用起来少费电的模型,可能比GPT-5更重要
训练一个大模型,费算力、费电力、费数据。而且,大模型越先进,越费电。
推理更费电。
下面这张图,说的是大模型在推理阶段的能耗。生成类任务比分类任务产生更多排放,多任务比单任务产生更多排放,生成图像比生成语言产生更多排放。二氧化碳排放的原因是能耗。
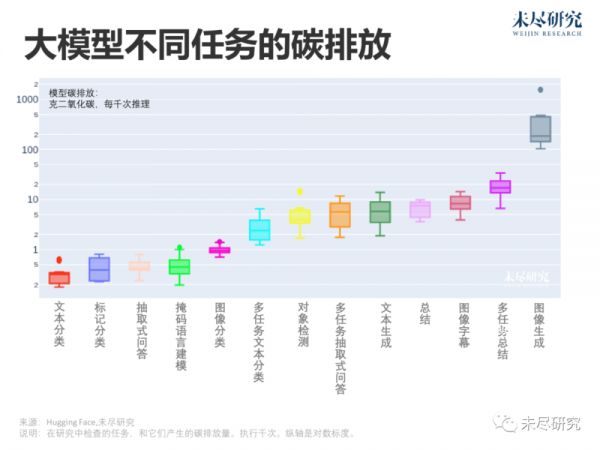
之前有不少研究大模型训练阶段能耗与排放的,但研究大模型全生命周期阶段排放的并不多。
Hugging Face的Alexandra Sasha 和 Yacine Jernite , 以及卡内基梅隆大学和艾伦AI研究所的Emma Strubell,研究了大模型在推理阶段所产生的二氧化碳排放。
他们在5种不同的模态中选择了十个机器学习任务,这些在自然语言处理和计算机视觉中都很常见:
文本到类别(文本分类、标记分类、抽取式问答);
文本到文本(掩码语言建模、文本生成、总结);
图像到类别(图像分类、对象检测);
图像到文本(图像字幕)和文本到图像(图像生成)。
为了代表广泛的部署用例多样性,他们抽样了88个模型,其中一些是专门为选择的任务训练或微调的,其他则是设计为零样本或多任务模型的,以比较给定任务的不同架构,并比较同一架构的不同任务。
对于每个模型,他们对其训练的任务的3个数据集中的每一个运行了1000次推理,使用Transformers 库。
他们从Flan-T5大模型家族 中选择了4个不同大小的序列到序列模型(基础、大型、超大型和超超大型),还选择了BLOOMz大模型家族中的4个解码器模型:BLOOMz-560M、BLOOMz-1B、BLOOMz-3B 和 BLOOMz-7B。
这些实验都是在亚马逊网络服务上托管的单个NVIDIA A100-SXM4-80GB GPU上运行的,并使用Code Carbon包来测量推理期间消耗的能量和排放的碳。
所有的实验都是在同一个计算区域运行的,位于美国俄勒冈州,平均碳强度为每千万时297.6克二氧化碳。这项研究和评估本身总共耗费了754.66千瓦时的能量,并排放了178.97千克的二氧化碳。
下面是更详细的结果:
从这张图可以看出,大型的、多模态的模型,产生更多的排放。
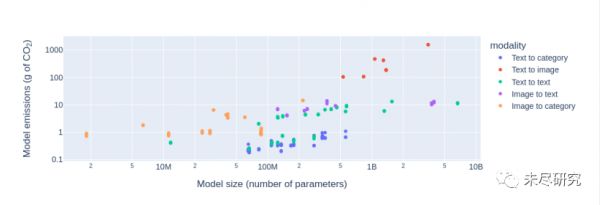
(说明:模态:文分类,文生图,文生文,图生文,图分类。纵轴:模型排放,(克二氧化碳/千次推理)横轴:模型尺寸(参数量)注:坐标进行了对数处理 )
从这张图可以看出,多任务的模型比具体任务的模型产生更多的排放。
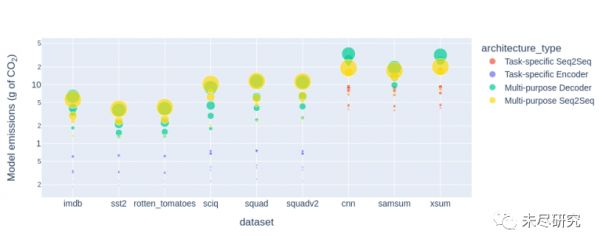
说明:架构类型,具体任务Seq2Seq,具体任务编码,多任务解码,多任务Seq2Seq
纵轴:模型排放(克二氧化碳)。横轴:数据集
值得注意的是,当模型变得更大,以追求智能的涌现、能力的泛化,不仅碳排放总量增加了,而且碳排放强度也增加了。所以,在当前的算法结构下,如果说智能涌现仍然基本上不可解释,而只是一个实证的结果的话,那么最简单的实证因果就是:智能来自更多的能源。
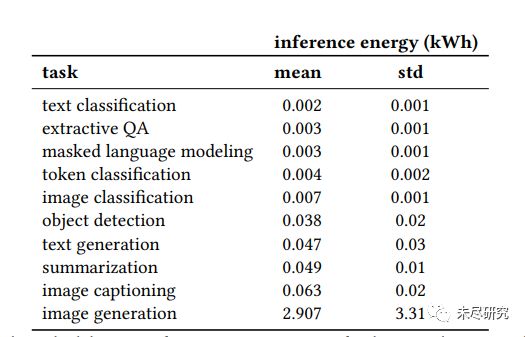
这张表格显示的是每进行1000次查询,完成每种推理任务平均消耗的能源(及其统计标准方差)。可以看到,图片生成所带来的能耗强度,是文本分类的近1500倍。
再看下这张图,它展示了BLOOMz系列4个不同尺寸模型,在训练、精调阶段的能耗,每次推理需要的能耗及产生的排放。最后是成本平价,即需要多少次推理累积,才能达到训练阶段的能耗总量。

显然,同一个模型家族,尺寸越大,不仅能耗及排放的总量越大,而且强度越大。如700亿参数模型的能耗强度,是5.6亿能耗强度的近两倍。
作者用来测试的都是开源模型。一般来说开源模型的技术报告会披露模型训练时的碳足迹,但不会披露推理产生的碳足迹。
从GPT-3之后,模型的规模越来越大,日益多任务和多模态,更多面向用户的应用开发出来,而且推理的实时性越来越强,所有这些,都意味着在通用人工智能的道路上走得越远,消耗的能源越多,产生的碳排放越多。这些环境成本应该考虑在内。
生成式人工智能正在经历一次范式转变:从为特定任务微调的小型模型转向旨在同时执行多项任务的大模型,以实时响应用户的大量查询。自从GPT-3出现以来,这种转变不仅在机器学习研究中发生,展示了语言模型在少样本和零样本学习上的潜力,而且在消费者设置中也在发生,诸如GPT-4和PaLM这样的大型语言模型被部署在面向用户的产品中,如网页搜索、电子邮件和导航,在这些领域之前通常使用的是像BERT这样的特定任务的小型模型版本。
由于闭源的商业大模型在产品的参数数量、架构和碳排放方面缺乏透明度,很难量化其环境影响,但是不妨用该研究的实验进行比较。
例如,按1000次查询来算,为抽取式问答任务(类似于抽取式网络搜索)微调的基于BERT的模型的平均排放量为0.70克二氧化碳,这不及多用途模型排放量少的三分之一(Flan-T5 为2.36克,BLOOMz-560M为2.34克)。如果将基于BERT的模型与更大的多用途模型进行比较,差异更为显著:例如多语种的情感分析模型只排放0.32克二氧化碳,相比之下Flan-T5-XL为2.66克,BLOOMz-7B为4.67克。
对比来看,2022年发布的第一个PaLM模型有5400亿个参数,而GPT-3有1750亿个参数,2023年发布的GPT-4的参数超过了万亿,可以想象其碳排放强度会有多大。虽然生成型零样本模型能够执行多个任务,但是在一些任务明确定义的情境中,例如网页搜索和导航,如果能耗那么大,是否一定有必要部署这些大模型?杀鸡焉用宰牛刀。
由此可以看出,虽然更大的模型涌现出更多的智能,但是在GPT-4之后,继续扩大模型,在训练和推理的阶段,都会带来能耗的指数型增长,智能的涌现是否超过能耗的涌现,综合成本收益是否划算,是需要考虑的一个问题。
因此,从能耗的角度来看,结合具体的使用场景,训练和精调小型的开源模型,在具体能力上不输闭源大模型,应该是一个趋势。这样就可以有更多模型部署到边缘侧和设备终端,让推理更有效率。让数据中心用上清洁电力,虽然无助于电力成本,但可以减少排放。
关于大模型在训练阶段的碳排放,可以参见我们之前发表的文章:《GPT有多耗电,微软不说,谷歌暗踩》。
2024年,用更少的能耗训练出合适的模型,让更多人以更低的推理成本使用,其重要性应该不亚于训练出GPT-5。
参考论文:
Power Hungry Processing: Watts Driving the Cost of AI Deployment? 2023年11月
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究
相关推荐
用起来少费电的模型,可能比GPT-5更重要
GPT-5将于第4季推出 据悉将实现“通用人工智能” 或更接近人类思维
大模型人才高度稀缺,“选择”比“培养”更重要?
ChatGPT之父首次公开表态:GPT-5根本不存在
比尔·盖茨:GPT-5不会比GPT-4好多少
“马斯克们”叫停GPT-5,更像是场行为艺术
OpenAI称短期内不会训练GPT-5,马斯克TruthGPT曝光
「ChatGPT之母」最新采访:GPT-4离超级智能还很远,半年内不会训练GPT-5
开源大模型领域最重要的玩家们,在关心/担心什么
GPT-5要来了!OpenAI在中国申请GPT5商标OpenAI申请GPT5商标
网址: 用起来少费电的模型,可能比GPT-5更重要 http://m.xishuta.com/newsview101155.html