AI芯片对决:英特尔GAUDI与英伟达GPU

说起AI系统,我们已经不再以相互割裂的方式单独计算加速器和基础主板的标价,而开始将主板与一大堆加速器视为统一的共享计算复合体。
但在最近于中国台湾举行的Computex IT大会上,迫切希望在AI训练与推理方面有所表现的英特尔做出了一项英伟达和AMD都未曾做过的尝试:为其当下及之前几代AI加速器单独标价。但请大家先别太兴奋,估计英伟达、AMD乃至其他AI加速器与系统初创公司短时间内并不会迅速跟进。
但Gaudi 2与Gaudi 3加速器定价的披露,外加部分基准测试结果以及这些设备的峰值馈送与处理速度,确实让我们获得了对几位竞争对手间真实实力的分析空间。
英特尔公开具体价格的原因并不难理解。芯片巨头希望自家AI芯片能在市场上有所建树,从而分担其计划在2025年底交付的“Falcon Shores”GPU以及2026年上市的“Falcon Shores 2”GPU的研发成本,因此他们必须展现出良好的性价比与有竞争力的性能水平。
这种自我证明之所以重要,还因为Gaudi 3芯片已经从今年4月开始出货,也是英特尔2019年12月斥资20亿美元收购Habana Labs、进而拿下Gaudi系列加速器产品线之后,推出的最新一代方案。
大家可能都听说过发热量和制造成本都相当夸张的“Ponte Vecchio”Max系列GPU,其在阿贡国家实验室的“Aurora”超级计算机当中充当核心,也被其他几个项目所采用。但受这两大劣势因素的影响,该系列GPU在这些交易之后几乎立即被封存,英特尔也着实希望从一再推迟的Ponte Vecchio平稳过渡到有望于明年年底准时推出的Falcon Shores。
根据英特尔方面在2023年6月透露的消息,Falcon Shores芯片将采用Gaudi系列的大规模并行以太网结构及矩阵数学单元,并将其与当初为Ponte Vecchio创建的Xe GPU引擎相结合。如此一来,Falcon Shores就能同时进行64位浮点处理以及矩阵数学处理。Ponte Vecchio并不具备矩阵处理能力,而仅支持向量处理,这是为了满足Argonne提出的FP64算力需求所设计。这当然很好,却也代表着Ponte Vecchio可能并不太适合AI工作负载,因此限制了其市场吸引力。有鉴于此,英特尔才决定将Gaudi和Xe计算单元合并为统一的Falcon Shores引擎。
我们对Falcon Shores了解不多,但可以肯定的是其运行功率将达到1500瓦,比预计于明年初批量出货的顶级“Blackwell”B200 GPU的功耗和发热量高出25%——后者的额定功率为1200瓦,能够以FP4精度提供20千万亿次算力。Falcon Shores的耗电量比Blackwell高25%,所以假设其浮点精度水平和芯片制程工艺大致相当,那么其性能最好也要比Blackwell高出25%。而如果想要真正形成优势,英特尔最好能采用Intel 18A制程工艺(预计于2025年正式投产)来制造Falcon Shores,并且能够在浮点性能方面更进一步。再往远说,Falcon Shores 2最好能采用尺寸更小的Intel 14A制程工艺,预计将在2026年投入生产。
英特尔早就应该挽救自己在代工和芯片设计领域犯下的一个个致命错误了。台积电的创新步伐坚定且无情,英伟达的GPU路线图也是滚滚向前。2025年的“Blackwell Ultra”将带来HBM内存容量提升与GPU算力提升,2026年将推出“Rubin”GPU,而后续产品“Rubin Ultra”则将在2027年与大家见面。
与此同时,英特尔于去年10月表示,其Guaid加速器销售渠道总价值达20亿美元;芯片巨头又在今年4月补充称,预计2024年Gaudi加速器的销售额可达到5亿美元。与AMD今年年内40亿美元的GPU预期销售额(我们认为这个数字被低估了,最终很可能达到50亿美元)以及英伟达今年在数据中心计算领域可能拿下的1000亿美元甚至更高数字相比(这里仅计算数据中心GPU,不涉及网络和DPU业务),英特尔的这点成绩算不了什么。但考虑到这总值20亿美元的渠道未来要成为Falcon Shores和Falcon Shores 2的消费出口,英特尔就表现得非常积极。
因此,英特尔在Computex简报会上公布了产品的定价与基准测试性能,以期展示Gaudi 3与当前“Hopper”H100 GPU的直接比较结果。
英特尔的第一项比较面向AI训练,选择的是拥有1750亿参数的GPT-3大语言模型和拥有700亿参数的Llama 2模型:

以上列出的GPT-3数据基于MLPerf基准测试得出,而Llama 2数据则基于英伟达发布的H100结果与英特尔的估算。此番GPT基准测试运行在拥有8192个加速器的集群之上——其中英特尔Gaudi 3配备128 GB HBM,而英伟达H100采用80 GB HBM。Llama 2测试则对应仅有64个加速器的设备。
在推理方面,英特尔进行了两轮比较:第一轮是对拥有128 GB HBM的Gaudi 3与拥有80 GB HBM的H100之间开展了一系列测试;第二轮则是将同样128 GB HBM版Gaudi 3与拥有141 GB HBM的H200进行了比较。英伟达方面的官方性能数据发布在此(https://nvidia.github.io/TensorRT-LLM/performance/perf-overview.html),适用于采用TensorRT推理层的各类模型。而英特尔Gaudi 3的数据则主要基于预测。
首轮比较,H100 80 GB版对阵Gaudi 3 128 GB版:
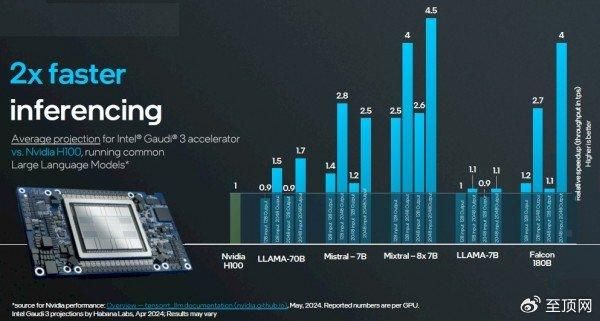
次轮比较,141 GB版H200对阵128 GB版Gaudi 3:
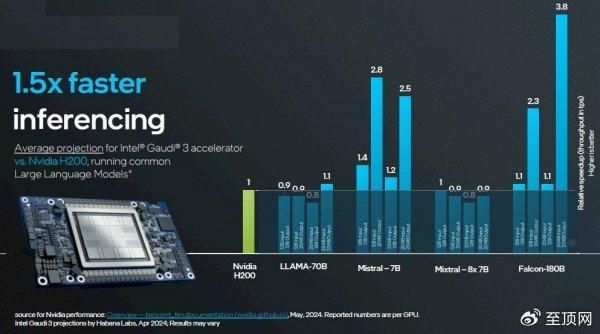
面对当前热辣滚烫的AI浪潮,我们先要做出两点提醒。首先,用户们最关心的就是如何挑选最具性价比的AI加速器。其次,只要相关产品能够以合理的精度组合进行矩阵数学运算,而且可以运行PyTorch框架以及Llama 2或者Llama 3模型,那么面对英伟达GPU的严重供应不足,这些产品就肯定有人愿意买。
但英特尔并不满足于此,而是想打造出真正拥有客户吸引力的新产品:

在训练方面,英特尔比较了使用Llama 2 7B、Llama 2 13 B以及GPT-3 175B测试时英伟达GPU的真实平均性能,并将结果与英特尔自家Gaudi 3的估算值进行了比较。在推理方面,英特尔则选取了Llama 2 7B、Llama 2 70B以及Falcon 180B的真实英伟达平均数据,同样与Gaudi 3的估算值进行比较。
只要对这些性能/美元比率以及图表中所示的相对性能数据进行逆向计算,就能发现英特尔假定英伟达H100加速器的成本为2.35万美元;而对Gaudi 3 UBB进行同样的简单计算,会发现其成本为15625美元。
跟英特尔不同,我们会观察一段时间之内的趋势与更广泛的峰值理论性能,借此找出每单元对应算力与单位性能对应的售价(二者互逆)。为此,我们整理出一份小表格,将英伟达“Ampere”A100、H100以及Blackwell B100同英特尔Gaudi 2与Gaudi 3加速器进行了比较。双方均采用带有8个加速器的基板配置,具体如下:
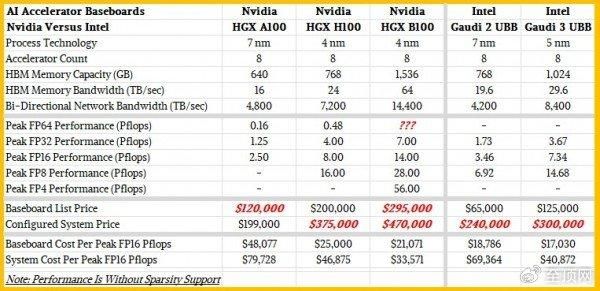
请注意,这些数字是八路主板的数字,而非单设备性能数字。而目前大多数AI客户仍然选择单设备作为基本算力单元。
当然,我们也很清楚在对设备及其基板集群的计算、内存和网络进行性能评估时,每种AI模型都有自己的偏好与特点,所以具体性能肯定会因工作负载和环境设置而有所浮动。
我们还喜欢从系统的角度来思考,比如估算使用这些基板并添加双插槽x86服务器组合的成本。这套服务器组合拥有2 TB主内存、400 Gb/秒InfiniBand网卡、两块1.9 TB NVM-Express闪存驱动器(用于操作系统)和八块3.84 TB NVM-Express闪存驱动器(用于将本地数据传送至UBB)。
我们的表格展示出这五种硬件的相对性价比。另外需要补充几点,我们选择了最适合作为性能比较基准的FP16精度来衡量这些设备,而且设备上没有激活任何稀疏性支持,因为并非所有矩阵和算法都能利用稀疏性实现优化。如果大家想要亲自计算,也可以选择更低的计算精度。
根据黄仁勋在去年主题演讲中的介绍,HGX H100基板的售价为20万美元,这个数字也与我们在市场上看到的完整系统定价相一致。英特尔则告诉我们,带有8个Gaudi 3加速器的主板售价为12.5万美元。H100主板的额定算力为8千万亿次,而Gaudi 3主板的额定性能为7.34千万亿次,均是在FP16精度且不激活稀疏性支持的情况下测得。也就是说H100复合体的每千万亿次算力成本为2.5万美元,而Gaudi 3的每千万亿次成本为17030美元——性价比高出32%,这一轮英特尔胜出。
现在,如果大家打算构建一套系统并添加更多昂贵的CPU、主内存、网络接口卡和本地存储,那么这种性价比差距就会开始缩小。按照我们之前概述方式配置的英伟达H100系统总价格可能在37.5万美元上下,折合每千万亿次算力46875美元。具有相同配置的Gaudi 3系统价格则在30万美元左右,折合每千万亿次算力成本为40872美元——性价比仅比英伟达系统高出12.8%。
再加上相同的交换、支持、供电、环境以及管理成本,二者之间的差距还将进一步缩小。
所以如果大家对Gaudi 3抱有期待,不妨从系统层面考虑其性价比,并在自己的模型和应用场景内亲自跑几轮基准测试看看。
而最后一项值得探讨的因素,就是英特尔公布的Gaudi 3收入和营销渠道了。如果认真计算一下,就会发现5亿美元只对应4000块基板和3.2万个Gaudi 3加速器。哪怕抛开仅理论上存在、实际上难以真正兑现的潜在需求空间,把Gaudi渠道中余下的这15亿美元全都算在Gaudi 3设备的销售额头上,那对应的也就仅仅是1.2万块基板和总计9.6万个加速器的业务机会。相比之下,英伟达今年年内将售出数百万张数据中心GPU。虽然不是每张GPU都是H100、H200、B100和B200这种高端乃至旗舰级产品,但必须承认,这些加速器贡献的销售额和利润都不会低。
发布于:北京
相关推荐
AI芯片对决:英特尔GAUDI与英伟达GPU
AI“芯”突围:英特尔Gaudi 3硬刚英伟达
成本降低一半,算力提升50%,英特尔新一代Ai芯片Gaudi 3发布
英伟达 VS 英特尔 VS AMD:新的AI混战
AI芯片大战背后:英特尔对英伟达虎视眈眈,国内芯片公司蠢蠢欲动
CES现场芯片巨头上演开年大战:AMD、英特尔、英伟达、高通展开对决
AI芯片、晶圆代工双战线反击,英特尔能否王者归来?
谁能替代英伟达?
下一代AI芯片,拼什么?
英特尔披露5nm“中国特供版”AI 芯片,性能或暴降92%,最快6月推出|硅基世界
网址: AI芯片对决:英特尔GAUDI与英伟达GPU http://m.xishuta.com/newsview120696.html