苹果一次性开源8个大模型,为WWDC做准备?
OpenELM是Apple苹果公司最新推出的语言模型系列,这次一共开源了8个模型,包括OpenELM-270M、OpenELM450M、OpenELM-1_1B和OpenELM-3B的预训练版和指令微调版。
OpenELM 采用了decoder-only的架构,并遵循最新的大语言模型(LLM)的设计,包括:
在任何全连接层中不使用可学习的偏置参数
使用RMSNorm进行预归一化,同时使用旋转位置嵌入(ROPE)来编码位置信息
使用分组查询注意力(GQA)代替多头注意力(MHA)
将前馈网络(FFN)替换为SwiGLU FFN
使用Flash Attention来计算缩放点积注意力
使用与LLama相同的分词器
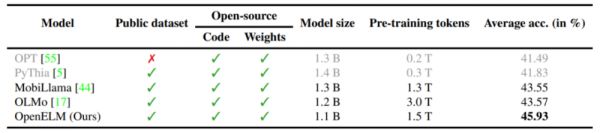
▲图.OpenELM与开源LLM。OpenELM比最近的开放LLM OLMo的性能高出2.36%,同时需要的预训练令牌减少了2倍。
研究人员提到,现有的大型语言模型在模型的每个Transformer层中使用相同的配置,导致参数在各层之间均匀分布。
而OpenELM中的每个Transformer层具有不同的配置(例如,注意力头数量和前馈网络维度),导致模型的每个层中参数数量不同。这使得OpenELM能够更好地利用可用的参数以实现更高的准确性。
OpenELM采用按层分配参数的策略,有效提升了Transformer模型各层的参数配置效率,显著提高模型精度。例如,在大约十亿参数的预算下,OpenELM的准确率较OLMo提升了2.36%,且预训练所需的Token数量减少了一半。
为了实现Transformer层中参数的非均匀分配,研究人员调整了每个Transformer层中注意力头的数量和FFN维度调整系数。
假设具有均匀参数分配的标准Transformer模型有N个Transformer层,每层输入的维度为dmodel。MHA有nh个头,每个头的维度为dh=dmodel/nh。另外,FFN的隐藏维度为dFFN=m·dmodel,其中m是FFN隐藏层维度的调整系数。
引入参数α和β来缩放nh和m。对于第层,和计算如下:
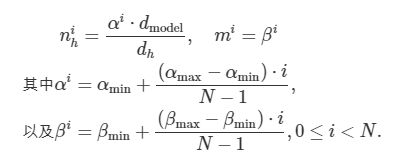
在这里,αmin和αmax是超参数,用于调整注意力头的数量。类似地,βmin和βmax被用于改变FFN层的宽度。因此,使用α和β来改变标准Transformer层的配置会导致模型中参数的非均匀分配。需要注意的是,设置αmin=αmax=1.0和mi=m时则对应了标准均匀的Transformer模型。
可靠但保守的OpenELM?
对于预训练,苹果使用的是公开数据集,如RefinedWeb、PILE、RedPajama和Dolma v1.6,总共大约包含1.8万亿个token。
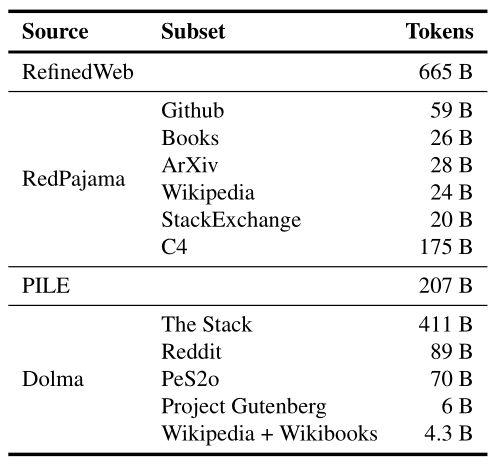
从数据上看,确实没有什么惊喜的感觉,因为既没有新的数据集发布,在规模上也没有创新,中规中矩。
对于模型的指令调优,指令调优(Instruction Tuning)和参数高效微调(Parameter-efficient Fine-tuning,PEFT)。
对于指令调优,使用了经过清理的 UltraFeedback 数据集的变种,该数据集包含了60,000个用于指令调优的提示。作者使用 Alignment Handbook 库进行指令调优。在优化过程中,他们使用了统计拒绝抽样方法或直接偏好优化方法。结果显示,指令调优能够在不同的评估框架中将 OpenELM 的平均准确率提高1-2%。
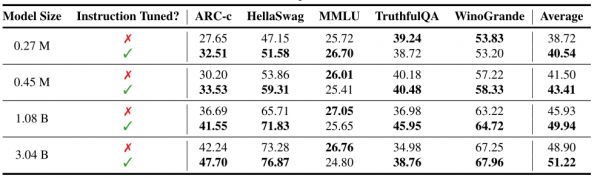
同时,在 CommonSense 推理训练和评估设置中使用了包含8个多项选择数据集、共计170000的训练样本,用于进行参数高效微调研究。研究中使用了LoRA和DoRA等方法,将它们与OpenELM集成,并使用8个NVIDIA H100 GPU进行三轮微调。但是从结果上看,LoRA和DoRA都表现出相当的性能。
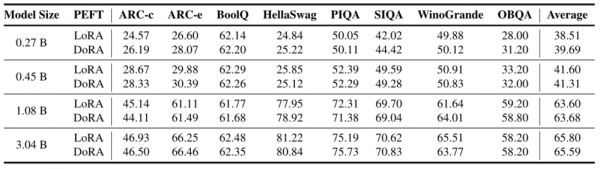
研究人员将OpenELM与PyThia、Cerebras-GPT、TinyLlama、OpenLM、MobiLlama和OLMo等模型进行了比较。在相似的模型大小下,OpenELM在ARC、BoolQ、HellaSwag、PIQA、SciQ和WinoGrande等主流的任务测试中的多数任务上展现出了更高的准确度。尤其是,与OLMo模型相比,OpenELM在参数数量和预训练数据更少的情况下,准确率依然更高。
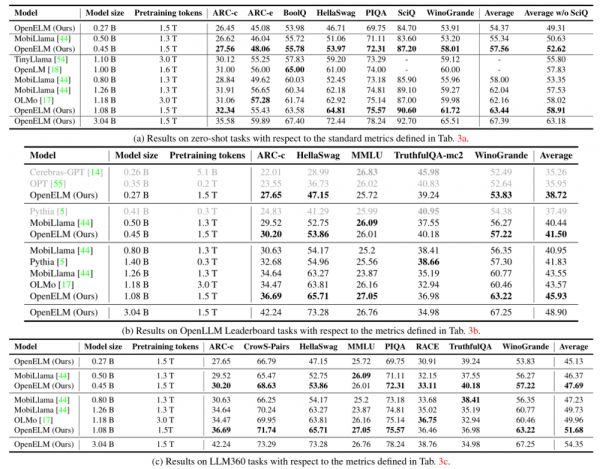
值得注意的是,研究人员还发现尽管OpenELM的准确性比OLMo更高,但它却比OLMo更慢。同时,OpenELM的处理时间中有相当大一部分是由于未经优化的RMSNorm所导致的。
因此研究人员通过用Apex的RMSNorm替换未经优化的RMSNorm,观察到OpenELM的吞吐量明显增加。
然而,与使用优化的LayerNorm的模型相比,OpenELM仍存在相当大的性能差距,部分原因是OpenELM有113个RMSNorm层,而OLMo只有33个LayerNorm层。并且Apex的RMSNorm并不针对小输入进行优化。
当将OLMo中的LayerNorm替换为RMSNorm后,生成吞吐量则出现了显著下降。
不管怎么说,通篇看下来,OpenELM的实验也并不是那么有诚意,毕竟Phi-3系列作为小规模LLM中的出色工作,苹果不拿来对比一下确实不够意思。
而且,OpenELM并未在论文中提到相关的部署测试,相比之下,Phi-3-mini已经在iPhone 14上实现本地运行并完全离线,实现每秒超过12 token的生成效率。这一波啊,属实是倒反天罡了。
升级的 CVNets:支持更广泛的AI任务
此次随OpenELM开源的还有深度神经网络工具包CoreNet。
CoreNet基于苹果公司在去年开源的一个计算机视觉工具包CVNets拓展,涵盖计算机视觉之外更广泛的应用,允许研究人员和工程师为各种任务训练标准和新颖的小型和大型模型,包括基础模型(例如 CLIP 和 LLM)、对象分类、对象检测和语义分割。
目前 CoreNet 已经支持了下面的工作:
OpenELM:具有开源训练和推理框架的高效语言模型系列
CatLIP:在 Web-scale Image-Text DataCLIP 上以 2.7 倍的预训练速度实现 CLIP 级视觉识别准确率
Reinforce Data, Multiply Impact:通过数据集强化提高模型准确性和稳健性
CLIP meets Model Zoo Experts:视觉增强的伪监督
FastVit:使用结构重参数化的快速混合视觉Transformer
Bytes Are All You Need: Transformers 直接操作的文件字节
MobileOne:改进的 One millisecond Mobile Backbone
RangeAugment:Efficient Online Augmentation with Range Learning
MobileViTv2:Separable Self-attention for Mobile Vision Transformers
CVNets:高性能计算机视觉库,ACM MM'22
MobileViT:轻量级、通用且适合移动设备的 Vision Transformer,ICLR'22
网友表示:
似乎可以将CoreNet中的模型导出为MLX可以运行的格式。与PyTorch相比,CLIP等模型实现了60%的加速(小型号的优势最大)。这可能表明他们消除了PyTorch MPS所遭受的一些驱动延迟。我不禁觉得这次发布的时机与即将到来的苹果发布会有关。
参考资料:[1]https://arxiv.org/pdf/2404.14619.pdf[2]https://github.com/apple/corenet[3]https://huggingface.co/apple/OpenELM
本文来自微信公众号:夕小瑶科技说(ID:xixiaoyaoQAQ),作者:任同学
相关推荐
最前线 | 27名中国学生获苹果学生奖学金,苹果开始为WWDC造势
WWDC 2019 前瞻:独立的苹果表,就是手腕上的小手机
观察+ | 苹果离“服务公司”有点远,WWDC还是为了构筑硬件的护城河
苹果WWDC 2021明晨开幕:第二次在线举办,五大系统将迎来升级
苹果:将于6月7日至11日线上举办WWDC大会
黄铁军:全球可能只需要三个大模型生态
办了一场“史上最无聊WWDC”,苹果的用意是什么?
苹果这届WWDC:变化不小,惊喜不多
650亿参数大模型预训练方案开源可商用,LLaMA训练加速38%,来自明星开源项目
焦点分析 | 没有One More Thing的WWDC,隐藏苹果“万物互联”的野心
网址: 苹果一次性开源8个大模型,为WWDC做准备? http://m.xishuta.com/newsview116457.html