那些挑战Transformer的模型架构都在做些什么?
2017年的时候谷歌发表了一篇论文,标题是《Attention Is All You Need》,翻译成中文是“你需要的只是关注”。隐藏在这个看似不明所以的标题下的,是造就了ChatGPT、Gemini等多种大语言模型的Transformer模型。论文里提出了划时代的“自注意力”机制(Self-Attention Mechanism),允许模型在处理一个元素(如一个词)时,同时考虑序列中的其他元素,从而更好地理解上下文,这个机制通过计算每个元素对其他元素的“注意力分数”来实现。
与此同时,Transformer模型也有比较明显的缺点:Transformer模型的自注意力机制在处理长序列时具有二次方的时间和空间复杂度。这意味着随着输入序列长度的增加,所需的计算资源和时间成指数级增长。而且由于其大量的参数和复杂的层间交互,Transformer模型在训练和推理时还需要大量的内存。Transformer比传统的递归神经网络(RNN)在处理长距离依赖方面更有效,但在非常长的序列中处理长期依赖关系仍然是一个挑战。
那怎么办呢?Transformer这么厉害的模型,放在那里不用,岂不是暴殄天物吗?于是开发者们就想尽办法,就像Transformer的另一个翻译“变形金刚”一样,开发者们调整Transformer模型,衍生出了多个变体,以提高最终的性能。比如刚才说的ChatGPT,就是Transformer的变体——生成式预训练变压器(generative pre-trained Transformer),还有谷歌的BERT(bidirectional encoder representations from Transformers)等等。
一、盘古π
华为在2023年的末尾也发表了他们的“变形金刚”——盘古π。该算法旨在通过增强快捷方式来解决Transformer架构中的特征塌陷问题,提高模型处理视觉特征的多样性和效率。算法采用并行的增强快捷连接和参数化的投影,以丰富特征表示和提高特征多样性。算法通过线性投影和非线性激活函数的组合,处理每个令牌并保留其特异性,同时与MSA模块的功能互补。
从原理上来解释,盘古π其实有两部分组成:第一部分是论文提出的一种序列信息激活函数,以增强MLP(多层感知器)模块的非线性。第二部分是,增强快捷方式以改进Transformer架构中的多头自注意力(MSA)模块。
逐一来展开一哈,看看这个合体金刚到底是什么来头。激活函数这个概念不稀奇,很早就有了,它在神经网络的每个节点中都有应用,以引入非线性变换。激活函数的作用是决定神经元是否应该被激活,即输出信号的强度。它们对输入信号进行一定的数学处理,然后输出到网络的下一层。就跟生物神经信号差不多,有个知名度很高的医学实验,就是用电去刺激蛤蟆的腿,这会导致蛤蟆坐立起身,原理就来自于生物神经信号一层一层地激活传递。
蛙腿实验
可是激活函数本来是非可学习的,论文中则提出了一种技术,定义可学习的激活函数ϕi,并将其应用于MLP的所有隐藏层。那么结果就是改进神经网络的非线性可以通过增加非线性激活层的数量或增强每个激活层的非线性来实现。直白点说就是更聪明了。
接着来说第二部分,纯粹的注意力机制可能遭受特征塌陷问题。典型的大型语言模型(LLM)架构为每个多头自注意力(MSA)模块只配备了一个简单的快捷连接,即身份投影,直接将输入特征复制到输出。这种简单的公式可能无法最大化地提升特征多样性。
盘古π则是提供更多绕过注意力机制的替代路径。论文用不同于直接复制输入token到对应输出的身份投影,参数化投影将输入特征转换到另一个特征空间。只要它们的权重矩阵不同,投影就会对输入特征应用不同的转换,因此并行更多增强快捷方式有潜力丰富特征空间。算法采用并行的增强快捷连接和参数化的投影,以丰富特征表示和提高特征多样性。旨在通过增强快捷方式来解决Transformer架构中的特征塌陷问题,提高模型处理视觉特征的多样性和效率。
将盘古π与最先进的LLMs进行比较。结果表明,盘古π在70亿参数这个量级可以实现与基准相当的性能,推理速度提升约10%,而盘古π在10亿参数这个量级的准确性和效率方面可以实现最先进的性能。
此外,根据华为实验室的说法,已经在金融和法律等高价值领域部署了70亿参数级别的盘古π,开发了名为云山的LLM进行实际应用。论文显示,云山可以在基准测试上超越其他类似规模的模型。
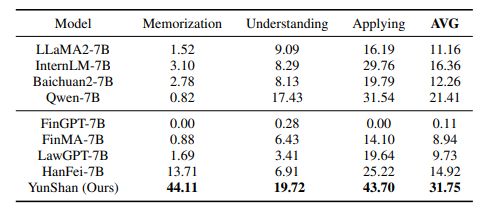
云山和其他模型的性能比较
二、RWKV
2023年5月左右,同样作为Transformer的一个变体,RWKV模型诞生了。RWKV在理念上和盘古π很像,它也是合体金刚,只不过走得更像是“头领战士”那套玩法,代表人物是巨无霸福特。
RWKV结合了Transformer的高效可并行训练和RNN的高效推理能力。RWKV在处理长序列时克服了Transformer的二次方计算复杂性,同时保持了RNN的线性记忆和计算需求。利用线性注意力机制,相比于传统Transformer的二次方复杂度,它在处理长序列数据时的内存和计算需求是线性增长的。RWKV另一大特点是灵活,因为包含RNN形式,所以可以实现训练过程中的计算并行化,同时在推理时保持恒定的计算和内存复杂度。正是这个原因,让我认为RWKV属于头领战士,战斗的时候与巨大身躯结合,体型变大战斗力变强,平时则只保留头部,便于行动。
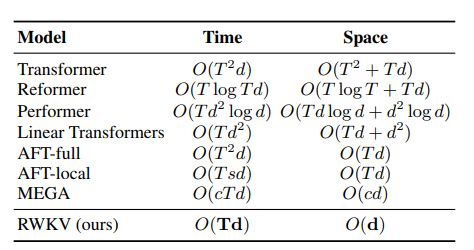
不同模型推理随复杂度与时间的关系
尽管RWKV提高了效率,但是会牺牲一定的性能,特别是在复杂的NLP任务中,其精确度和泛化能力可能与传统的Transformer模型有差距。RWKV几乎没有非线性能力,可是非线性是神经网络学习复杂函数的关键。所以RWKV模型目前仅能扩展到14亿参数,当参数级别进一步增大,RWKV的表现就差点意思了。
说句题外话,RWKV的论文叫做《Reinventing RNNs for the Transformer Era》。翻译过来是“在Transformer时代重铸RNN荣光”,没错,这句话正是英雄联盟S10上,许秀的那句“重铸LCK荣光,我辈义不容辞”的英文版。
三、Another one
其实从Transformer论文诞生的那一秒开始,就有无数的挑战者觊觎大语言模型的宝座。比如RoBERTa(Robustly Optimized BERT Approach),它是上文提到的,Transformer变体之一BERT的再变体。从功能上来说,RoBERTa属于是BERT的优化版本,通过更大的数据集和更长时间的训练,以提高性能。
在2023年的最后一天,MosaicBERT诞生了。通过将FlashAttention、带线性偏置的注意力(ALiBi)、门控线性单元(GLU)、动态去除填充令牌的模块,以及低精度LayerNorm统统塞进Transformer模型中。再使用30%的遮蔽率(masking ratio)进行掩码语言建模(MLM),并且采用bfloat16精度和为GPU吞吐量优化的词汇表大小,最后把RoBERTa的一些优点也给融进去了。可以理解成帕奇维克,或者嵌合超载龙那样的存在。
还有一个有趣的事情,在Transformer众多挑战者中,中国团队的数量是非常多的,而且中国团队的作品主打一个字:实用。基本围绕70亿参数做展开,这个级别实用价值是最高的,几乎涵盖了所有行业的专业知识,一定程度上满足使用需求。其次是围绕10亿级别展开,这个级别技巧性确实很强,但是实用价值远不如70亿级别。这些模型架构似乎有一种从最终场景出发的设计思路,它们挑战着Transformer,也给模型的进一步进化带来着其他可能性。
本文来自微信公众号:硅星人Pro(ID:Si-Planet),作者:苗正
相关推荐
那些挑战Transformer的模型架构都在做些什么?
OpenAI首席科学家最新访谈:对模型创业两点建议、安全与对齐、Transformer够好吗?
谷歌大脑的Transformer论文,“翻车”了
Transformer诞生六周年:在它之后世界地覆天翻
AGI的大时代,我们可以做些什么?
Transformer六周年:在它之前世界平淡,在它之后世界地覆天翻
Transformer能解释一切吗?
大模型套壳祛魅
对话Arm高级副总裁:AI大模型带来“计算”新挑战,架构灵活性、生态
苹果这篇“魔改”闪存的论文,暴露了它的大模型野心
网址: 那些挑战Transformer的模型架构都在做些什么? http://m.xishuta.com/newsview104102.html