科学家研发自动驾驶新模块,让自动驾驶场景理解更接近人类认知
近日,清华大学硕士生徐冬阳和所在团队,为了助力自动驾驶技术的进一步发展,他们提出一款名为 LVAFusion 的模块,旨在更高效、更准确地融合多模态信息。

自动驾驶在路上应该具备学习优秀人类驾驶员的能力,因为人类在面对多数场景的时候,可以迅速地定位在关键区域。
为了提高端到端自动驾驶模型的可解释性,该团队首次引入人类驾驶员的注意力机制。
通过预测当前上下文中的驾驶员注意区域,他们将其作为一个掩码来调整原始图像的权重,从而使自动驾驶车辆能够像经验丰富的人类驾驶员一样,具备有效定位和预测潜在风险因素的能力。
预测驾驶员视觉注视区域的引入,不仅为下游决策任务提供更具细粒度的感知特征,从而可以更大程度地保证安全。而且,也让场景理解过程更加接近人类认知,从而能够提高可解释性。
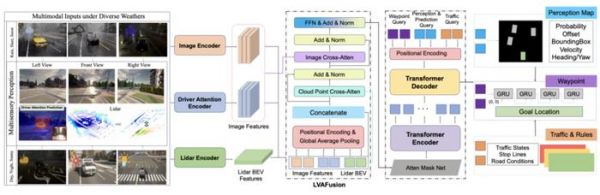 (来源:arXiv)
(来源:arXiv)就潜在应用来说:
其一,本次开发的 LVAfusion 模块能被用于配有激光雷达的车上,有望提高多模态大模型的感知融合能力。
其二,本次模型可以和现有多模态大模型结合。
比如,驾驶员注意力机制可以实时输出,让乘客实时观察当前大模型所认为权重较大的板块。
如果乘客认为不合理,可以语音告诉端到端模型,从而实现自动调节,进而实现持续学习和不断优化。

端到端自动驾驶好在哪里?
据介绍,自动驾驶包括环境感知、定位、预测、决策、规划及车辆控制等关键环节,通过协调这些模块可以对周围环境进行实时感知和安全导航。
然而,这种系统架构不但代码量巨大、后处理逻辑复杂、后期维护成本高。
而且在实际应用过程中容易出现误差累积的现象,比如前方突然出现行人,由于感知模块的漏检,下游的预测决策模块没有行人的信息输入,可能导致危险的发生。
而端到端自动驾驶则有望解决这个问题。端到端自动驾驶,是指使用深度学习模型直接从原始输入数据(如摄像头图像,激光雷达点云),到控制命令(如方向盘转角、油门和刹车)的转换过程。
该方法试图简化传统的多模块自动驾驶系统,将整个驾驶任务看作是一个从感知到行为的映射问题。
端到端学习的关键优势在于它可以降低系统的复杂性,并有潜力提高泛化能力,因为模型可以被训练来直接处理多种不同的驾驶情况。
并且,多模态端到端自动驾驶通过整合来自摄像头、激光雷达和雷达等多种传感器的数据,有望提高系统对复杂环境的理解和反应能力,增强决策的准确性和鲁棒性,从而提升自动驾驶车辆的安全性和可靠性。
然而,端到端自动驾驶基于黑盒化的深度学习模型,因此如何提高模型的驾驶性能、以及提高模型的可解释性,是一个急需解决的问题和痛点。
现有的大量方法都是端到端自动驾驶,徐冬阳和所在团队详细分析模型结构之后发现,此前人们并没有很好地利用多模态信息。
摄像头具有丰富的语义信息,但是缺乏深度信息。激光雷达可以提供很好的距离信息。因此,二者具有很好的互补特性。
但是,现有端到端学习方法大部分采用骨干网络分别提取模态信息之后,在高维空间里面进行拼接,或采用 Transformer 针对多模态信息进行融合。
其中,查询 Query 是随机初始化的,这个过程可能导致在采用注意力机制进行融合的过程中,无法利用埋藏在多模态特征中的先验知识。
进而可能会导致跨多种模态的同一个关键对象的错位,最终导致模型学习的收敛速度变慢和次优。
 中关村的雪天冬夜里,敲着代码做实验
中关村的雪天冬夜里,敲着代码做实验研究中,随着徐冬阳专业技能的积累、以及端到端自动驾驶的发展,在阅读文献时他发现了端到端领域仍然存在一些不足。
比如,没有充分探究是否融合了多模态信息,如何在保证精度的前提下提高模型的可解释性。一番研究之后,徐冬阳选择了端到端自动驾驶作为研究课题。
端到端自动驾驶是一个很大的系统,包括感知、跟踪、预测、决策、规划、控制等多个模块。因此,要设计一个可以有效串通上述模块的方法。
确定好方法之后,则需要采集大量的数据。因为端到端模型都是基于深度学习,因此需要大量数据进行训练。
还得确定模型需要什么输入和输出,以及去自动驾驶仿真平台 Carla 采集多种天气、多种工况之下的数据,同时还要检查数据的完整性。
完成数据采集之后,则要分析模型在结构设计上,能否对本次任务起到帮助。
实验中,在导入预训练权重的时候,徐冬阳把权重导错了一个。但是,由于经过了权重匹配,因此系统并没有报错,然而跑出来的实验结果总是不尽人意。
进行大量的模型调试之后,也依旧没有找到问题所在。一天晚上徐冬阳在中关村散步的时候,天上飘着大雪,他忽然想到自己还没有查看训练代码,会不会是训练过程的问题呢?
于是,他立马跑回电脑旁,看了一下训练过程,最终确定问题出在预训练权重导入上。
调整之后,实验结果非常符合预期。“这种发现带来的不仅是对于问题的理解,更有一种深刻的满足感和成就感。”徐冬阳说。
而由于训练时间比较长,徐冬阳每天晚上都会将多个任务提交到训练集群上。有一天晚上由于交的实验较多,有些任务由于优先级的原因被停了。
第二天来看的时候,他发现少了一些实验结果,于是只得再次仔细分析结果,并将缺失的实验重新提交。
图 | 相关论文(来源:arXiv)
后续,课题组会围绕进一步优化模型、拓展应用场景、提高系统鲁棒性和安全性开展。
具体来说:
首先,要深化多模态融合技术。
继续探索和开发更加高效的算法,借此改进不同传感器数据之间的融合方式。比如,采用图网络针对不同模态进行匹配,而且尤其要关注在处理高动态和复杂环境下的交通场景。
其次,要增强驾驶员的注意力模型。
即进一步地研究驾驶员注意力的模拟机制,探索如何更加精确地预测和模拟人类驾驶员的注意焦点,以及探究这些焦点对于驾驶决策的影响。
再次,要开展安全性和鲁棒性的验证。
即将现有模型部署到物理世界的小车中,通过更多的物理实验,验证模型在真实世界条件下的性能。
从而将研究扩展到恶劣天气、夜间驾驶等更广泛、更多样的驾驶场景和环境条件之中,借此验证和提高系统的通用性和适应性。
最后,要开展人机交互的研究。
即探索如何将这一技术与人机交互更紧密地结合,例如通过提供给驾驶员更直观的风险警告和辅助决策支持,增强自动驾驶车辆与人类驾驶员之间的互动。
通过这些后续研究计划,徐冬阳希望不仅可以提升自动驾驶技术的性能,也能确保其更加贴近人类驾驶行为的理解,为实现更安全、更智能的自动驾驶技术打下基础。
参考资料:
1.https://arxiv.org/pdf/2403.12552.pdf
运营/排版:何晨龙
发布于:北京
相关推荐
科学家研发自动驾驶新模块,让自动驾驶场景理解更接近人类认知
L5级自动驾驶为何这么难做,“特斯拉”路线可行吗?
自动驾驶L2来了,它会让驾驶更轻松吗?
最前线 | 特斯拉CEO马斯克:有信心今年实现L5自动驾驶,正建立中国自动驾驶团队
研发L4级自动驾驶全栈解决方案,「元戎启行」与东风合作Robo-Taxi
专访CMU Argo Lab首席科学家John Dolan:自动驾驶的技术攻坚在“最后5%”的长尾问题,L5级自动驾驶仍然遥远
让机器更“懂”人类(新职·新知③)
自动驾驶汽车真的比人类驾驶汽车更安全吗?
瞄准短途物流和环卫等限定场景,「驰知科技」研发L4级自动驾驶整体解决方案与核心控制模块
潮科技 | 认知计算:“机器认知”与“人类认知”的碰撞
网址: 科学家研发自动驾驶新模块,让自动驾驶场景理解更接近人类认知 http://m.xishuta.com/newsview114777.html