单手解魔方效果惊艳,OpenAI发布最强机器手
编者按:本文来自微信公众号“图灵TOPIA”,来源 OpenAI,编译 刘静、闫娜,36氪经授权发布。
我们见识过人类花式解魔方~

也见过颜值略低的机器人解魔方~

但是机器人单手解魔方你见过吗?
近日,OpenAI的研究人员就训练了一对神经网络,可以让机器人单手解魔方,效果极其惊艳!

使用与OpenAI Five相同的强化学习代码,搭配一种称为自动域随机化(ADR)的新技术,对神经网络进行全面的模拟训练,该系统可以处理训练中从未见过的情况。
研究人员通过此次实践表明强化学习不仅是虚拟任务的工具,而且可以解决需要前所未有的灵活性的物理世界问题。
人类的双手使我们能够解决各种各样的任务。在过去60年的机器人技术中,人类用可以固定的双手完成艰巨的任务,而对于机器人来说,却需要为每个任务设计一个定制的机器人。
作为替代方案,大家花了数十年的时间尝试使用通用机器人硬件,但由于自由度高,取得的成功有限。
自2017年5月以来,OpenAI的研究人员一直在尝试训练像人一样的机器人手来解决魔方问题。之所以设定这个目标,是因为他们相信,成功地训练这样一只机械手来完成复杂的操作任务,会为通用型机器人奠定了基础。
单手解魔方的任务即使对人类来说也是一项艰巨的任务,而且一般儿童需要数年的时间才能掌握所需要的灵巧性。不过,OpenAI的机器人技术并非完美,因为解出魔方的概率是60%。(最大难度的只有20%的成功率)。
怎么实现的?
机器目前难以掌握的问题:感知和灵巧操纵。
因此,研究人员训练神经网络以实现所需的面旋转和由Kociemba算法生成的立方体翻转。
域随机数据生成使仅在模拟中训练的网络可以迁移到真实的机器人上。
域随机数据生成使神经网络暴露于同一问题的许多不同变体,在这种情况下解魔方面临的最大挑战是在模拟环境中创建足以捕获现实世界物理特征的环境。
对于像魔方或机械手这样复杂的物体,很难测量和建模诸如摩擦,弹性和动力学之类的因素,仅仅依靠域随机数据生成是不够的。
为了克服这个问题,研究人员开发了一种称为自动域随机化(ADR)的新方法,该方法会在模拟中不断产生越来越困难的环境。
该工作与POET紧密相关,POET自动生成2D环境。但是,该工作学习了针对所有环境的联合策略,此策略可以转移到任何新生成的环境。
这使其摆脱了对真实世界的精确模型的束缚,并使在模拟中学习到的迁移神经网络能够应用于真实世界。
ADR从单一的非随机环境开始,在该环境中,神经网络学习了如何解魔方。随着神经网络性能的提高和性能阈值的增大,域随机化的数量会自动增加。由于神经网络现在必须学会将其推广到更随机的环境,因此这使任务更加艰巨。网络不断学习,直到再次超过性能阈值,然后再进行更多随机化,然后重复该过程。
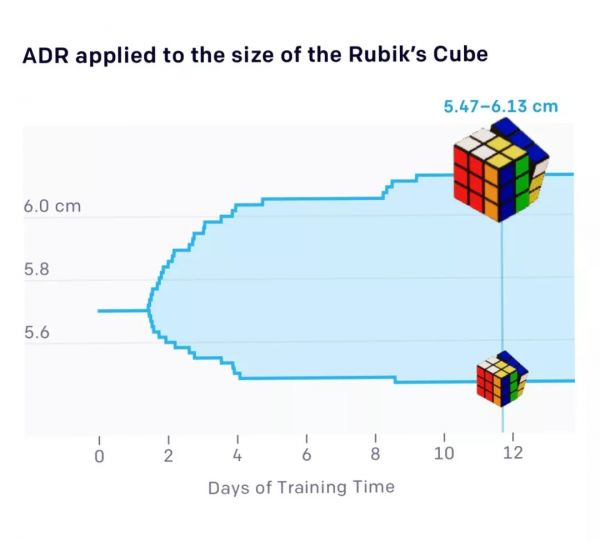
研究人员随机化的参数之一是魔方的尺寸(上图)。ADR从固定大小的魔方开始,然后随着训练的进行逐渐增加随机范围。我们将相同的技术应用于所有其他参数,例如立方体的质量,机器人手指的摩擦力和手的视觉表面材料。因此,神经网络必须学会在所有这些越来越困难的条件下解魔方。

域随机化数据要求手动指定随机化范围,这是困难的,因为太多的随机化会使学习变得困难,但是太少的随机化则会阻碍向真实机器人迁移。ADR通过自动扩展随机范围来解决此问题,而无需人工干预。ADR消除了对领域知识的需求,并使将该方法应用于新任务更加简单。与手动域随机化相比,ADR还使任务始终具有挑战性,而训练却从未收敛。
在块翻转任务上,将ADR与手动域随机化进行比较,而该任务已经有了很强的基线。在一开始,ADR在真实机器人上的成功次数方面表现较差。但是随着ADR增大熵(这是对环境复杂性的度量),迁移性能表现最终将在基线上翻倍,而无需人工调整。
鲁棒性测试
利用ADR,可以在模拟环境中训练神经网络来解机器人手上的魔方。这是因为ADR将网络暴露于无穷无尽的随机模拟中。正是训练过程中的复杂性,网络才得以从模拟世界迁移到现实世界,因为它必须学会快速识别并适应面对的任何物理世界。
为了测试方法的局限性,研究者在手解魔方的同时做了各种各样的扰动实验。这不仅测试了控制网络的鲁棒性,也测试了视觉网络,可以用它来估计立方体的位置和方向。
用ADR训练的系统对扰动的鲁棒性令人惊讶,尽管从未用ADR训练过:在所有测试的扰动下,机器人都能成功地完成大多数翻转和旋转,尽管不是在最佳性能下。
Emergent meta-learning
研究者认为,元学习或学会学习,是构建通用系统的一个重要前提,因为它使它们能够快速适应环境中不断变化的条件。ADR背后的假设是,一个记忆增强网络与一个充分随机化的环境相结合,导致Emergent meta-learning,其中网络实现了一个学习算法,该算法可使其自身迅速适应其所部署的环境。
为了系统地测试,研究者测量了神经网络在不同的扰动下(如重新设置网络的内存、重新设置动态)每次立方体翻转(旋转立方体使不同颜色的面朝上)成功的时间。在模拟中进行这些实验,这使研究者能够在一个受控的环境中进行超过10,000次的平均性能测试。
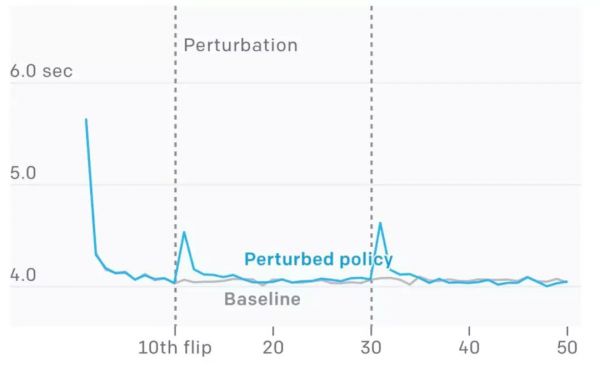
一开始,随着神经网络成功地实现了更多翻转,每一次成功翻转所用的时间都在缩短,因为神经网络学会了适应。当施加扰动时(上图中垂直的灰色线条),可以看到成功的时间是一个峰值。
这是因为网络采用的策略在变化的环境中不起作用。然后,网络重新学习新的环境,再次看到成功的时间减少到了以前的基线。
研究者还测量了失效概率,并对面旋转(顺时针或逆时针旋转上表面90度)进行了相同的实验,发现了相同的适应模式。
理解该神经网络
可视化的网络使研究者能够理解它们在内存中存储的内容。随着网络变得越来越复杂,这一点变得越来越重要。
神经网络的记忆在上面是可视化的。使用可解释性工具箱中的一个构件——非负矩阵分解,将这个高维向量压缩成6组,并为每组分配一个独特的颜色。然后在每个步长中显示当前主导组的颜色。
研究者发现每个内存组都有与其相关的语义上有意义的行为。例如,我们可以通过观察网络内存的主导组来判断它是要旋转立方体还是在它发生之前顺时针旋转顶部。
挑战
用机械手解魔方仍然不容易。当面对最大困难的扰乱操作时,需要26个面的旋转,成功率为20%。对于需要15次旋转才能撤销最简单的打乱操作,成功率为60%。当魔方掉落或超时时,认为尝试失败。
然而,研究者的网络可以从任何初始条件解魔方。所以如果魔方掉了,可以把它放回手里继续解下去。
通常发现,神经网络更有可能在前几个面旋转和翻转过程中失败。之所以如此,是因为在早期的旋转和翻转过程中,神经网络需要在解决魔方和适应物理世界之间取得平衡。
参考链接:
https://openai.com/blog/solving-rubiks-cube/
论文:
https://d4mucfpksywv.cloudfront.net/papers/solving-rubiks-cube.pdf
相关推荐
单手解魔方效果惊艳,OpenAI发布最强机器手
OpenAI“单手解魔方”被公开质疑,Gary Marcus称七大问题涉嫌误导
离开马斯克的OpenAI终踏上商业化之路
那些惊艳的新技术,关乎机器,更关乎人
MIT万字报道:竞争压力裹挟下的OpenAI,理想如何安置?
苹果挖走谷歌大牛Ian Goodfellow,负责苹果“特殊项目”机器学习
秒杀Dota2世界冠军后,OpenAI公开摆擂碾压人类
人类彻底失守!OpenAI 2:0横扫冠军战队OG
马斯克走后OpenAI大变天!成立营利公司,回报限制在100倍
再创融资纪录,微软给了OpenAI十亿美元,研发超能AI
网址: 单手解魔方效果惊艳,OpenAI发布最强机器手 http://m.xishuta.com/newsview11283.html