宽连接;此外,NVIDIA在Blackwell平台上原生支持FP4(四精度浮点数)和FP6(六精度浮点数)格式。
性能方面,官方给出的性能方面一个参考数据:Llama 3.1 700亿参数大模型的AI推理性能GB200对比H200提高了1.5倍。不过,这个牺牲功耗来实现的。
Blackwell B200单颗芯片功耗高达1000W,一颗Grace CPU和两颗Blackwell GPU组成的超级芯片GB200更是达到了可怖的2700W。而过去,Hopper的H100、H200 GPU功耗都是700W,H20则只有400W,Grace+Hopper则是1000W。比较下来,GB200的功耗比上一代GH200大幅提升了1.7倍,但性能好像是没有跟上,具体还需要英伟达的进一步披露。
英特尔:布局很前沿的AI技术
大家都知道,最近英特尔有点难受,很多产品也没有赶上好的时间节点,还适逢13、14代酷睿大争议。不过英特尔走得还是很稳固的,一直在布局很远的技术。
Hot Chips上,英特尔发表四篇技术论文,重点介绍英特尔至强6系统集成芯片、Lunar Lake客户端处理器、英特尔Gaudi 3 AI加速器以及OCI(光学计算互连)芯粒。
英特尔至强系列一直在强调AI性能,至强6则会成为英特尔迄今为止针对边缘场景优化程度最高的处理器,属于是英特尔疯狂叠buff了,包括:Intel 4制程工艺、新的媒体加速功能、高级矢量扩展和高级矩阵扩展(AMX)可提高推理性能、英特尔快速辅助技术(QAT)可实现能效更高的网络和存储性能、英特尔vRAN Boost可降低虚拟化RAN的功耗、支持英特尔Tiber边缘平台。总之,就是疯狂堆料,自带超强AI推理性能。
Lunar Lake则持续布局AI PC。其性能也有大幅度提升,包括新的性能核(P核)和能效核(E核),使SoC功耗相比上一代最多降低40%。新的神经网络处理单元(NPU)速度提升4倍。全新的Xe2图形处理单元核心将游戏和图形性能提高了1.5倍。
Guadi 3专门针对AI推理,比英伟达更便宜更强大,更多细节还有待披露。光学计算互连(OCI)芯粒则用于XPU之间的连接,传输速度高达4 Tbps。
AMD:英伟达最大对手
上周,AMD刚刚下重金,收购了ZT Systems公司,后者正是微软Azure MI300X平台的制造商,引发了行业关注。
作为英伟达GPU最大竞争对手,AMD Instinct MI300X是目前除NVIDIA GPU之外,唯一在人工智能行业达到年运行率数十亿美元的GPU。
Hot Chips上,AMD展示了Instinct MI300X的一些细节。AMD Instinct MI300X的架构相当复杂,集成了192MB的高带宽内存三代(HBM3)、用于计算的小芯片(chiplets)以及其他组件。不仅有192GB的HBM3,还有256MB的Infinity缓存,以及8个4MB的L2缓存等高级特性。MI300X支持单一分区运行,也可在不同的内存和计算分区模式下运行。
Instinct MI300X与NVIDIA H100平台相比非常有竞争力,并且使用预计将在第四季度发布的AMD最新的服务器CPU EPYC“Turin”,它将拥有进一步的收益。

MI300X是AMD在2023年的设计,它正与H100竞争,预计不久的将来,双方都将被具有更高内存容量的版本所取代。尽管如此,AMD已在数十亿美元级别的产品线中稳固了其作为AI GPU市场的第二名位置,仅次于英伟达。更多未来的产品信息,可能要等到第四季度才会揭晓。
Cerebras:推理1800 token/秒,全球最快
Cerebras是一家很有意思的公司,这家公司不追求小型化,只追求大——晶圆有多大,我就造多大芯片,也就是晶圆级芯片。这家公司也在Hot Chips正式踏足AI推理领域。
曾造出世界最大芯片公司Cerebras,就在Hot chips上发布了全球最快的AI推理架构——Cerebras Inference。
按照传统的认知,在现代生成式AI工作负载中,推理性能通常是内存带宽的函数,而不是计算函数。因此,在高带宽内存(HBM)中穿梭位的速度越快,模型生成响应的速度就越快。
不过,Cerebra打破了这种思维,他们和Groq一样,选用了SRAM,基于之前宣布的WSE-3处理器,在上面封装了一个44GB的SRAM,实现了21 PBps的带宽。对比起来,单个Nvidia H200的HBM3e仅拥有4.8TBps的带宽。

其在运行Llama3.1 8B时,它能以1800 token/s的速率吐出文字。以往,微调版Llama3.1 8B推理速度为90 token/s。而现在,直接从90 token/s跃升到1800 token/s,这种生成的速度人眼都跟不上了。
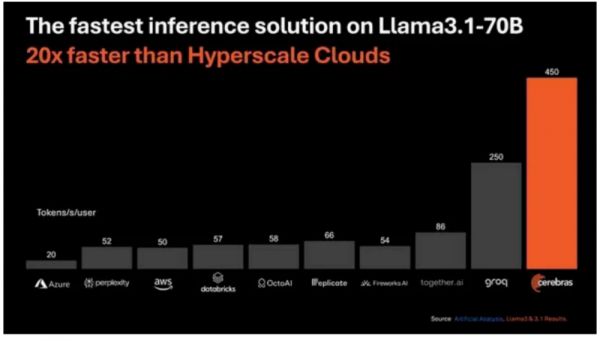
它的算力在大参数量下表现也非常强劲:当运行分布在四个CS-3加速器上的700亿参数版本Llama 3.1(70B)时,每秒可处理450个token。相比之下,H100最佳速度是每秒128个token。
值得一提的是,Cerebras并没有因为提高LLM速度,而损失精度。测试中,使用Llama3.1模型皆是采用了Meta原始16位权重,以便确保响应高精度。
参考文献
[1]https://www.theregister.com/2024/08/27/cerebras_ai_inference/
[2]https://www.theregister.com/2024/08/27/ibm_telum_ii_mainframes/
[3]https://mp.weixin.qq.com/s/GHJFcDUSwXw0BVGZk4smDw
[4]https://mp.weixin.qq.com/s/lSWz2b1ttrdblO_mvRMUGg
[5]https://mp.weixin.qq.com/s/9pfW8XnSZ83BnKjL9xM-OQ
[6]https://techcommunity.microsoft.com/t5/azure-infrastructure-blog/inside-maia-100-revolutionizing-ai-workloads-with-microsoft-s/ba-p/4229118
[7]https://mp.weixin.qq.com/s/EAfWMqiSkunW3MxOYuJyyQ
[8]https://www.techpowerup.com/325975/furiosaai-unveils-rngd-power-efficient-ai-processor-at-hot-chips-2024
相关推荐
AI芯片,再一次开战
信息流、搜索引擎、内容全面开战,百度与头条的持久战
AI芯片帝国开战,Altman密会美国政府求助,孙正义急筹千亿美元豪赌
芯片巨头开战2纳米
高通与联发科多线开战
AI数据中心将接棒芯片成为市场追逐的热点?
再一次捅破天 华为Mate60又升级了
联邦快递要跟亚马逊全面开战(下)
AMD发起AI芯片挑战,但英伟达依然独孤求败
网易与华纳兄弟合作:开发新手游《指环王:开战》
网址: AI芯片,再一次开战 http://m.xishuta.com/newsview124507.html